
使用Neo4j進行全棧Web開發
在開發一個全棧web應用時,作為整個棧的底層,你可以在多種資料庫之間進行選擇。作為事實的資料來源,你當然希望選擇一種可靠的資料庫,但同時也希望它能夠允許你以良好的方式進行資料建模。在本文中,我將為你介紹Neo4j,當你的資料模型包含大量關聯資料以及關係時,它可以成為你的web應用棧的基礎的一個良好選擇。
Neo4j是什麼?
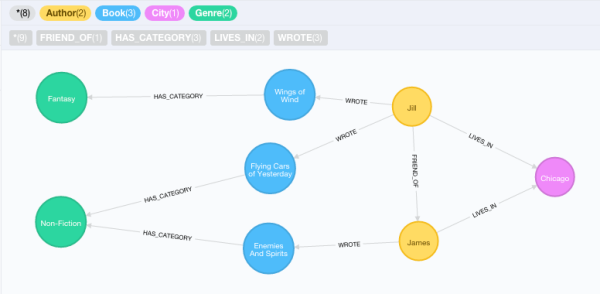
Neo4j是一個圖形資料庫,這也就意味著它的資料並非儲存在表或集合中,而是儲存為節點以及節點之間的關係。在Neo4j中,節點以及關係都能夠包含儲存值的屬性,此外:
- 可以為節點設定零或多個標籤(例如Author或Book)
- 每個關係都對應一種型別(例如WROTE或FRIEND_OF)
- 關係總是從一個節點指向另一個節點(但可以在不考慮指向性的情況下進行查詢)
為什麼要選擇Neo4j?
在考慮為web應用選擇某個資料庫時,我們需要考慮對它有哪些方面的期望,其中最重要的一些條件包括:
- 它是否易於使用?
- 它是否允許你方便地迴應對需求的變更?
- 它是否支援高效能查詢?
- 是否能夠方便地對其進行資料建模?
- 它是否支援事務?
- 它是否支援大規模應用?
- 它是否足夠有趣(很遺憾的是對於資料庫的這方面要求經常被忽略)?
從這幾個方面來說,Neo4j是一個合適的選擇。Neo4j……
- 自帶一套易於學習的查詢語言(名為 Cypher)
- 不使用schema,因此可以滿足你的任何形式的需求
- 與關係型資料庫相比,對於高度關聯的資料(圖形資料)的查詢快速要快上許多
- 它的實體與關係結構非常自然地切合人類的直觀感受
- 支援相容ACID的事務操作
- 提供了一個高可用性模型,以支援大規模資料量的查詢,支援備份、資料區域性性以及冗餘
- 提供了一個視覺化的查詢控制檯,你不會對它感到厭倦的
什麼時候不應使用Neo4j?
作為一個圖形NoSQL資料庫,Neo4j提供了大量的功能,但沒有什麼解決方案是完美的。在以下這些用例中,Neo4j就不是非常適合的選擇:
- 記錄大量基於事件的資料(例如日誌條目或感測器資料)
- 對大規模分散式資料進行處理,類似於Hadoop
- 二進位制資料儲存
- 適合於儲存在關係型資料庫中的結構化資料
在上面的示例中,你看到了由Author、City、Book和Category以及它們之間的關係所組成的一個圖形。如果你希望通過Cypher語句在Neo4j web控制檯中列出這些資料結果,可以執行以下語句:
MATCH
(city:City)<-[:LIVES_IN]-(:Author)-[:WROTE]->
(book:Book)-[:HAS_CATEGORY]->(category:Category)
WHERE city.name = “Chicago”
RETURN *請注意這種ASCII風格的語法,它在括號內表示節點名稱,並用箭頭表示一個節點指向另一個節點的關係。Cypher通過這種方式允許你匹配某個指定的子圖形模式。
當然,Neo4j的功能不僅僅在於展示漂亮的圖片。如果你希望按照作者所處的地點(城市)計算書籍的分類數目,你可以通過使用相同的MATCH模式,返回一組不同的列,例如:
MATCH
(city:City)<-[:LIVES_IN]-(:Author)-[:WROTE]->
(book:Book)-[:HAS_CATEGORY]->(category:Category)
RETURN city.name, category.name, COUNT(book)執行這條語句將返回以下結果:
| city.name | category.name | COUNT(category) |
|---|---|---|
| Chicago | Fantasy | 1 |
| Chicago | Non-Fiction | 2 |
雖然Neo4j也能夠處理“大資料”,但它畢竟不是Hadoop、HBase或Cassandra,通常來說不會在Neo4j資料庫中直接處理海量資料(以PB為單位)的分析。但如果你樂於提供關於某個實體及其相鄰資料關係(比如你可以提供一個web頁面或某個API返回其結果),那麼它是一種良好的選擇。無論是簡單的CRUD訪問,或是複雜的、深度巢狀的資源檢視都能夠勝任。
你應該選擇哪種技術棧以配合Neo4j?
