
pragma pack對齊方式詳細介紹
為了加快讀寫資料的速度,編譯器採用資料對齊的方式來為每一個結構體分配空間。——寫在開頭
本文有自己的原創也有轉載的博文,轉載的部分一一列出來,可能不全請見諒這裡這裡這裡這裡等等。。。。。。
(更詳細的解說:
在用sizeof運算子求算某結構體所佔空間時,並不是簡單地將結構體中所有元素各自佔的空間相加,這裡涉及到記憶體位元組對齊的問題。從理論上講,對於任何 變數的訪問都可以從任何地址開始訪問,但是事實上不是如此,實際上訪問特定型別的變數只能在特定的地址訪問,這就需要各個變數在空間上按一定的規則排列, 而不是簡單地順序排列,這就是記憶體對齊。
記憶體對齊的原因:
1)某些平臺只能在特定的地址處訪問特定型別的資料;
2)提高存取資料的速度。比如有的平臺每次都是從偶地址處讀取資料,對於一個int型的變數,若從偶地址單元處存放,則只需一個讀取週期即可讀取該變數;但是若從奇地址單元處存放,則需要2個讀取週期讀取該變數。
win32平臺下的微軟C編譯器對齊策略:
1)結構體變數的首地址能夠被其最寬資料型別成員的大小整除。編譯器在為結構體變數開闢空間時,首先找到結構體中最寬的資料型別,然後尋找記憶體地址能被該資料型別大小整除的位置,這個位置作為結構體變數的首地址。而將最寬資料型別的大小作為對齊標準。
2)結構體每個成員相對結構體首地址的偏移量(offset)都是每個成員本身大小的整數倍,如有需要會在成員之間填充位元組。編譯器在為結構體成員開闢空 間時,首先檢查預開闢空間的地址相對於結構體首地址的偏移量是否為該成員大小的整數倍,若是,則存放該成員;若不是,則填充若干位元組,以達到整數倍的要 求。
3)結構體變數所佔空間的大小必定是最寬資料型別大小的整數倍。如有需要會在最後一個成員末尾填充若干位元組使得所佔空間大小是最寬資料型別大小的整數倍。
)在談pragma pack之前,必須先知道資料型別在記憶體中佔用的位元組數。16位32位64位系統佔用的位元組數都有不同。
16位編譯器
char :1個位元組
char*(即指標變數): 2個位元組
short int : 2個位元組
int: 2個位元組
unsigned int : 2個位元組
float: 4個位元組
double: 8個位元組
long: 4個位元組
long long: 8個位元組
unsigned long: 4個位元組
以在16位計算機中表示為例,基本資料型別加上修飾符有表1的描述。
|
表1 常用基本資料型別描述
32位編譯器
char :1個位元組
char*(即指標變數): 4個位元組(32位的定址空間是2^32, 即32個bit,也就是4個位元組。同理64位編譯器)
short int : 2個位元組
int: 4個位元組
unsigned int : 4個位元組
float: 4個位元組
double: 8個位元組
long: 4個位元組
long long: 8個位元組
long double: 8個位元組
unsigned long: 4個位元組
64位編譯器
char :1個位元組
char*(即指標變數): 8個位元組(64位的定址空間是2^64, 即64個bit,也就是8個位元組。)
short int : 2個位元組
int: 4個位元組
unsigned int : 4個位元組
float: 4個位元組
double: 8個位元組
long: 8個位元組
long long: 8個位元組
unsigned long: 8個位元組
---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
=====================================================分割線==========================================================================
---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
------------------------------------------------------
先看一個結構體的程式碼: //愛立信2011筆試 360 2011筆試均涉及
struct node{
int a;
int b;
};好的,上面那個答案確實是8,那麼再看下面這個結構體:
struct node{
char a;
int b;
};問:這個時候sizeof(Node)又是多少呢? int是4個位元組,char是1個位元組,答案是5?
這回,沒有那麼幸運,經過在機器上的操作,答案是8! Why?
實際上,這不是語言的問題,你在ANSI C中找不到為什麼會這樣!甚至你在不同的體系結構、不同的編譯器下會得到不同的答案。那麼,到底是誰把5改成了8呢?
這就引入了一個概念,叫做“記憶體對齊”。所謂的記憶體對齊,是指一種計算機體系結構(如X86)對基本資料型別的儲存位置有限制,要求其地址為某個數的倍數,通常這個數為4或8。這種要求會簡化處理器的設計以及提升資料訪問的效率。至於為什麼會有這樣的設計,簡單的說訪存匯流排的位數固定,以32位匯流排為例,地址匯流排的地址總是4對齊的,所以資料也四對齊的話,一個週期內就可以把資料讀出。這裡不理解的話可以跳過去,只要記得對齊這回事兒就行了。如果想更深入的理解,可以看這裡另一篇文章。
知道這個之後,那麼我們就可以理解,實際上是編譯器為了效率,在相鄰的變數之間放置了一些填充位元組來保證資料的對齊。X86結構是4對齊的,所以sizeof(Node)是8不是5。
再來看一個例子:
struct node{
int a;
char b;
char c;
int d;
char d;
};這時的sizeof(Node)是多少呢?沒錯,是16。
好的,既然我們知道對齊是由編譯器來作的,那麼我們可不可以更改對齊數呢? 答案是可以的,在C語言中,我們可以通過
#pragma pack(n)
來更改對齊模數。
注:以上都是在現x86 linux下使用gcc編譯器驗證,不乏有其他系統和編譯器會得到不同的結果。
再讓我們來看個例子:
struct node {
double a;
int b;
int c;
char d;
};這個時候的sizeof(node)是多少?20?24?
