
機器學習(西瓜書)學習筆記(二)---------線性模型
1、基本形式
對含有d個特徵的資料x,線性模型試圖學得一個通過特徵的線性組合來進行預測的函式:
f(x) = w1x1 + w2x2 + .......wdxd + b
一般用向量形式寫成:
f(x) = w^T x + b
線性模型得以對每個不同的特徵進行權重考量,它形式簡單,易於建模,雖然對於大多數複雜問題來說線性模型效果不好,但它卻是很多複雜模型的基礎;
2、線性迴歸
首先考慮最簡單的情況,樣本只有一個屬性,這時是單個特徵的線性迴歸。
2.1 單元線性迴歸
第一步:特徵值連續化
因為建模需要運用數字進行計算,對於特徵值是數字的可以直接使用,然而,對於特徵值不是數字的則無法進行建模運算(例如形容一個人的特徵為高矮胖瘦時,不對其進行數字化則無法建模運算),此時需要將其轉化後方可進行建模。
對於特徵值的離散屬性,如果其屬性有“序”,可通過連續化將其轉化為連續值;如身高屬性的取值“高”、“矮”可轉化為{1.0,0.0},“高”、“中”、“低”可轉化為{1.0,0.5,0.0};如果屬性值之間不存在“序”關係,通常會根據屬性值的個數(如k個)進行k維向量化,(0,0,1),(0,1,0),(1,0,0)。
第二步:確定迴歸模型
線性迴歸試圖學得:
顯然,模型的關鍵在於得到一個最好的w和b使得f(x) 儘可能的減少與yi之間的誤差,問題化簡為求(yi-f(x))^2 的最小值問題:
的最小值。
由函式的凹凸性可知,對於凸函式,當其倒數為0時能取得最小值,故對w、b進行求導:
令其為0即可求得w、b的值:
其中
推導過程比較簡單,這裡就不演示了。
2.2 多元線性迴歸
上面討論的是樣本只有一個屬性的情況,擴充套件到多維屬性上時,比如一個數據集裡面的樣本由d個屬性描述時,我們試圖讓模型學得如下回歸函式:
使得
同樣用最小二乘法來對w和b進行估計,由於此時擴充套件到d維屬性,這裡用矩陣的形式來便於討論。
w、b用向量的形式表示 ;
將資料集D表示為一個 m行(d+1)列大小的矩陣
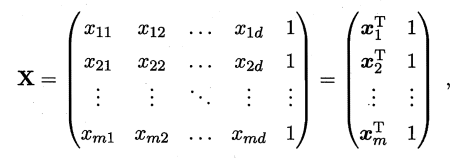 說明:m行表示資料集有m個,d+1列表示前d個特徵值和修正量b的對應值。
說明:m行表示資料集有m個,d+1列表示前d個特徵值和修正量b的對應值。
將實際值y也寫成向量的形式: ;
求誤差的最小值:
對求導得:
令上式為0即可得到最優解:
此時要注意,當為滿秩矩陣或正定矩陣時,解唯一:
當
不是滿秩矩陣時(實際情況往往是這樣),此時解不唯一,會得到多組滿足條件的最優解,至於選哪個作為輸出,將由學習演算法的歸納偏好(筆記一中提到的)決定,通常會引入正則化。
線性模型雖然簡單,但卻有多種形式的變形,比如 雖然看上去還是線性模型,但實際上它已經是對數函式的一種對映,這就是”對數線性迴歸“。
更一般地,對於單調可微函式g(·),令 , 則
"廣義線性模型”
2.3 對數機率迴歸
說是迴歸,其實解決的是分類問題;因為使用了階躍函式,使得對不同的分類x總有唯一的y值對應,比如x > 0時,y取值為1 ,x < 0時,y取值為0。之所以還是將其稱為迴歸函式,主要是它還是使用了廣義的線性模型。但是,普通的階躍函式是不連續的,不滿足廣義線性模型中g(·)單調可微的條件,因此,我們希望找到一個“替代函式”近似階躍函式並且單調可微,而對數機率函式正好滿足要求:
