
MongoDB架構學習筆記
MongoDB的需求目標
MongoDB是一款知名的NoSQL資料庫,其設計哲學是結合關係型資料庫的核心能力和NoSQL的關鍵技術。

上圖的左側即MongoDB目標實現的關係型資料庫的關鍵能力:
- 善於表達的查詢語言:使用者應能夠使用豐富的方法訪問和操作資料,以支援聯機應用和分析應用。
- 輔助索引:索引是高效訪問資料的關鍵,資料庫系統應提供對索引的原生支援。
- 強一致性:應用應當立即讀到提交到資料庫的資料。應避免漸近一致性資料模型(Eventually Consistent Model)導致的複雜應用開發。
- 企業級管理和整合:資料庫應當與企業的IT技術棧無縫的集合,滿足企業級的需求。組織需要資料庫是安全的、可監控的、自動化的,並且可與已有技術基礎架構、流程和人員(運維,DBA,分析師)整合。
上圖的右側,展示了MongoDB目標實現的NoSQL資料庫的技術,以滿足現代應用的需求:
- 靈活的資料模型:與傳統關係型資料庫相比,現代的NoSQL資料庫提供了靈活的資料模型,可以方便的儲存任何結構的資料,並且允許不停機且不影響效能的情況下修改Schema。
- 可擴充套件性和效能:NoSQL資料庫專注於可擴充套件性(Scalability),都有某種形式的分片(sharding)或分割槽(partitioning)。這使得NoSQL資料庫可以在商用硬體上水平擴充套件,獲得幾乎無限的高吞吐量和低延時。
- 無中斷全球部署:NoSQL設計用為持續可用系統,可為全球使用者提供一直的高質量的體驗。NoSQL資料庫被設計用於在眾多結點間執行,可在伺服器,機櫃,甚至跨地域的資料中心間自動同步資料。
MongoDB架構概覽
筆者暫時沒找到一張完整的架構圖可以體現MongoDB的元件和它們之間的關係。
MongoDB靈活儲存架構

儲存引擎是資料庫和硬體之間的介面,它負責處理用什麼資料結構儲存資料,以及如何寫入、刪除和讀取資料。不同的工作負載型別對於讀寫效能的需求不同,例如新聞網站需要大量的讀,而社交類網站需要大量的寫。MongoDB 3.0開始,提供了可插拔的儲存引擎API,使得使用者可以在MongoDB和第三方提供的多種儲存引擎之間切換。
在一個MongoDB複製集中,多種儲存引擎可以並存,可以滿足應用更復雜的需求。例如,使用In-memory儲存引擎進行低延時的操作,同時使用基於磁碟的儲存引擎完成持久化。
WiredTiger
目前MongoDB預設使用的是WiredTiger儲存引擎,WiredTiger是SleepyCat提供的一款開源資料引擎。通過使用現代程式設計技術,如Hazard指標和Lock-free演算法,WiredTiger實現了多核可擴充套件性。
《MongoDB實戰》的作者在書中對WiredTiger和老的儲存引擎做了MMAPv1比較測試,WiredTiger要節省85%的儲存空間,開啟壓縮後比WiredTiger節省90%;寫操作時優勢不明顯;從磁碟順序讀時,WiredTiger要快69%,開啟壓縮後比WiredTiger快68%。
三方儲存引擎
RocketsDB是Facebook開發的一款鍵值儲存資料庫,通過使用LSM樹引擎,RocketsDB適合於需要高速寫入效能的應用,如社交媒體。