其實,這個時候你會發現,當你在windows上使用VC編譯的時候,你會得到24;當你在linux上使用gcc編譯的時候,你會得到20!其實,這恰好說明這種資料的對齊是由編譯器決定的!在VC中規定, 結構體變數的首地址能夠被其最寬基本型別成員的大小所整除;而在gcc中規定對齊模數最大隻能是4,也就是說,即使結構體中有double型別,對齊模數還是4,所以資料是按照1,2,4對齊的。所以,在兩個不同編譯器上,你得到了不同的答案!
--------------------------------------------------------------------------------------------------------------------------------------------------------------------------------熟悉c的人都知道,sizeof是一個關鍵字而不是一個巨集或者庫函式什麼的,他的值是在編譯時確定的,如果這個不瞭解,可以現看看這篇文章和這篇文章。 既然如此,讓我們先看下面幾個小例子:
sizeof(int);
sizeof(char);
sizeof(double);上面三行sizeof的值是多少呢?這裡我們假定在32位的x86系統下。我們會得到答案:4,1,8。這個沒什麼吧,大多數人都應該知道。那麼,下面這個:
sizeof(int);
sizeof(long);在32位x86下,這兩個是多少呢?4,8?
實際上,答案是4,4。我們需要注意,long型別在32位系統下是32位的。那麼,64位下結果又如何呢?8,8?其實答案是4,8。另一個需要注意的是,64位下的int是32位的。
上面只是熱熱身,現在,讓我們看sizeof的下面幾種情形:
1、sizeof一個結構體。
這個我就不說啥了,具體的參考這篇文章。至於空的結構體,下面會解釋。
2、sizeof陣列、指標等 先看下面兩個例子:
char a[100];
char b[100]="helloworld!";
char c[]="helloworld!";
char* d=b;
sizeof(a);
sizeof(b);
sizeof(c);
sizeof(d);在32位x86系統下,以上各是多少呢?
答案是:100,100,12,4。
為什麼不是100,12,12,12呢? sizeof一個數組名,返回的是陣列的大小,不管你數組裡面放的什麼資料。所以,第一個陣列大小是100,第二個陣列大小是100,第三個陣列大小是12(別忘記"\0")。第四個呢?第四個不是一個數組名,而是一個指標!32位下指標大小永遠是4,不管你是指向一個數組還是一個int還是一個char。 好,這個問題搞清楚之後,看下面這個程式:
int func(char a[100])
{
printf("%d\n", sizeof(a));
}
int main()
{
char *m = "helloworld!";
func(m);
char n[100]="helloworld!";
func(n);
}這個程式會打印出什麼結果呢?
答案是:4, 4。 為什麼結果都是4?不是應該返回陣列長度麼?
這裡出現又一個需要注意的地方:在作為引數傳遞的時候,陣列名會退化為指標。也就是說,這裡的func裡的引數,雖然看上去是個陣列名,但實際上還是個指標。 你瞭解了麼?下面是幾個練習,自己實驗下^_^
char *p = NULL;
sizeof(p);
sizeof(*p);
int a[100];
sizeof(a);
sizeof(a[100]);
sizeof(&a);
sizeof(&a[0]);懶得實驗?答案分別是4,1,400,4,4,4。為什麼?自己想想。
3、sizeof一些詭異的東西
(enum,空類,空struct) 所謂的詭異的東西,就是一些你想到的想不到的東西拿來sizeof。比如說sizeof一個enum型別是多少?一個空struct呢?一個空類呢? 這些詭異的東西在標準C中都沒有作出規定,很大程度上都是編譯器和系統結構相關的。 先來看一個:
這個你會得到什麼樣的結果呢?28? 在gcc或者vc下執行一把,你會得到答案:4。
為什麼呢? 實際上,enum具體有多大取決於編譯器的實現,目前大多數的編譯器都將其實現為int型別。也就是說這裡的enum被當作int型別(當然,使用上不一樣)。這不是一成不變的,有些編譯器,如VC++允許下面這種定義:
//注意這是個cpp檔案
enum Color : unsigned char
{
red, green, blue
};
// assert(sizeof(Color) == 1);enum先說到這裡,那麼一個空的結構體是多大呢? 如果你擅長C語言,你可以很快的寫出下面的程式:
//this is a *.c file
struct node{
}Node;
int main
{
printf("%d\n", sizeof(Node));
}很快,你可以驗證出來結果是0。 沒錯,這很好理解。但是,如果你用的是c++呢?
//this is a *.cpp file
struct node{
}Node;
class node2{
}Node2;
int main()
{
printf("%d\n", sizeof(Node));
printf("%d\n", sizeof(Node2));
}(不怎麼會寫c++的我表示壓力很大)以上這個c++的例子結果是多少呢?
