
快速排序的5種優化方法
1、快速排序的基本思想:
快速排序使用分治的思想,通過一趟排序將待排序列分割成兩部分,其中一部分記錄的關鍵字均比另一部分記錄的關鍵字小。之後分別對這兩部分記錄繼續進行排序,遞迴地以達到整個序列有序的目的。
2、快速排序的三個步驟:
(1)選擇基準:在待排序列中,按照某種方式挑出一個元素,作為 "基準"(pivot)
(2)分割操作:以該基準在序列中的實際位置,把序列分成兩個子序列。此時,在基準左邊的元素都比該基準小,在基準右邊的元素都比基準大
(3)遞迴地對兩個序列進行快速排序,直到序列為空或者只有一個元素。
3、選擇基準的方式
對於分治演算法,當每次劃分時,演算法若都能分成兩個等長的子序列時,那麼分治演算法效率會達到最大。也就是說,基準的選擇是很重要的。選擇基準的方式決定了兩個分割後兩個子序列的長度,進而對整個演算法的效率產生決定性影響。
最理想的方法是,選擇的基準恰好能把待排序序列分成兩個等長的子序列
我們介紹三種選擇基準的方法
方法(1):固定位置(書本上介紹的內容)
思想:取序列的第一個或最後一個元素作為基準
基本的快速排序
int SelectPivot(int arr[],int low,int high)
{
return arr[low];//選擇選取序列的第一個元素作為基準
}
注意:基本的快速排序選取第一個或最後一個元素作為基準。但不是一種好方法
測試資料:

測試資料分析:如果輸入序列是隨機的,處理時間可以接受的。如果陣列已經有序時,此時的分割就是一個非常不好的分割。因為每次劃分只能使待排序序列減一,此時為最壞情況,快速排序淪為起泡排序,時間複雜度為Θ(n^2)。而且,輸入的資料是有序或部分有序的情況是相當常見的。因此,使用第一個元素作為樞紐元是非常糟糕的,為了避免這個情況,就引入了下面兩個獲取基準的方法。
方法(2):隨機選取基準(不重要)
引入的原因:在待排序列是部分有序時,固定選取樞軸使快排效率底下,要緩解這種情況,就引入了隨機選取樞軸
思想:取待排序列中任意一個元素作為基準
/*隨機選擇樞軸的位置,區間在low和high之間*/ int SelectPivotRandom(int arr[],int low,int high) { srand((unsigned)time(NULL));//產生樞軸的位置 int pivotPos = rand()%(high - low) + low; swap(arr[pivotPos],arr[low]);//把樞軸位置的元素和low位置元素互換,此時可以和普通的快排一樣呼叫劃分函式 return arr[low]; }

方法(3):三數取中(median-of-three)(優化有序的資料)
引入的原因:雖然隨機選取樞軸時,減少出現不好分割的機率,但是還是最壞情況下還是O(n^2),要緩解這種情況,就引入了三數取中選取樞軸
分析:最佳的劃分是將待排序的序列分成等長的子序列,最佳的狀態我們可以使用序列的中間的值,也就是第N/2個數。可是,這很難算出來,並且會明顯減慢快速排序的速度。這樣的中值的估計可以通過隨機選取三個元素並用它們的中值作為樞紐元而得到。事實上,隨機性並沒有多大的幫助,因此一般的做法是使用左端、右端和中心位置上的三個元素的中值作為樞紐元。顯然使用三數中值分割法消除了預排序輸入的不好情形,並且減少快排大約14%的比較次數
舉例:待排序序列為:8 1 4 9 6 3 5 2 7 0
左邊為:8,右邊為0,中間為6.