所有主流的程式語言都通過HTTP API的方式支援Neo4j,或者採用基本的HTTP類庫,或是通過某些原生的類庫提供更高層的抽象。此外,由於Neo4j是以Java語言編寫的,因此所有包含JVM介面的語言都能夠充分利用Neo4j中的高效能API。
Neo4j本身也提供了一個“技術棧”,它允許你選擇不同的訪問方式,包括簡單訪問乃至原生效能等等。它提供的特性包括:
- 通過一個HTTP API執行Cypher查詢,並獲取JSON格式的結果
- 一種“非託管擴充套件”機制,允許你為Neo4j資料庫編寫自己的終結點
- 通過一個高層Java API指定節點與關係的遍歷
- 通過一個低層的批量載入API處理海量初始資料的獲取
- 通過一個核心Java API直接訪問節點與關係,以獲得最大的效能
一個應用程式示例
最近我正好有機會將一個專案擴充套件為基於Neo4j的應用程式。該應用程式(可以訪問graphgist.neo4j.com檢視)是關於GraphGist的一個入口網站。GraphGist是一種通過互動式地渲染(在你的瀏覽器中)生成的文件,它基於一個簡單的文字檔案(AsciiDoctor),其中用文字描述以及圖片描述了整個資料模型、架構以及用例查詢,可以線上執行它們,並使它們保持視覺化。它非常類似一個iPython notebook或是一張互動式的白紙。GraphGist也允許讀者在瀏覽器中編寫自己定義的查詢,以檢視整個資料集。
Neo4j的原作者Neo Technology希望為GraphGist提供一個由社群建立的展示專案。當然,後端技術選用了Neo4j,而整個技術棧的其餘部分,我的選擇是:
所有程式碼都已開源,可以在GitHub上任意瀏覽。
從概念上講,GraphGist入口網站是一個簡單的應用,它提供了一個GraphGist列表,允許使用者檢視每個GraphGist的詳細內容。資料領域是由Gist、Keyword/Domain/Use Case(作為Gist分類)以及Person(作為Gist的作者)所組成的:
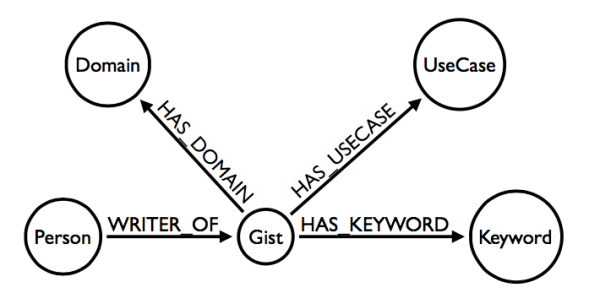
現在你已經熟悉這個模型了,在繼續深入學習之前,我想為你快速地介紹一下Cypher這門查詢語言。舉例來說,如果我們需要返回所有的Gist和它們的關鍵字,可以通過以下語句實現:
MATCH (gist:Gist)-[:HAS_KEYWORD]->(keyword:Keyword)
RETURN gist.title, keyword.name這段語句將返回一張表,其中的每一行是由每個Gist和Keyword的組合構成的,正如同SQL join的行為一樣。現在我們更深入一步,假設我們想要找到某個人所編寫的Gist對應的所有Domain,我們可以執行下面這條查詢語句:
MATCH (person:Person)-[:WRITER_OF]->(gist:Gist)-[:HAS_DOMAIN]->(domain:Domain)
WHERE person.name = “John Doe”
RETURN domain.name, COUNT(gist)該語句將返回另一個結果表,其中的每一行包含Domain的名稱,以及這個Person對於這一Domain所編寫的全部Gist的數量。這裡無需使用GROUP BY語句,因為當我們使用例如COUNT()這樣的聚合函式時,Neo4j會自動在RETURN語句中對其它列進行分組操作。
現在你對Cypher已經有一點感覺了吧?那麼讓我們來看一個來自實際應用中的查詢。在建立這個門戶時,如果能夠通過某種方式,只需對資料庫進行一次請求就能夠返回我們所需的所有資料,並且以一種我們需要的格式進行結構組織,那將十分有用。
讓我們開始建立這個用於門戶的API(可以在GitHub上找到)的查詢吧。首先,我們需要按照Gist的title屬性進行匹配,並匹配所有相關的Gist節點:
// Match Gists based on title