為什麼會得到1,1這個結果呢? 換句話說就是為什麼sizeof一個空類和空結構體在c++下就是1呢?
這個原因要追朔到c++標準中的一句話:“no object shall have the same address in memory as any other variable”, 用中國話簡單點說就是:不同的物件之間應該有不同的地址(為什麼會有這樣的規定?看這裡)。
既然每個物件都必須有不同的地址,讓我們假設上面程式碼中的Node的size是0,想想會出現什麼樣的後果?
Node a;
Node b;a的大小是0,b的大小是0,那麼,a和b的地址是不是很可能重複了?
所以,為了保證不同的物件擁有不同的地址,最簡單的方法就是保證所有型別的大小都不是0。
所以,為了保證這點,大多數c++編譯器都會給空結構或類加上一個冗餘的位元組保證型別不為空。
我的解釋的清楚麼?如果我的表達能力不夠好,看這裡,解釋的足夠詳細。 當然,還有其他很多我沒有想到的詭異的東西可以拿來sizeof,如果你想到了,歡迎跟我分享。至於c++中的sizeof類,基類,派生類,足夠可以作為一個專門的文章了,先不再這裡說,等我學會C++的再寫一下相關內容(-_-")。
最後,給一個稍微給力點的程式,大家看看最終得到的結果是什麼(注意這是一個c++程式):
//this is a cpp file
typedef struct weekday_st
{
enum week {sun=123456789,mon,tue,wed,thu,fri,sat,a,b,c,d,e,f,g,h,i,j,k,l,m,n,o,p,q,r,s,t,u,v,w,x,y,z,aa,ab,ac,ad,ae,af,ag,ah,ai,aj,ak};
enum day{monring, moon, aftermoon};
}weekday_st;
int main(int argc, char *argv[])
{
printf( "sizeof(weekday_st)=%d\n ", sizeof(weekday_st));
printf( "sizeof(weekday)=%d\n ", sizeof(weekday_st::week));
printf( "sizeof(day)=%d\n ", sizeof(weekday_st::day));
return 0;
}------------------------------------------------------
普通的對齊方式,先上幾個示例吧:
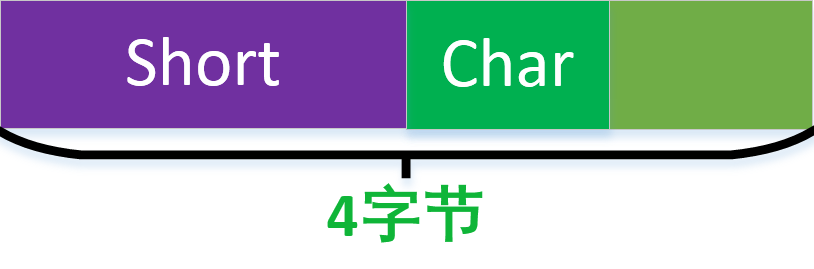
上圖得到的結果是佔用四個位元組,原因是short本身2位元組,char一個位元組,按最長的位元組數對齊。所以很容易得到答案。

如果是上圖所示,結果並不是5,而是6。因為short佔用兩個位元組,為最長字元長度。結構體變數所佔空間的大小必定是最寬資料型別大小的整數倍。所以,總的位元組數不可能是5,那應該怎樣排呢?

如上圖所示,這個不難理解。
