
ART 虛擬機器 — Interpreter 模式
前言
ART 虛擬機器執行 Java 方法主要有兩種模式:quick code 模式和 Interpreter 模式
- quick code 模式:執行 arm 彙編指令
- Interpreter 模式:由直譯器解釋執行 Dalvik 位元組碼
本篇文章就來講一下,Interpreter 模式是如何執行的(基於 Android 8.1)
一、 Interpreter 模式
點選檢視大圖
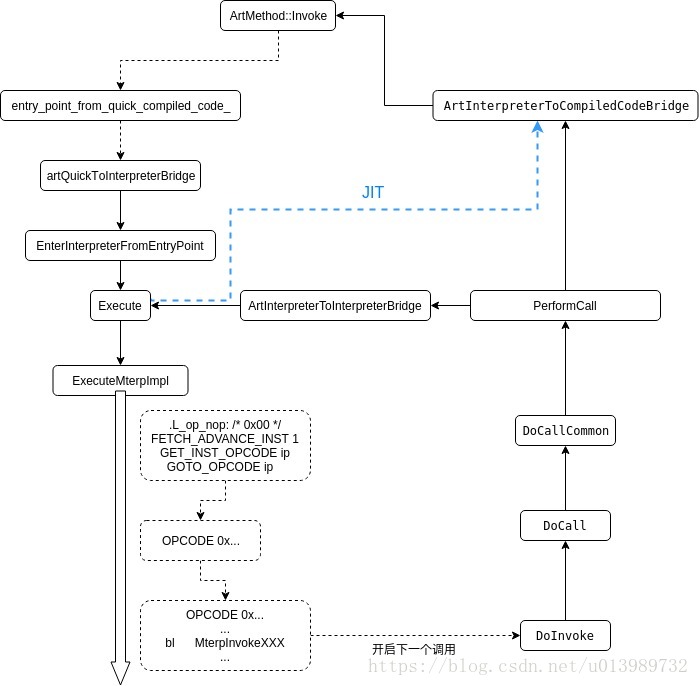
上圖是將斷點打在 art_quick_invoke_stub 時出現的一段 backtraces,這段 backtraces 很好地描述出了 Interpreter 模式是如何運轉的,以及 quick code 模式與 Interpreter 模式之間是如何切換的

1.1 art_quick_to_interpreter_bridge
從 f 19、f 18 可以看到由 quick code 模式進入 Interpreter 模式需要通過 art_quick_to_interpreter_bridge 這個 bridge,
點選檢視大圖
從 f 18 可以看到,artQuickToInterpreterBridge 會通過呼叫 interpreter::EnterInterpreterFromEntryPoint(self, code_item, shadow_frame); 來進入 Interpreter 模式,檢視一下 EnterInterpreterFromEntryPoint 的定義:

JValue EnterInterpreterFromEntryPoint(Thread* self, const DexFile::CodeItem* code_item, ShadowFrame* shadow_frame) { DCHECK_EQ(self, Thread::Current()); bool implicit_check = !Runtime::Current()->ExplicitStackOverflowChecks(); if (UNLIKELY(__builtin_frame_address(0) < self->GetStackEndForInterpreter(implicit_check))) { ThrowStackOverflowError(self); return JValue(); } jit::Jit* jit = Runtime::Current()->GetJit(); if (jit != nullptr) { jit->NotifyCompiledCodeToInterpreterTransition(self, shadow_frame->GetMethod()); } return Execute(self, code_item, *shadow_frame, JValue()); }
可以看到其會呼叫 Execute() 函式,結合上面的 backtraces,我們可以將 Execute() 函式看作是 Interpreter 模式的起點
1.2 Execute()
art/runtime/interpreter/interpreter.cc
enum InterpreterImplKind {
kSwitchImplKind, // Switch-based interpreter implementation.
kMterpImplKind // Assembly interpreter
};
static constexpr InterpreterImplKind kInterpreterImplKind = kMterpImplKind; // 預設使用 Mterp 型別的實現
static inline JValue Execute(
Thread* self,
const DexFile::CodeItem* code_item,
ShadowFrame& shadow_frame,
JValue result_register,
bool stay_in_interpreter = false) REQUIRES_SHARED(Locks::mutator_lock_) {
...
if (LIKELY(shadow_frame.GetDexPC() == 0)) { // Entering the method, but not via deoptimization.
if (kIsDebugBuild) {
self->AssertNoPendingException();
}
instrumentation::Instrumentation* instrumentation = Runtime::Current()->GetInstrumentation();
ArtMethod *method = shadow_frame.GetMethod();
...
if (!stay_in_interpreter) {
jit::Jit* jit = Runtime::Current()->GetJit();
if (jit != nullptr) {
jit->MethodEntered(self, shadow_frame.GetMethod());
if (jit->CanInvokeCompiledCode(method)) { // 1、jit 不為 nullptr,並且 jit 編譯出了對應的 quick code,那麼 ArtInterpreterToCompiledCodeBridge
JValue result;
// Pop the shadow frame before calling into compiled code.
self->PopShadowFrame();
// Calculate the offset of the first input reg. The input registers are in the high regs.