我們這裡取三個數排序後,中間那個數作為樞軸,則樞軸為6
注意:在選取中軸值時,可以從由左中右三個中選取擴大到五個元素中或者更多元素中選取,一般的,會有(2t+1)平均分割槽法(median-of-(2t+1),三平均分割槽法英文為median-of-three)。
具體思想:對待排序序列中low、mid、high三個位置上資料進行排序,取他們中間的那個資料作為樞軸,並用0下標元素儲存樞軸。
/*函式作用:取待排序序列中low、mid、high三個位置上資料,選取他們中間的那個資料作為樞軸*/
int SelectPivotMedianOfThree(int arr[],int low,int high)
{
int mid = low + ((high - low) >> 1);//計算陣列中間的元素的下標
//使用三數取中法選擇樞軸
if (arr[mid] > arr[high])//目標: arr[mid] <= arr[high]
{
swap(arr[mid],arr[high]);
}
if (arr[low] > arr[high])//目標: arr[low] <= arr[high]
{
swap(arr[low],arr[high]);
}
if (arr[mid] > arr[low]) //目標: arr[low] >= arr[mid]
{
swap(arr[mid],arr[low]);
}
//此時,arr[mid] <= arr[low] <= arr[high]
return arr[low];
//low的位置上儲存這三個位置中間的值
//分割時可以直接使用low位置的元素作為樞軸,而不用改變分割函數了
}
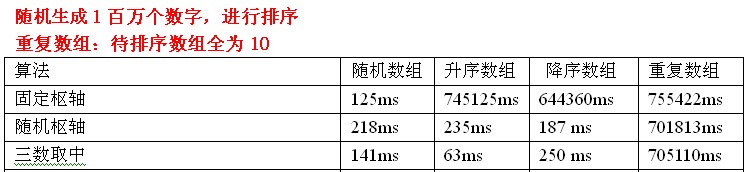
測試資料分析:使用三數取中選擇樞軸優勢還是很明顯的,但是還是處理不了重複陣列
優化1、採用三數取中法原則樞紐。
優化2、當待排序序列的長度分割到一定大小後,使用插入排序。
原因:對於很小和部分有序的陣列,快排不如插排好。當待排序序列的長度分割到一定大小後,繼續分割的效率比插入排序要差,此時可以使用插排而不是快排
截止範圍:待排序序列長度N = 10,雖然在5~20之間任一截止範圍都有可能產生類似的結果,這種做法也避免了一些有害的退化情形。摘自《資料結構與演算法分析》Mark Allen Weiness 著
if (high - low + 1 < 10)
{
InsertSort(arr,low,high);
return;
}//else時,正常執行快排
測試資料:
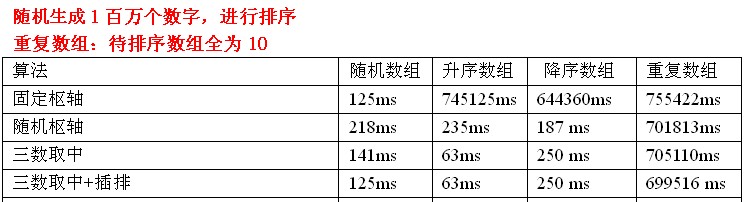
測試資料分析:針對隨機陣列,使用三數取中選擇樞軸+插排,效率還是可以提高一點,但是針對已排序的陣列,是沒有任何用處的。因為待排序序列是已經有序的,那麼每次劃分只能使待排序序列減一。此時,插排是發揮不了作用的。所以這裡看不到時間的減少。另外,三數取中選擇樞軸+插排還是不能處理重複陣列
優化3、在一次分割結束後,可以把與Key相等的元素聚在一起,繼續下次分割時,不用再對與key相等元素分割
舉例:
待排序序列 1 4 6 7 6 6 7 6 8 6
三數取中選取樞軸:下標為4的數6
轉換後,待分割序列:6 4 6 7 1 6 7 6 8 6
樞軸key:6
本次劃分後,未對與key元素相等處理的結果:1 4 6 6 7 6 7 6 8 6
下次的兩個子序列為:1 4 6 和 7 6 7 6 8 6
本次劃分後,對與key元素相等處理的結果:1 4 6 6 6 6 6 7 8 7
下次的兩個子序列為:1 4 和 7 8 7