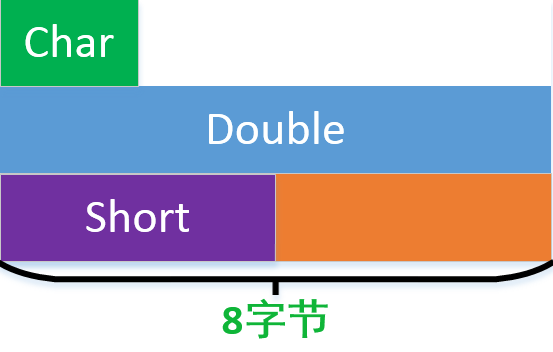
對應的結構體:
typedef struct node
{
char a;
double b;
short c;
};同理,下面的型別也是24
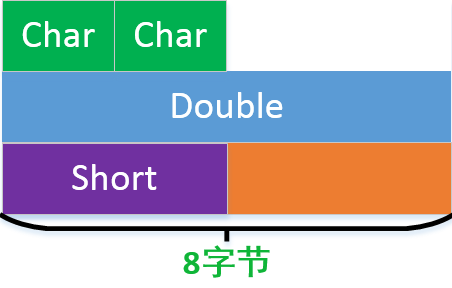
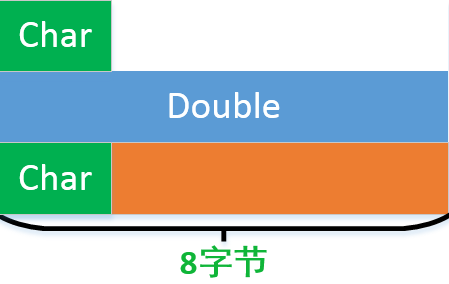
而下圖這種情況自然只有16了
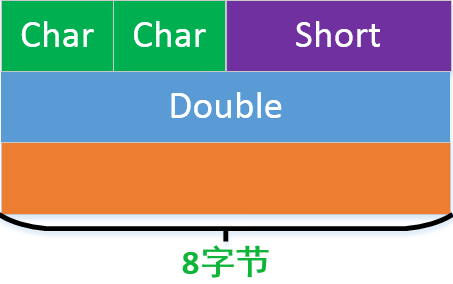
但是如果在新增一個char型資料,按照最長資料對齊的話,結果會變成24,儘管char只有一個位元組。
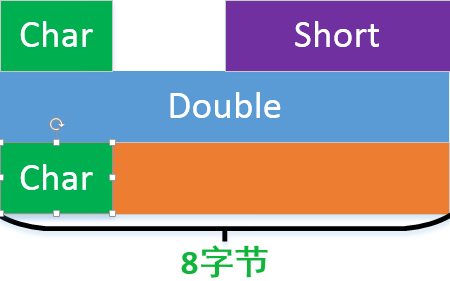
下面結構同樣是24
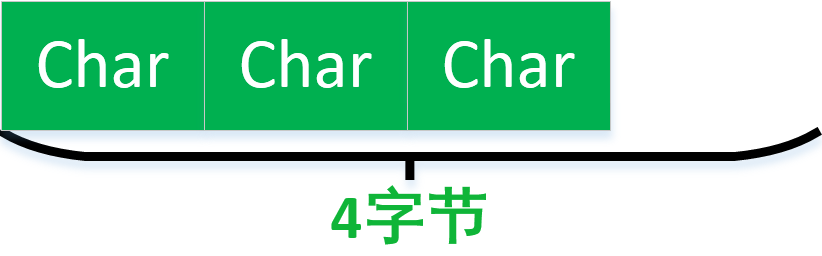
下面結構佔用位元組數為3,因為最大的佔用位元組數為1.三個元素。為三。
看完上面的這些例子之後。對基本的結構體中對齊方式應該有一個大概的瞭解了,總結兩條:
第一條:一般情況下,檢視最寬資料型別大小,並以最寬資料佔用的記憶體大小對齊
第二條:最後得到的結構體變數所佔空間的大小必定是最寬資料型別大小的整數倍
-------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
直接上例子(預設32位編譯器):
struct Test
{
char x1; //第一個成員,放在[0]位置,
short x2; //第二個成員,自身長度為2,按2位元組對齊,所以放在偏移[2,3]的位置,
float x3; //第三個成員,自身長度為4,按4位元組對齊,所以放在偏移[4,7]的位置,
char x4; //第四個成員,自身長度為1,按1位元組對齊,所以放在偏移[8]的位置,
};如果是直接累加結構體中的位元組數得到的是1+2+4+1=8,可想,這個思路是完全錯誤的
如果按照上面註釋中的思路,整個結構體的實際記憶體消耗是9個位元組,但沒有考慮結構整體的對齊方式。
註釋中的思路圖示:

一目瞭然吧!
這種圖示方式也是錯誤的:
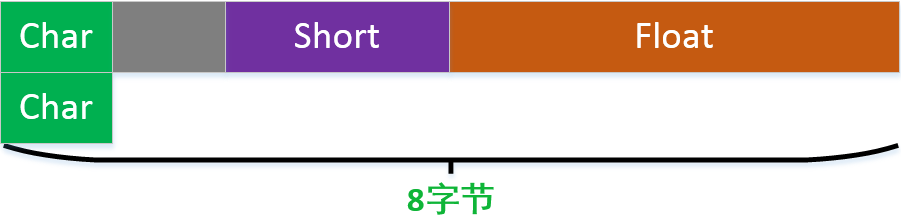
原因是:不要什麼結構都按照八位元組寬度對齊。這裡 結構體中最寬的資料型別是float只有4個位元組。正確的對齊方式是:
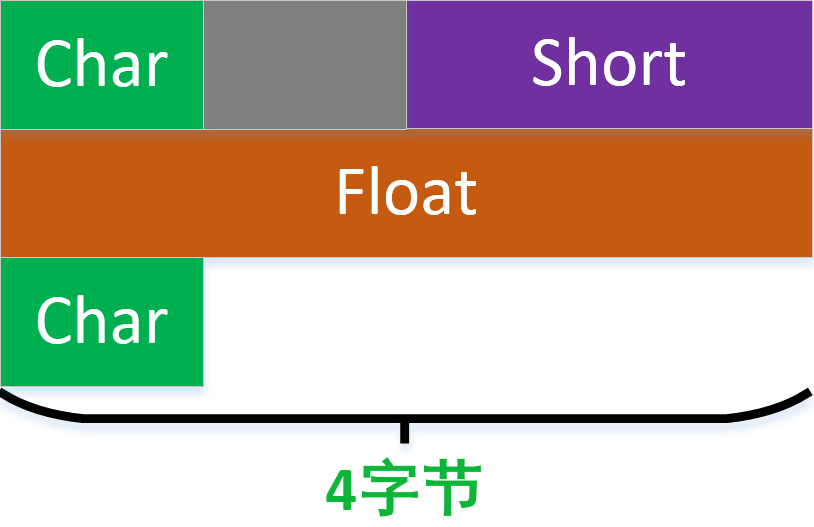
整個結構佔用的空間是12個位元組。
至於空結構體
比如:
空結構體
typedef struct node
{
}S;則sizeof(S)=1;或sizeof(S)=0;
在C++中佔1位元組,而在C中佔0位元組。
解釋為:
對於結構體和空類大小是1這個問題,首先這是一個C++問題,在C語言下空結構體大小為0(當然這是編譯器相關的)。這裡的空類和空結構體是指類或結構體中沒有任何成員。
在C++下,空類和空結構體的大小是1(編譯器相關),這是為什麼呢?為什麼不是0?