// It's ok to access the code item here since JIT code will have been touched by the
// interpreter and compiler already.
uint16_t arg_offset = code_item->registers_size_ - code_item->ins_size_;
ArtInterpreterToCompiledCodeBridge(self, nullptr, &shadow_frame, arg_offset, &result);
// Push the shadow frame back as the caller will expect it.
self->PushShadowFrame(&shadow_frame);
return result;
}
}
}
}
shadow_frame.GetMethod()->GetDeclaringClass()->AssertInitializedOrInitializingInThread(self);
// Lock counting is a special version of accessibility checks, and for simplicity and
// reduction of template parameters, we gate it behind access-checks mode.
ArtMethod* method = shadow_frame.GetMethod();
DCHECK(!method->SkipAccessChecks() || !method->MustCountLocks());
bool transaction_active = Runtime::Current()->IsActiveTransaction();
if (LIKELY(method->SkipAccessChecks())) {
// Enter the "without access check" interpreter.
if (kInterpreterImplKind == kMterpImplKind) {
if (transaction_active) {
// No Mterp variant - just use the switch interpreter.
return ExecuteSwitchImpl<false, true>(self, code_item, shadow_frame, result_register,
false);
} else if (UNLIKELY(!Runtime::Current()->IsStarted())) {
...
} else {
while (true) {
...
bool returned = ExecuteMterpImpl(self, code_item, &shadow_frame, &result_register);
if (returned) {
return result_register;
} else {
// Mterp didn't like that instruction. Single-step it with the reference interpreter.
result_register = ExecuteSwitchImpl<false, false>(self, code_item, shadow_frame,
result_register, true);
if (shadow_frame.GetDexPC() == DexFile::kDexNoIndex) {
// Single-stepped a return or an exception not handled locally. Return to caller.
return result_register;
}
}
}
}
} else {
...
}
} else {
// Enter the "with access check" interpreter.
if (kInterpreterImplKind == kMterpImplKind) {
// No access check variants for Mterp. Just use the switch version.
if (transaction_active) {
return ExecuteSwitchImpl<true, true>(self, code_item, shadow_frame, result_register,
false);
} else {
return ExecuteSwitchImpl<true, false>(self, code_item, shadow_frame, result_register,
false);
}
} else {
DCHECK_EQ(kInterpreterImplKind, kSwitchImplKind);
if (transaction_active) {
return ExecuteSwitchImpl<true, true>(self, code_item, shadow_frame, result_register,
false);
} else {
return ExecuteSwitchImpl<true, false>(self, code_item, shadow_frame, result_register,
false);
}
}
}
}
從上面可以看到,Execute() 的作用就是:
- 如果有 jit,並且 jit 編譯出了對應 method 的 quick code,那麼選擇通過 ArtInterpreterToCompiledCodeBridge 這個去執行對應的 quick code
- 如果上面的條件不滿足,那麼根據情況選擇 Mterp 或者 Switch 型別的直譯器實現來解釋執行對應的 Dalvik 位元組碼
因為預設使用 Mterp 型別的 Interpreter 實現,所以大多數情況下會呼叫 ExecuteMterpImpl() 函式來解釋執行 Dalvik 位元組碼,下面來重點看一下 ExecuteMterpImpl() 的實現
1.3 ExecuteMterpImpl
art/runtime/interpreter/mterp/out/mterp_arm64.S
/* During bringup, we'll use the shadow frame model instead of xFP */
/* single-purpose registers, given names for clarity */
#define xPC x20
#define xFP x21
#define xSELF x22
#define xINST x23
#define wINST w23
#define xIBASE x24
#define xREFS x25
#define wPROFILE w26
#define xPROFILE x26
#define ip x16
#define ip2 x17
.macro EXPORT_PC
str xPC, [xFP, #OFF_FP_DEX_PC_PTR]
.endm
.macro FETCH_INST
ldrh wINST, [xPC]
.endm
.macro GOTO_OPCODE reg
add \reg, xIBASE, \reg, lsl #7
br \reg
.endm
.macro GET_INST_OPCODE reg
and \reg, xINST, #255
.endm
/*
* Interpreter entry point.