經過對比,我們可以看出,在一次劃分後,把與key相等的元素聚在一起,能減少迭代次數,效率會提高不少
具體過程:在處理過程中,會有兩個步驟
第一步,在劃分過程中,把與key相等元素放入陣列的兩端
第二步,劃分結束後,把與key相等的元素移到樞軸周圍
舉例:
待排序序列 1 4 6 7 6 6 7 6 8 6
三數取中選取樞軸:下標為4的數6
轉換後,待分割序列:6 4 6 7 1 6 7 6 8 6
樞軸key:6
第一步,在劃分過程中,把與key相等元素放入陣列的兩端
結果為:6 4 1 6(樞軸) 7 8 7 6 6 6
此時,與6相等的元素全放入在兩端了
第二步,劃分結束後,把與key相等的元素移到樞軸周圍
結果為:1 4 66(樞軸) 6 6 6 7 8 7
此時,與6相等的元素全移到樞軸周圍了
之後,在1 4 和 7 8 7兩個子序列進行快排
void gather(int arr[], int low, int high, int boundKey, int *left, int *right)
{
if (low < high)
{
int count = boundKey - 1;
for (int i = boundKey - 1; i >= low; --i)
{
if (arr[i] == arr[boundKey])
{
swap(arr, i, count);
count--;
}
}
*left = count;
count = boundKey + 1;
for (int i = boundKey + 1; i <= high; ++i)
{
if (arr[i] == arr[boundKey])
{
swap(arr, i, count);
count++;
}
}
*right = count;
}
}測試資料:
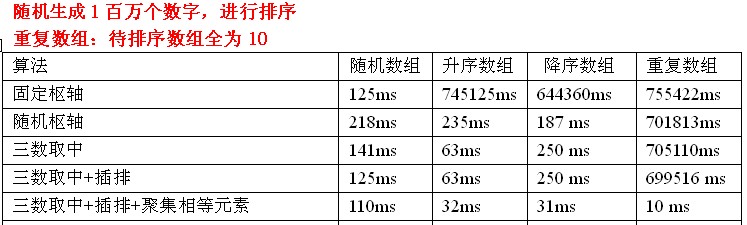
測試資料分析:三數取中選擇樞軸+插排+聚集相等元素的組合,效果竟然好的出奇。
原因:在陣列中,如果有相等的元素,那麼就可以減少不少冗餘的劃分。這點在重複陣列中體現特別明顯啊。
其實這裡,插排的作用還是不怎麼大的。
優化4:優化遞迴操作(不重要)
快排函式在函式尾部有兩次遞迴操作,我們可以對其使用尾遞迴優化
優點:如果待排序的序列劃分極端不平衡,遞迴的深度將趨近於n,而棧的大小是很有限的,每次遞迴呼叫都會耗費一定的棧空間,函式的引數越多,每次遞迴耗費的空間也越多。優化後,可以縮減堆疊深度,由原來的O(n)縮減為O(logn),將會提高效能。
void QSort(int arr[],int low,int high)
{
int pivotPos = -1;
if (high - low + 1 < 10)
{
InsertSort(arr,low,high);
return;
}
while(low < high)
{
pivotPos = Partition(arr,low,high);
QSort(arr,low,pivot-1);
low = pivot + 1;
}
}
注意:在第一次遞迴後,low就沒用了,此時第二次遞迴可以使用迴圈代替
測試資料:

測試資料分析:其實這種優化編譯器會自己優化,相比不使用優化的方法,時間幾乎沒有減少
優化5:使用並行或多執行緒處理子序列(略)
所有的資料測試:

概括:這裡效率最好的快排組合 是:三數取中+插排+聚集相等元素,它和STL中的Sort函式效率差不多
注意:由於測試資料不穩定,資料也僅僅反應大概的情況。如果時間上沒有成倍的增加或減少,僅僅有小額變化的話,我們可以看成時間差不多。【完整的快排優化後代碼要的可以私我哦~】