In-memory儲存引擎可為實時分析應用提供極高的效能,MongoDB自帶的In-memory儲存引擎是企業高階版中才有的,Percona Server for MongoDB中提供了免費的In-memory儲存引擎,有需求的讀者可以試用。
複製——MongoDB的高可用方案
MongoDB提供了複製集(Replica Set)以提供資料保護、負載均衡和容災能力。複製集是一組配置成可自動同步資料和故障切換(Failover)的結點。早期版本MongoDB提供的主從(Master Slave)資料複製只支援資料同步,而不支援自動故障切換,已被複制集替代。MogoDB的Journaling日誌功能也提供了資料保護能力,與複製集相比,Journaling可以大幅提升故障後資料恢復的速度,常與複製集一起使用。雖然備份不能像複製一樣準實時進行,但是備份可以挽救邏輯錯誤,比如應用或運維人員誤刪除了資料,因此也需要在生成環境使用。
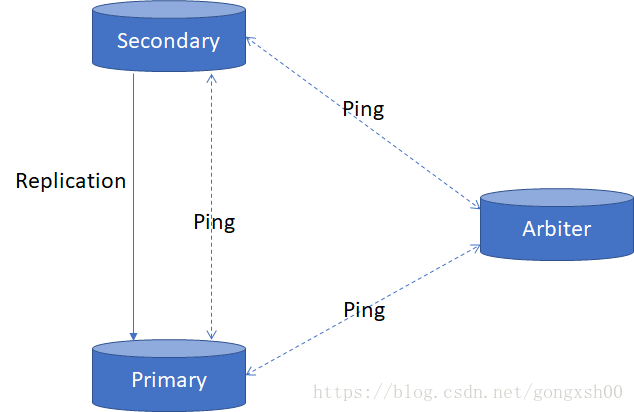
如圖所示,一個MongoDB複製集至少由3個節點組成,其中可寫可讀的主節點(Primary)有且僅有一個。副節點(Secondary)可以有一致多個,副結點使用長輪詢(Long Polling)技術準實時地從主節點local集合中獲取包含資料變化資訊的Oplog,應用於副結點庫,這個過程是非同步的,即複製故障不會影響主節點的讀寫。為了減少複製資料,複製集中還可以新增仲裁節點(Arbiter),仲裁節點參與主節點的選舉,但不從主節點複製資料。
複製集中的節點每隔2秒會向複製集中的其它節點發出心跳請求(Hearbeat),以檢測和維護複製集。MongoDB複製集中有一個重要的概念是多數集(Majority),指的是複製集中超過50%的節點構成的集合。當複製集中的節點或網路發生故障時,如果多數集中沒有主節點了,將在多數集中選舉新的主節點,同時不在多數集中的主節點將被降級為副節點。為了保持超過50%的節點,複製集中的節點數一般為奇數,而最小複製集由3個節點組成。
關於資料一致性
MongoDB規定,只有當資料被複制到多數集以後,一個寫操作才能被認為提交成功。發生故障導致沒有被複制到多數集的資料將被回滾。這樣就存在一種可能性,程式寫入資料時正常返回了,但因沒有複製到多數集,後續被回滾掉了。MongoDB提供了介面可以細粒度的控制複製集的讀寫,可以在寫入關鍵資料時設定資料被複制到多數集後再返回,可以避免這個問題。
水平分割槽——MongoDB的可擴充套件架構
水平分割槽(Sharding)指的是將資料庫分為更小塊,以支援更大量的資料量儲存和負載。MongoDB提供了對水平分割槽的支援,對於應用是透明的,即應用可以向訪問單個MongoDB資料庫一樣訪問一個MongoDB分割槽叢集(Sharded Cluster),如圖,MongoDB分割槽叢集由以下的元件構成:

- 分割槽(Shards):儲存應用資料的MongoDB程序。在分割槽叢集中,應用不直接連線到分割槽。
- mongos路由器(router):按照分割槽元資料將應用的操作路由到分割槽。為了提高效率,路由器中快取了分割槽元資料。
