
西瓜書第二章筆記
概念
錯誤率(error rate):分類錯誤的樣本數佔樣本總數的比例
精度(accuracy):精度 = 1 - 錯誤率
誤差(error):學習器的實際預測輸出與樣本的真實輸出之間的差異
訓練誤差(training error)/經驗誤差(empirical error):學習器在訓練集上的誤差
泛化誤差(generalization error):學習器在新樣本上的誤差
過擬合(overfitting):學習器把訓練樣本自身的一些特點當作了所有潛在樣本都會具有的一般性質,導致泛化效能下降
欠擬合(underfitting):學習器對訓練樣本的一般性質尚未學好
評估方法
如果我們還有一個包含m個樣例的資料集D={(x1,y1),(x2,y2),...,(xm,ym)},既要訓練,又要測試,就需要通過對D進行適當的處理,從中產生出訓練集S和測試集T。
1,留出法 (hold-out)
2,交叉驗證法(cross validation)
3,自助法 (bootstrapping)
效能度量(performance measure):衡量模型泛化能力的評價標準。
概念 查準率、查全率與F1:
查準率(precision):檢索出來的條目中準確的佔比
查全率(recall):所有準確的條目檢索出來的佔比
查準率和查全率是一對矛盾的度量.一般來說,查準率高時,查全率往往
偏低
平衡點(Break-Even Point,簡稱BEP):為了在PR圖中識別學習器的效能誰更優異,人們設計了一些綜合考慮查準率、查全率的效能度量。平衡點就是其中之一,它是查準率=查全率時的取值。平衡點的取值越大,學習器越優。

ROC 與 AUC
ROC全稱是“受試者工作特徵(Receiver Operating Characteristic)”曲線。根據學習器的預測結果對樣例進行排序,按此順序逐個把樣本作為正例進行預測,每次計算出兩個重要量的值,分別以它們的橫、縱座標作圖,就得到了ROC曲線。ROC曲線的縱軸是“真正例率(True Positive Rate,簡稱TPR)”,橫軸是“假正例率(False Positive Rate,簡稱FPR)”,兩者分別定義為:
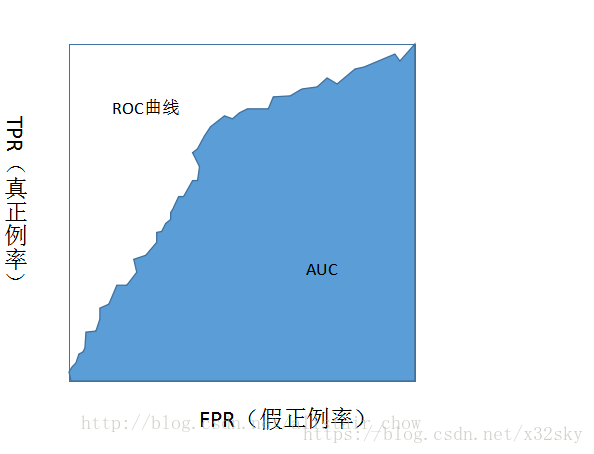
其中AUC(Area Under ROC Curve)為ROC曲線下所包含的面積,用於判斷學習器間的效能誰更優。
偏差與方差
偏差-方差分解(bias-variance decomposition)是解釋學習演算法泛化效能的一種重要工具。
偏差-方差分解試圖對學習演算法的期望泛化錯誤率進行拆解。
泛化誤差可分解為偏差、方差與噪聲之和。
偏差度量了學習演算法的期望預測與真實結果的偏離程度,即刻畫了學習演算法本身的擬合能力
方差度量了同樣大小的訓練集的變動所導致的學習效能的變化,即刻畫了資料擾動所造成的影響
噪聲表達了在當前任務上任何學習演算法所能達到的期望泛化誤差的下界,即刻畫了學習問題本身的難度