MATCH (gist:Gist) WHERE gist.title =~ {search_query}
// Optionally match Gists with the same keyword
// and pass on these related Gists with the
// most common keywords first
OPTIONAL MATCH (gist)-[:HAS_KEYWORD]->(keyword)<-[:HAS_KEYWORD]-(related_gist)這裡有幾個要注意的地方。首先,WHERE語句是通過一個正則表示式(即=~操作符)和一個引數對title屬性進行匹配的。引數(Parameter)是Neo4j的一項特性,它能夠將查詢與其所代表的資料進行分離。使用引數能夠讓Neo4j對查詢和查詢計劃進行快取,這也意味著你無需擔心遭遇查詢注入攻擊。其次,我們在這裡使用了一個OPTIONAL MATCH語句,它表示我們希望始終返回原始的Gist,即使它並沒有相關的Gist。
現在讓我們對之前的查詢進行擴充套件,將RETURN語句替換為WITH語句:
MATCH (gist:Gist) WHERE gist.title =~ {search_query}
OPTIONAL MATCH (gist)-[:HAS_KEYWORD]->(keyword)<-[:HAS_KEYWORD]-(related_gist)
WITH gist, related_gist, COUNT(DISTINCT keyword.name) AS keyword_count
ORDER BY keyword_count DESC
RETURN
gist,
COLLECT(DISTINCT {related: { id: related_gist.id, title:
related_gist.title, poster_image: related_gist.poster_image, url:
related_gist.url }, weight: keyword_count }) AS related在RETURN語句中的COLLECT()作用是將由Gist和相關Gist所組成的節點轉換為一個結果集,讓其中每一行Gist只出現一次,並對應一個相關Gist的節點陣列。在COLLECT()語句中,我們在相關Gist中僅指定了所需的部分資料,以減小整個響應的大小。
最後,我們將產生這樣一條查詢語句,這也是最後一次使用WITH語句了:
MATCH (gist:Gist) WHERE gist.title =~ {search_query}
OPTIONAL MATCH (gist)-[:HAS_KEYWORD]->(keyword)<-[:HAS_KEYWORD]-(related_gist)
WITH gist, related_gist, COUNT(DISTINCT keyword.name) AS keyword_count
ORDER BY keyword_count DESC
WITH
gist,
COLLECT(DISTINCT {related: { id: related_gist.id, title: related_gist.title, poster_image: related_gist.poster_image, url: related_gist.url }, weight: keyword_count }) AS related
// Optionally match domains, use cases, writers, and keywords for each Gist
OPTIONAL MATCH (gist)-[:HAS_DOMAIN]->(domain:Domain)
OPTIONAL MATCH (gist)-[:HAS_USECASE]->(usecase:UseCase)