這是因為,C++標準中規定,“no object shall have the same address in memory as any other variable” ,就是任何不同的物件不能擁有相同的記憶體地址。 如果空類大小為0,若我們宣告一個這個類的物件陣列,那麼陣列中的每個物件都擁有了相同的地址,這顯然是違背標準的。
但是,也許你還有一個疑問,為什麼C++標準中會有這麼無聊的規定呢?
當然,這樣規定顯然是有原因的。我們假設C++中有一個型別T,我們宣告一個型別T的陣列,然後再宣告一個T型別的指標指向陣列中間某個元素,則我們將指標減去1,應該得到陣列的另一個索引。如下程式碼:
T array[5];
int diff = &array[3] - &array[2];上面的程式碼是一種指標運算,將兩個指標相減,編譯器作出如下面式子所示的動作:
diff = ((char *)&array[3] - (char *)&array[2]) / sizeof T;
式子應該不難懂把,很明顯的一點就是這個式子的計算依賴於sizeof T。雖然上面只是一個例子,但是基本上所有的指標運算都依賴於sizeof T。
好,下面我們來看,如果允許不同的物件有相同的地址將會引發什麼樣的問題,看下面的例子:
&array[3] - &array[2] = &array[3] - &array[1]
= &array[3] - &array[1]
= &array[3] - &array[0]
= 0我們可以看到,在這個例子中,如果每個物件都擁有相同地址,我們將沒有辦法通過指標運算來區分不同的物件。還有一個更嚴重的問題,就是如果 sizeof T是0,就會導致編譯器產生一個除0的操作,引發不可控的錯誤。
基於這個原因,如果允許結構體或者類的大小為0,編譯器就需要實現一些複雜的程式碼來處理這些異常的指標運算。
所以,C++標準規定不同的物件不能擁有相同的地址。那麼怎樣才能保證這個條件被滿足呢?最簡單的方法莫過於不允許任何型別的大小為0。所以編譯器為每個空類或者空結構體都增加了一個虛設的位元組(有的編譯器可能加的更多),這樣這些空類和空結構的大小就不會是0,就可以保證他們的物件擁有彼此獨立的地址。
參考於這裡
還舉幾個例子:typedef struct node1
{
int a;
char b;
short c;
}S1;typedef struct node2
{
char a;
int b;
short c;
}S2;typedef struct node3
{
int a;
short b;
static int c;
}S3;靜態資料成員的存放位置與結構體例項的儲存地址無關(注意只有在C++中結構體中才能含有靜態資料成員,而C中結構體中是不允許含有靜態資料成員的)。
靜態變數c是單獨存放在靜態資料區的,因此用siezof計算其大小時沒有將c所佔的空間計算進來。
具體計算如下:
4+2+[ ]+[ ] = 8,結果為8
typedef struct node4
{
bool a;
S1 s1;
short b;
}S4;而結構體S1上面已經求出來是佔用位元組數是8
那麼S4佔用的位元組數具體如下:
因為S1中最寬資料位元組數為4,示意圖如下:
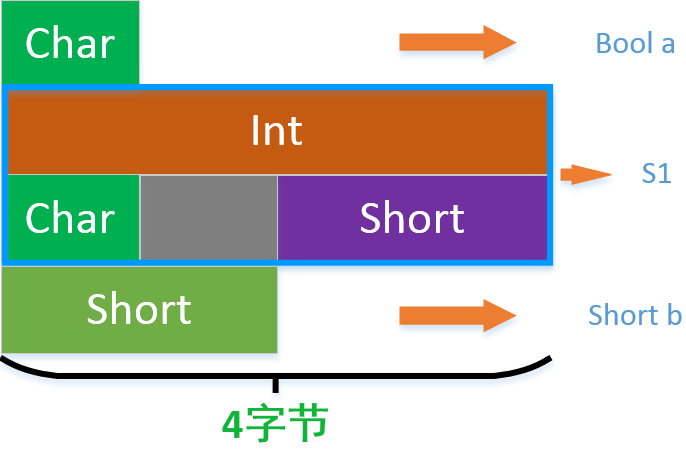
顯然,最後結果是1+[ ]+[ ]+[ ]+8+2+[ ]+[ ] = 16,結果為16
同理;
typedef struct node5
{
bool a;
S1 s1;
double b;
int c;
}S5;接下來說說
在程式中使用#pragma pack(n)命令強制以n位元組對齊時的情況
比較n和結構體中最長資料型別所佔的位元組大小,取兩者中小的一個作為對齊標準。預設為8
若需取消強制對齊方式,則可用命令#pragma pack()將當前位元組對齊值設為預設值(通常是8) 。
如果在程式開頭使用命令#pragma pack(4),對於下面的結構體
typedef struct node5
{
bool a;
S1 s1;
double b;
int c;
}S5;|-----------a--------| 4位元組
|--------s1----------| 4位元組
|--------s1----------| 4位元組
|--------b-----------| 4位元組
|--------b-----------| 4位元組
|---------c----------| 4位元組
重要規則:
