
哈夫曼編碼計算帶權路徑長度問題
哈夫曼樹,又稱最優二叉樹,是一類帶權路徑長度最短的樹。
也就是根節點到節點的中的長度最小,當然條件就是,每條路徑都是有權重的,
所謂樹的帶權路徑長度,就是樹中所有的葉結點的權值乘上其到根結點的 路徑長度(若根結點為0層,葉結點到根結點的路徑長度為葉結點的層數)。樹的帶權路徑長度記為WPL= (W1*L1+W2*L2+W3*L3+…+Wn*Ln)
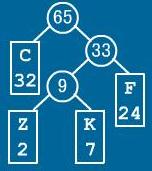
此時WPL=32×1+24×2+2×3+7×3
相關推薦
哈夫曼編碼計算帶權路徑長度問題
哈夫曼樹,又稱最優二叉樹,是一類帶權路徑長度最短的樹。 也就是根節點到節點的中的長度最小,當然條件就是,每條路徑都是有權重的, 所謂樹的帶權路徑長度,就是樹中所有的葉結點的權值乘上其到根結點的 路徑長度(若根結點為0層,葉結點到根結點的路徑長度為葉結點的層數)。樹的帶
哈夫曼樹與帶權路徑長度計算
假設我們一個權重為1,7,3,13,12,15,24怎麼樣畫出哈夫曼樹和計算帶權路徑長度。 首先,選出最小的兩個權重值,這裡是1,3(矩形表示葉子節點,圓表示根節點也是兩個葉子節點的和)如圖: 然後,選出第三小的7,算出父節點,如圖: 依次類推: 當11
用n個帶權值構造的哈夫曼樹的帶權路徑長度
//哈夫曼樹 #include<cstdio> #include<cstring> #include<iostream> #include<algorithm&
給定結點權值,求哈夫曼樹的帶權路徑長度和
1.哈夫曼樹概念一棵樹中,從任意一個結點到達另一個結點的通路叫做路徑,該路徑包含的邊的個數稱為路徑長度,每個結點帶有的表示某種意義的值成為權值。從根結點到葉子結點的路徑長度乘以葉子節點權值,得到的值為該節點的帶權路徑長度,樹中所有葉子節點的帶權路徑長度之和稱為該樹的帶權路徑長
哈夫曼編碼計算問題以及報文解析
已知某字串S中共有8種字元,各種字元分別出現2次、1次、4次、5次、7次、3次、4次和9次,對該字串進行哈夫曼,問該字串的編碼至少有多少位? 我們首先構造一個哈夫曼樹: 其中編碼位數就是出現 次數×編碼位(bit) 也就是2×5+1×5+4×3+5×3+
哈夫曼樹的構建、編碼以及帶權路徑長計算
給定n個權值作為n個葉子結點,構造一棵二叉樹,若該樹的帶權路徑長度達到最小,稱這樣的二叉樹為最優二叉樹,也稱為哈夫曼樹(Huffman Tree)。哈夫曼樹是帶權路徑長度最短的樹,權值較大的結點離根較近。 構造哈夫曼樹的演算法如下:
哈夫曼樹結構和帶權路徑長度計算
什麼是哈夫曼樹呢? 哈夫曼樹是一種帶權路徑長度最短的二叉樹,也稱為最優二叉樹。下面用一幅圖來說明。 它們的帶權路徑長度分別為: 圖a: WPL=5*2+7*2+2*2+13*2=54 圖b: WPL=5*3+2*3+7*2+13*1=48 可見,圖b的
資料結構——哈夫曼樹求最小WPL(樹的帶權路徑長度)
給出程式碼與註釋 #include<queue> #include<iostream> using namespace std; //代表小堆頂的優先佇列 priority_queue<long long, vector<long long>, gre
哈夫曼樹建立與求最短帶權路徑長度
#include<stdio.h> #include<stdlib.h> #define n 7 //假設有七個節點元素 struct Element { int flag; int weig
構造哈夫曼樹並求帶權路徑長度(c語言/CodeBlocks實現)
#include <iostream> #include <stdio.h> #include <stdlib.h> #include <math.h>
哈夫曼樹 和 樹的帶權路徑長度
樹的帶權路徑長度(Weighted Path Length of Tree):定義為樹中所有葉結點的帶權路徑長度之和。 結點的帶權路徑長度:結點到樹根之間的路徑長度與該結點上權的乘積。 哈夫曼樹是一種帶權路徑長度最短的二叉樹,也稱為最優二叉樹。 例:對於給定的一組
計算哈夫曼編碼長度
#include <iostream>#include <stdio.h>#include <stdlib.h>#include <string.h>#include <sys/types.h>#include <sys/stat.h>#
哈夫曼編碼的長度計算問題
問題是: 已知某字串S中共有8種字元,各種字元分別出現2次、1次、4次、5次、7次、3次、4次和9次,對該字串進行哈夫曼,問該字串的編碼至少有多少位? 我們首先構造一個哈夫曼樹: 其中編碼位
哈夫曼編碼(Huffman coding)的那些事,(編碼技術介紹和程序實現)
信號 truct 依次 while 交換 需要 .text 示例 system 前言 哈夫曼編碼(Huffman coding)是一種可變長的前綴碼。哈夫曼編碼使用的算法是David A. Huffman還是在MIT的學生時提出的,並且在1952年發表了名為《
哈夫曼編碼解碼 C++實現
錯誤 urn using 過程 簡單 cin n) struct ren 哈夫曼編碼是一個通過哈夫曼樹進行的一種編碼,一般情況下,以字符:‘0’與‘1’表示。編碼的實現過程很簡單,只要實現哈夫曼樹,通過遍歷哈夫曼樹,這裏我們從每一個葉子結點開始向上遍歷,如果該結點為父節點的
哈夫曼編碼
http sdn chm cstring htc 位數 child 個數 ostream 在電文傳輸中,需要將電文中出現的每個字符進行二進制編碼。在設計編碼時需要遵守兩個原則: (1)發送方傳輸的二進制編碼,到接收方解碼後必須具有唯一性,即解碼結果與發送方發送的電文完全一樣
【BZOJ 4198】[Noi2015]荷馬史詩 哈夫曼編碼
clu tor space zoj col 具體實現 %d sca bool 合並果子加強版....... 哈夫曼樹是一種特別的貪心算法,它的作用是使若幹個點合並成一棵樹,每次合並新建一個節點連接兩個合並根並形成一個新的根,使葉子節點的權值乘上其到根的路徑長的和最短(等價
轉載:哈夫曼樹的構造和哈夫曼編碼(C++代碼實現)
作者 pos blank 字符 element start man null == 作者:qiqifanqi 原文:http://blog.csdn.net/qiqifanqi/article/details/6038822 #include<stdio.h>
【視頻編解碼·學習筆記】7. 熵編碼算法:基礎知識 & 哈夫曼編碼
html 節點 表示 效率 article tchar vector nod code 一、熵編碼概念: 熵越大越混亂 信息學中的熵: 用於度量消息的平均信息量,和信息的不確定性 越是隨機的、前後不相關的信息,其熵越高 信源編碼定理: 說明了香農熵越信源符號概率之間的
哈夫曼編碼大全
cad 節點 pos ada 哈夫曼 描述 多少 一個數 關於 題目: 哈夫曼編碼大全 描述: 關於哈夫曼樹的建立,編碼,解碼。 輸入 第一行輸入數字N,代表總共有多少個字符以及權值 第二第三行分別是一行字符串,以及每個字符對應的權值 接下來輸入一個數M,表示接下來有M