將其作為帶入廣義線性模型中得到:
按照廣義線性模型的樣式,上式可轉化為:(轉化過程自行推導,就是簡單的列式轉換)
從上式可以看出,實際上是在用線性迴歸模型的預測結果去逼近真實標記的對數機率。
此時對於w、和b的求解 可以先通過最大似然法來估計,然後利用梯度下降法或牛頓法來求其最優解。
2.4 線性判別分析
線性判別分析(LDA)是一種經典的處理二分類問題的方法,也可以稱為“Fisher判別分析”,但是嚴格說來,LDA假設了各類樣本的協方差矩陣相同且滿秩,因此,兩者還是有一些區別的。
主要思想:通過給定的訓練資料來找到一條直線使得訓練資料中不同分類裡面的點投影到該直線上時儘可能的接近,而不屬於該類的點在直線上的投影儘可能的遠離;最後,通過訓練好的該模型,只需給定一個點就能判斷它屬於哪一類。
LDA可用於二分類也可用於多分類,由於使用的是投影的方式,從而可以降低樣本的維數,而且投影過程中使用了類別資訊,因此LDA也常被視為一種經典的監督降維技術。
2.5 多分類學習
有些二分類學習方法可以直接推廣到多分類,這裡我們主要是使用二分類學習器來解決多分類問題。
考慮N個類別C1,C2,…,CN這裡我們將N分類問題拆解若干個二分類問題進行求解。
一對一分類(One vs One, OvO):將N個類別兩兩配對,產生N(N−1)/2個分類任務,測試時將新樣本輸入給所有分類器,選擇預測結果最多的類別作為最終分類結果。
一對其餘分類(One vs Rest, OvR):每次將一個類別的樣本作為正類,其餘所有類別的樣本作為負類,構建N個分類器。同樣將測試樣本輸入到所有分類器中,若只有一個分類器預測為正類,則對應的類別作為最終分類結果;若有多個分類器預測為正類,通常考慮各個分類器的預測置信度,選擇置信度最大的類別標記作為分類結果。
多分類 樣本數 分類器個數
OvO 兩類樣本 N(N−1)/2
OvR 所有樣本 N
OvO需要訓練N(N−1)/2分類器,而OvR只需訓練N個分類器,通常其儲存開銷和測試時間開銷更小;但OvR的每個分類器需要使用全部樣本資料,在類別很多時,訓練時間開銷通常更大。
2.6 類別不平衡問題
類別不平衡:分類任務中存在的不同類別(對於二分類就是正負類別)訓練樣本數量差別很大的情況。在這裡,我們假設對於二分類問題,正樣本數很少,負樣本數很多(比如廣告點選率),主要有以下三種處理辦法:
欠取樣:去除一些訓練集中的負樣本使得正負樣本數相當
過取樣:增加一些正樣本數使得正負樣本數相當
閾值移動:基於原始訓練集進行訓練,在用分類器判別時修改判決閾值
欠取樣:訓練集樣本數變少,訓練時間減少,可能會出現欠擬合。代表性演算法EasyEnsemble利用整合學習演算法,將負樣本劃分為若干個集合供不同的學習器使用。
過取樣:增加了很多正樣本,訓練集變大,可能會出現過擬合。代表性演算法SMOTE通過對正樣本進行插值來產生額外的正樣本。
閾值移動:在假設“訓練集是真實樣本總體的無偏估計”的前提下,我們基於訓練集中正負樣本的數目對判別器進行縮放。原來的判別閾值為0.5,即
若 , 則預測為正類
現在在訓練集中假設正樣本數為 ,負樣本數為
,則正樣本對於負樣本的觀測機率為
,在上述假設下,觀測機率代表了真實機率。所以只要分類器的預測機率高於觀測機率就應該判定為正類,即
若 , 則預測為正類
我們對於分類器的判別閾值進行縮放,令
即可。