1,複雜型別中各個成員按照它們被宣告的順序在記憶體中順序儲存,第一個成員的地址和整個型別的地址相同;
2,每個成員分別對齊,即每個成員按自己的方式對齊,並最小化長度;規則就是每個成員按其型別的對齊引數(通常是這個型別的大小)和指定對齊引數中較小的一個對齊;
3,結構、聯合或者類的資料成員,第一個放在偏移為0的地方;以後每個資料成員的對齊,按照#pragma pack指定的數值和這個資料成員自身長度兩個中比較小的那個進行;也就是說,當#pragma pack指定的值等於或者超過所有資料成員長度的時候,這個指定值的大小將不產生任何效果;
4,複雜型別(如結構)整體的對齊是按照結構體中長度最大的資料成員和#pragma pack指定值之間較小的那個值進行;這樣在成員是複雜型別時,可以最小化長度;
5,結構整體長度的計算必須取所用過的所有對齊引數的整數倍,不夠補空位元組;也就是取所用過的所有對齊引數中最大的那個值的整數倍,因為對齊引數都是2的n次方;這樣在處理陣列時可以保證每一項都邊界對齊;
更改c編譯器的預設位元組對齊方式:
方法一:
使用#pragma pack(n),指定c編譯器按照n個位元組對齊;
使用#pragma pack(),取消自定義位元組對齊方式。
方法二:
__attribute(aligned(n)),讓所作用的資料成員對齊在n位元組的自然邊界上;如果結構中有成員的長度大於n,則按照最大成員的長度來對齊;
__attribute((packed)),取消結構在編譯過程中的優化對齊,按照實際佔用位元組數進行對齊。
綜上所述,下面給出例子並詳細分析:
#pragma pack(8)
struct s1
{
short a; //第一個,放在[0,1]位置,
long b; //第二個,自身長度為4,按min(4, 8) = 4對齊,所以放在[4,7]位置
};struct s2
{
char c; //第一個,放在[0]位置,
s1 d; //第二個,根據規則四,對齊是min( 4, pack_value ) = 4位元組,所以放在[4,11]位置,
long long e; //第三個,自身長度為8位元組,所以按8位元組對齊,所以放在[16,23]位置,
};#pragma pack(4)
class TestC
{
public:
char a; //第一個成員,放在[0]偏移的位置,
short b; //第二個成員,自身長2,#pragma pack(4),取2,按2位元組對齊,所以放在偏移[2,3]的位置。
char c; //第三個,自身長為1,放在[4]的位置。
};#pragma pack(2)
class TestB
{
public:
int aa; //第一個成員,放在[0,3]偏移的位置,
char a; //第二個成員,自身長為1,#pragma pack(4),取小值,也就是1,所以這個成員按一位元組對齊,放在偏移[4]的位置。
short b; //第三個成員,自身長2,#pragma pack(4),取2,按2位元組對齊,所以放在偏移[6,7]的位置。
char c; //第四個,自身長為1,放在[8]的位置。
};#pragma pack(4)
class TestB
{
public:
int aa; //第一個成員,放在[0,3]偏移的位置,
char a; //第二個成員,自身長為1,#pragma pack(4),取小值,也就是1,所以這個成員按一位元組對齊,放在偏移[4]的位置。
short b; //第三個成員,自身長2,#pragma pack(4),取2,按2位元組對齊,所以放在偏移[6,7]的位置。
char c; //第四個,自身長為1,放在[8]的位置。
};總結一下,在計算sizeof時主要注意一下幾點:
1)若為空結構體,則只佔1個位元組的單元 (C++中)
2)若結構體中所有資料型別都相同,則其所佔空間為 成員資料型別長度×成員個數
若結構體中資料型別不同,則取最長資料型別成員所佔的空間為對齊標準,資料成員包含另一個結構體變數t的話,則取t中最 長資料型別與其他資料成員比較,取最長的作為對齊標準,但是t存放時看做一個單位存放,只需看其他成員即可。
3)若使用了#pragma pack(n)命令強制對齊標準,則取n和結構體中最長資料型別佔的位元組數兩者之中的小者作為對齊標準。
另外除了結構體中存在對齊之外,普通的變數儲存也存在位元組對齊的情況,即自身對齊。編譯器規定:普通變數的儲存首地址必須能被該變數的資料型別寬度整除。
補充一下,對於陣列,比如:
char a[3];這種,它的對齊方式和分別寫3個char是一樣的.也就是說它還是按1個位元組對齊.