- 配置伺服器(Config server):持久化儲存分割槽叢集的元資料,包括哪些資料子集歸屬於哪個分割槽。
最小高可用部署
為了保持MongoDB的高可用性,一個最小的分割槽叢集環境需要四臺伺服器,如下圖所示:

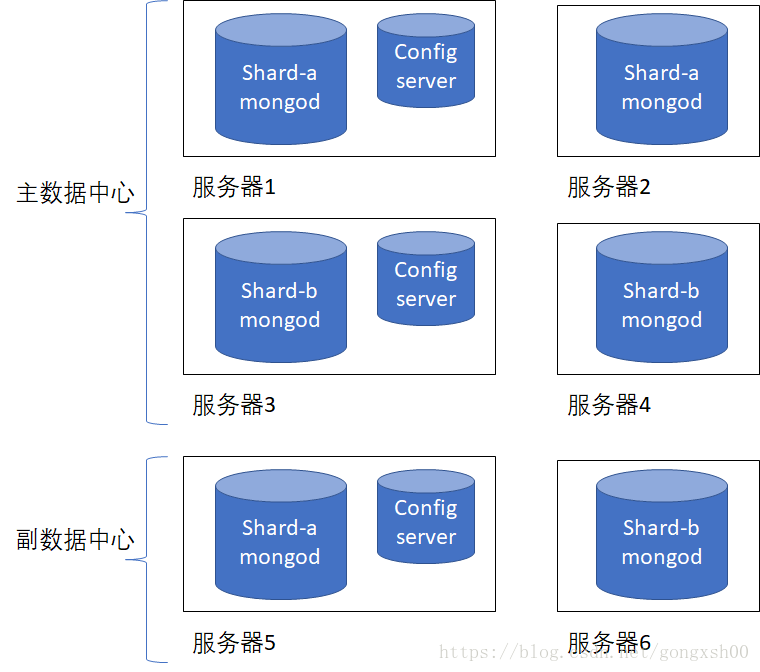
最小高可用+容災部署
為了支援容災,資料應當至少複製到一個異地的資料中心,如圖所示,在增加容災需求以後,部署一個最小的分割槽叢集至少需要六臺伺服器:
分割槽鍵的選擇
在一個MongoDB分割槽叢集上建立一個新的資料庫時,新資料庫會被分配到一個分割槽中,而不會自動水平擴充套件到整個分割槽叢集。需要配置允許對資料庫上的集合分割槽,併為集合設定分割槽鍵(Shard Key),才能達到分散式儲存的效果。分割槽鍵一旦選擇則無法修改,而不當的選擇分割槽鍵,可能引起叢集儲存或負載不均衡、查詢效率低等問題,因此要在規劃時合理的選擇分割槽鍵。
MongoDB的水平分割槽是基於分割槽鍵的範圍的,當DBA設定了集合的分割槽鍵以後,MongoDB按照分割槽鍵自動將集合劃分為資料大塊(Chunk),劃分時是基於值範圍的,如Abbot->Dayton分為一個大塊,Dayton->Harris分為一個大塊。隨著資料的增多,(預設大塊大於64MB時)MongoDB會將一個大塊切分為兩個大塊,MongoDB也會將大塊從大塊數量較多的分割槽遷移到數量較少的分割槽,以保持整個分割槽叢集的平衡。
下面來結合兩個具體的例子看看如何選擇分割槽鍵:
例1:有一個數據集合中儲存了使用者的Office文件,每個使用者都有唯一的userId。首先的想法是使用mongodb文件的_id作為分割槽鍵,_id是全域性唯一的,可以避免產生無法分割的大塊問題,但_id是一個遞增序列,缺點是因分割槽是基於範圍的,寫操作將集中於最後的一個大塊,會造成叢集的負載不均衡;使用者的userId是查詢使用者文件時的常用條件,也是一個分割槽鍵的候選,但以userId為分割槽鍵時,如果一個使用者儲存了大量的文件(如超過10GB),這些文件因分割槽鍵userId相同只能存在於一個分割槽,會造成叢集的儲存不均衡。在這個案例中,使用userId+_id的組合分割槽鍵是一個理想的選擇,可以對前兩個方案取長補短。
例2:有一個數據集合中儲存了使用者的郵件,郵件有一個發件人,一致多個收件人。可以發件人的userId來作為分割槽鍵,但是在收件人收郵件時,需要查詢所有的分割槽以找到收件人的所有郵件。反之,也可以以收件人的userId來作為分割槽鍵,但是需要為每一位收件人複製一份郵件的副本,會影響寫的速度並消耗更多的儲存。在這個案例中,因為接收郵件比傳送郵件是更高頻的場景,較理想方案是使用收件人的userId來作為分割槽鍵。
強調一點,即使使用了合理的分割槽鍵,也要為查詢建立適當的索引,分割槽鍵不能代替索引提供的能力。
參考資料
1. https://www.mongodb.com/mongodb-architecture
2. https://www.safaribooksonline.com/library/view/mongodb-in-action/9781617291609/