OPTIONAL MATCH (gist)<-[:WRITER_OF]-(writer:Person)
OPTIONAL MATCH (gist)-[:HAS_KEYWORD]->(keyword:Keyword)
// Return one Gist per row with arrays of domains, use cases, writers, and keywords
RETURN
gist,
related,
COLLECT(DISTINCT domain.name) AS domains,
COLLECT(DISTINCT usecase.name) AS usecases,
COLLECT(DISTINCT keyword.name) AS keywords
COLLECT(DISTINCT writer.name) AS writers,
ORDER BY gist.title在這個查詢中,我們將選擇性地匹配所有相關的Domain、Use Case、Keyword和Person節點,並且將它們全部收集起來,與我們對相關Gist的處理方式相同。現在我們的結果不再是平坦的、反正規化的,而是包含一列Gist,其中每個Gist都對應著相關Gist的陣列,形成了一種“has many”的關係,並且沒有任何重複資料。太酷了!
不僅如此,如果你覺得用表的形式返回資料太老土,那麼Cypher也可以返回物件:
RETURN
{
gist: gist,
domains: collect(DISTINCT domain.name) AS domains,
usecases: collect(DISTINCT usecase.name) AS usecases,
writers: collect(DISTINCT writer.name) AS writers,
keywords: collect(DISTINCT keyword.name) AS keywords,
related_gists: related
}
ORDER BY gist.title通常來說,在稍具規模的web應用程式中,需要進行大量的資料庫呼叫以返回HTTP響應所需的資料。雖然你可以並行地執行查詢,但通常來說你需要首先返回某個查詢的結果集,才能傳送另一個數據庫請求以獲取相關的資料。在SQL中,你可以通過生成複雜的、開銷很大的表join語句,通過一個查詢從多張表中返回結果。但只要你在同一個查詢中進行了多次SQL join,這個查詢的複雜性將會飛快地增長。更不用說資料庫仍然需要進行表或索引掃描才能夠獲得相應的資料了。而在Neo4j中,通過關係獲取實體的方式是直接使用對應於相關節點的指標,因此伺服器可以隨意進行遍歷。
儘管如此,這種方式也存在著諸多缺陷。雖然這種方式能夠通過一個查詢返回所有資料,但這個查詢會相當長。我至今也沒有找到一種方式能夠對進行模組化以便重用。進一步考慮:我們可以在其它場合同樣呼叫這個終結點,但讓它顯示相關Gist的更多資訊。我們可以選擇修改這個查詢以返回更多的資料,但也意味著對於原始的用例來說,它返回了額外的不必要資料。
我們是幸運的,因為有這麼多優秀的資料庫可以選擇。雖然關係型資料庫對於儲存結構化資料來說依然是最佳的選擇,但NoSQL資料庫更適合於管理半結構化資料、非結構化資料以及圖形資料。如果你的資料模型中包括大量的關聯資料,並且希望使用一種直觀的、有趣的並且快速的資料庫進行開發,那麼你就應當嘗試一下Neo4j。
本文由Brian Underwood撰寫,而Michael Hunger也為本文作出了許多貢獻。
關於作者
Brian Underwood是一位軟體工程師,喜愛任何與資料相關的東西。作為一名Neo4j 的Developer Advocate,以及neo4j ruby gem的維護者,Brian經常通過一些演講,以及在他的部落格上的文章宣傳圖形資料庫的強大與簡潔。Brian如今正與他的妻兒在全球旅行。可以在Twitter 上找到Brian,或在LinkedIn上聯絡他。