如果寫: typedef char Array3[3];
Array3這種型別的對齊方式還是按1個位元組對齊,而不是按它的長度.
不論型別是什麼,對齊的邊界一定是1,2,4,8,16,32,64....中的一個.
#pragma pack(push)、#pragma
pack(pop)
push是將當前對齊的方式壓棧,pop是將棧中的對齊方式彈出
#pragma pack(push)
#pragma pack(1) //注意,此處開始了喲
struct test1
{
char a;
int b;
char c;
};
#pragma pack(pop)//注意,此處結束了喲
struct test2
{
char a;
int b;
char c;
};
int main()
{/*此處省略*/}
//那麼,你用test1定義的變數大小就是6,用test2定義的變數大小就是12。
#pragma pack(push, n)
先將當前位元組對齊值壓入編譯棧棧頂, 然後再將 n 設為當前值。
#pragma pack(pop, n)
將編譯棧棧頂的位元組對齊值彈出, 然後丟棄, 再將 n 設為當前值。
#pragma pack(n)和#pragma pop()
struct sample
{
char a;
double b;
};當sample結構沒有加#pragma pack(n)的時候,sample按最大的成員那個對齊;
(所謂的對齊是指對齊數為n時,對每個成員進行對齊,既如果成員a的大小小於n則將a擴大到n個大小;
如果a的大小大於n則使用a的大小;)所以上面那個結構的大小為16位元組.
當sample結構加#pragma pack(1)的時候,sizeof(sample)=9位元組;無空位元組。
(另注:當n大於sample結構的最大成員的大小時,n取最大成員的大小。
所以當n越大時,結構的速度越快,大小越大;反之則)
#pragma pop()就是取消#pragma pack(n)的意思了,也就是說接下來的結構不用#pragma pack(n)
#include <iostream>
using namespace std;
#pragma pack(4)
typedef struct TestB
{
int d;
char a;
short b;
char c;
char e;
};
void main()
{
cout<<sizeof(TestB)<<endl;
system("pause");
}
#pragma pack(4)
class TestB
{
public:
int aa; //第一個成員,放在[0,3]偏移的位置,
char a; //第二個成員,自身長為1,#pragma pack(4),取小值,也就是1,所以這個成員按一位元組對齊,放在偏移[4]的位置。
short b; //第三個成員,自身長2,#pragma pack(4),取2,按2位元組對齊,所以放在偏移[6,7]的位置。
char c; //第四個,自身長為1,放在[8]的位置。
};
這個類實際佔據的記憶體空間是9位元組
類之間的對齊,是按照類內部最大的成員的長度,和#pragma pack規定的值之中較小的一個對齊的。
所以這個例子中,類之間對齊的長度是min(sizeof(int),4),也就是4。
9按照4位元組圓整的結果是12,所以sizeof(TestB)是12。
更詳細的介紹:
char A;
int B; 

//by www.datahf.net zhangyu
typedef struct T
{
char c; //本身長度1位元組
__int64 d; //本身長度8位元組
int e; //本身長度4位元組
short f; //本身長度2位元組
char g; //本身長度1位元組
short h; //本身長度2位元組
}; 


typedef struct A
{
char c; //1個位元組
int d; //4個位元組,要與4位元組對齊,所以分配至第4個位元組處
short e; //2個位元組, 上述兩個成員過後,本身就是與2對齊的,所以之前無填充
}; //整個結構體,最長的成員為4個位元組,需要總長度與4位元組對齊,所以, sizeof(A)==12
typedef struct B
{
char c; //1個位元組
__int64 d; //8個位元組,位置要與8位元組對齊,所以分配到第8個位元組處
int e; //4個位元組,成員d結束於15位元組,緊跟的16位元組對齊於4位元組,所以分配到16-19
short f; //2個位元組,成員e結束於19位元組,緊跟的20位元組對齊於2位元組,所以分配到20-21
A g; //結構體長為12位元組,最長成員為4位元組,需按4位元組對齊,所以前面跳過2個位元組,
//到24-35位元組處
char h; //1個位元組,分配到36位元組處
int i; //4個位元組,要對齊4位元組,跳過3位元組,分配到40-43 位元組
}; //整個結構體的最大分配成員為8位元組,所以結構體後面加5位元組填充,被到48位元組。故:
//sizeof(B)==48;
相關推薦
pragma pack對齊方式詳細介紹
為了加快讀寫資料的速度,編譯器採用資料對齊的方式來為每一個結構體分配空間。——寫在開頭 本文有自己的原創也有轉載的博文,轉載的部分一一列出來,可能不全請見諒這裡這裡這裡這裡等等。。。。。。 (更詳細的解說: 在用sizeof運算子求算某結構體所佔空間時,並不
#pragma pack 對齊方式
程式編譯器對結構的儲存的特殊處理確實提高CPU儲存變數的速度,但是有時候也帶來了一些麻煩,我們也遮蔽掉變數預設的對齊方式,自己可以設定變數的對齊方式。編譯器中提供了#pragma pack(n)來設定變數以n位元組對齊方式。n位元組對齊就是說變數存放的起始地址的偏移量有兩種情
pragma pack 對齊用法
為了搞清楚#pragma pack(n)的寫法,Test一下。下面這段測試程式碼貼在任意一個控制檯程式的面前面即可。 //windowsxp+vs2008 //#pragma pack(sh
C語言中的對齊方式#pragma pack()偽指令及_attribute_aligned_指令
Q:為什麼會引入這樣的偽指令呢? A:我們知道,在儲存結構體或聯合(struct / union)這樣的複合型變數時,計算機在記憶體空間中開闢一段連續的位置,按照成員變數定義的自然順序進行初始化。但
#pragma pack(n)記憶體對齊方式
在C語言中,結構是一種複合資料型別,其構成元素既可以是基本資料型別(如int、long、float等)的變數,也可以是一些複合資料型別(如陣列、結構、聯合等)的資料單元。在結構中,編譯器為結構的每個成員按其自然對界(alignment)條件分配空間。各個成員按照它們被宣告的順
對齊方式#pragma pack()偽指令及_attribute_aligned_指令
GNU C 的一大特色就是__attribute__ 機制。__attribute__ 可以設定函式屬性(Function Attribute )、變數屬性(Variable Attribute )和型別屬性(Type Attribute )。 __attribute__ 書寫特徵是:__attri
par函數的adj 參數- 控制文字的對齊方式
div 效果 lin .cn 表示 對齊方式 制圖 技術 cnblogs adj 用來控制文字的對齊方式,取值範圍為0到1,控制圖片中x軸和y軸標簽,標題,以及通過text 添加的文字的對齊方式 0表示左對齊,代碼示例: par(adj = 0)plot(1:5, 1:5
對齊方式
align 水平 nbsp text vertical pan font ott -s 水平對齊方式--text-align屬性 left 左 默認值 right 右 center 中 justify 兩端對齊垂直對齊--
CSS3----vertical-align(文本垂直對齊方式)
title sel png ont itl ase pla otto contain 一、代碼: <!DOCTYPE html> <html> <head> <meta charset="utf-8"> <
IntelliJ IDEA設置代碼括號對齊方式
har size pop class post 括號 成功 tar 圖片 IntelliJ IDEA設置代碼括號對齊方式 IntelliJ IDEA默認的對齊方式如下:括號跟函數名在一行 想改為括號獨自占一行,如下: 配置方式如下:File
34 文本樣式 1 word-spacing單詞間距 letter-spacing 字母間距 2 text-align 文本對齊方式 justify 兩端對齊 3 text-indent 首行縮進
letter com 分享圖片 inf nbsp png 技術分享 方式 bubuko 1 2 3 34 文本樣式 1 word-spacing單詞間距 letter-spacing 字母間距 2 text-align 文本對齊方式 justify 兩端對齊 3
記事本:如何將16進位制數賦給int型變數,再按16進位制輸出,以及電腦大小端對齊方式測試。
c和c++版本: int i=0x12345678; printf("%hx",i); java版本:
python學習之網站的編寫(HTML,CSS,JS)(十三)----------CSS字型和對齊方式的設定
<!DOCTYPE html> <html lang="en"> <head> <meta charset="UTF-8"> <title>逆水行舟不進則退</title> </head> <b
一種巢狀式柵欄佈局的對齊方式
轉載自CSDN本文連結地址: 一種巢狀式柵欄佈局的對齊方式 在bootstrap的應用中,經常需要對柵格進行巢狀佈局,但也因為如此,很容易出現內容無法對齊的現象。 UI給定的要求是兩欄表格佈局,文字與輸入框的佔比為1:3,詳細布局檔案見下圖。 幾乎不用思考,我們就能很快寫出
C++中結構體的對齊方式
在面試中,常會考到結構體的對齊方式,因此對其進行總結。 1、在沒有#pragma pack巨集的情況下 struct sA{ double d1; int i1; double d2; char c1;
CSS 下拉內容的對齊方式
<!DOCTYPE html > <html> <head> <meta charset="utf-8"> <title>自學教程
Android中UI之對齊方式
UI中的對齊方式: 一、LinearLayout(線性佈局) 提供了控制元件水平垂直排列的模型,同時可以通過設定子控制元件的weight佈局引數控制各個控制元件在佈局中的相對大 小。 水平(vertical)垂直(horizontal) fill-parent:佔滿整個螢幕 wr
Java將資料按列寫入Excel並設定格式(字型、背景色、自動列寬、對齊方式等)
本文使用jxl.jar工具類庫將資料按列寫入Excel並設定格式(字型、背景色、自動列寬、對齊方式等)。 /** * 按列寫入Excel並設定格式 * * @param outputUrl * 輸出路徑 * @par
CSS——文字對齊方式
橫向對齊 方法1:單行塊級元素水平居中只用新增text-align即可,如P標籤,垂直居中vertical-align只適用於行內元素與單元格,所以設定行高與塊高度相同即可 text-align: center; 方法2:普通的文字居中只要設定text-ali
Markdown 中控制圖片的大小 對齊方式
普通展示圖片 MarkDown中顯示圖片的語法是  。但是這種方法只是單純把圖片顯示出來,如果圖片很大的話就會鋪滿螢幕或者超高,排版上不好看。 通過img標籤控制寬高 &