* On entry:
* x0 Thread* self/
* x1 code_item
* x2 ShadowFrame
* x3 JValue* result_register
*
*/
.global ExecuteMterpImpl
.type ExecuteMterpImpl, %function
.balign 16
ExecuteMterpImpl:
.cfi_startproc
SAVE_TWO_REGS_INCREASE_FRAME xPROFILE, x27, 80
SAVE_TWO_REGS xIBASE, xREFS, 16
SAVE_TWO_REGS xSELF, xINST, 32
SAVE_TWO_REGS xPC, xFP, 48
SAVE_TWO_REGS fp, lr, 64
add fp, sp, #64
/* Remember the return register */
str x3, [x2, #SHADOWFRAME_RESULT_REGISTER_OFFSET]
/* Remember the code_item */
str x1, [x2, #SHADOWFRAME_CODE_ITEM_OFFSET]
/* set up "named" registers */
mov xSELF, x0
ldr w0, [x2, #SHADOWFRAME_NUMBER_OF_VREGS_OFFSET]
add xFP, x2, #SHADOWFRAME_VREGS_OFFSET // point to vregs.
add xREFS, xFP, w0, lsl #2 // point to reference array in shadow frame
ldr w0, [x2, #SHADOWFRAME_DEX_PC_OFFSET] // Get starting dex_pc.
add xPC, x1, #CODEITEM_INSNS_OFFSET // Point to base of insns[]
add xPC, xPC, w0, lsl #1 // Create direct pointer to 1st dex opcode
EXPORT_PC
/* Starting ibase */
ldr xIBASE, [xSELF, #THREAD_CURRENT_IBASE_OFFSET]
/* Set up for backwards branches & osr profiling */
ldr x0, [xFP, #OFF_FP_METHOD]
add x1, xFP, #OFF_FP_SHADOWFRAME
bl MterpSetUpHotnessCountdown
mov wPROFILE, w0 // Starting hotness countdown to xPROFILE
/* start executing the instruction at rPC */
FETCH_INST // load wINST from rPC
GET_INST_OPCODE ip // extract opcode from wINST
GOTO_OPCODE ip // jump to next instruction
/* NOTE: no fallthrough */
在 gdb 中檢視上面這一段即為:
Dump of assembler code for function ExecuteMterpImpl:
0x000000790e52e280 <+0>: stp x26, x27, [sp,#-80]!
0x000000790e52e284 <+4>: stp x24, x25, [sp,#16]
0x000000790e52e288 <+8>: stp x22, x23, [sp,#32]
0x000000790e52e28c <+12>: stp x20, x21, [sp,#48]
0x000000790e52e290 <+16>: stp x29, x30, [sp,#64]
0x000000790e52e294 <+20>: add x29, sp, #0x40
/* Remember the return register */
0x000000790e52e298 <+24>: str x3, [x2,#16]
/* Remember the code_item */
0x000000790e52e29c <+28>: str x1, [x2,#32]
/* set up "named" registers */
0x000000790e52e2a0 <+32>: mov x22, x0
0x000000790e52e2a4 <+36>: ldr w0, [x2,#48]
0x000000790e52e2a8 <+40>: add x21, x2, #0x3c
0x000000790e52e2ac <+44>: add x25, x21, x0, uxtx #2
0x000000790e52e2b0 <+48>: ldr w0, [x2,#52] // w0 指向 SHADOWFRAME 的 dex_pc_
0x000000790e52e2b4 <+52>: add x20, x1, #0x10 // xPC 指向 CodeItem 中 bytecode array 的起點, 即 base of insns[]
0x000000790e52e2b8 <+56>: add x20, x20, x0, uxtx #1 // xPC 指向第一條 dex opcode
0x000000790e52e2bc <+60>: stur x20, [x21,#-36]
/* Starting ibase */
0x000000790e52e2c0 <+64>: ldr x24, [x22,#1736]
0x000000790e52e2c4 <+68>: ldur x0, [x21,#-52]
0x000000790e52e2c8 <+72>: sub x1, x21, #0x3c
0x000000790e52e2cc <+76>: bl 0x790e52e02c <MterpSetUpHotnessCountdown(art::ArtMethod*, art::ShadowFrame*)>
0x000000790e52e2d0 <+80>: mov w26, w0
/* start executing the instruction at rPC */
0x000000790e52e2d4 <+84>: ldrh w23, [x20] // Fetch the next instruction from xPC into w23
0x000000790e52e2d8 <+88>: and x16, x23, #0xff // 將 instruction's opcode field 放到特殊暫存器 x16 當中
0x000000790e52e2dc <+92>: add x16, x24, x16, lsl #7
0x000000790e52e2e0 <+96>: br x16 // Begin executing the opcode in x16
0x000000790e52e2e4 <+100>: nop
1.4
執行 opcode,每個 opcode 以 128 位元組對齊,並且絕大多數 opcode 都會包含如下指令:
FETCH_ADVANCE_INST 2 // 此處的數字可以是其他的,譬如 1、3
GET_INST_OPCODE ip
GOTO_OPCODE ip
看一下 FETCH_ADVANCE_INST 的定義:
.macro FETCH_ADVANCE_INST count
ldrh wINST, [xPC, #((\count)*2)]!
.endm
這幾條指令的作用是,移動 xPC 到下一條 instruction,並將移動後的 xPC 的值 load 到 wINST 中,然後跳轉去執行 opcode
例如:
/* ------------------------------ */
.balign 128
.L_op_nop: /* 0x00 */
/* File: arm64/op_nop.S */
FETCH_ADVANCE_INST 1 // advance to next instr, load rINST
GET_INST_OPCODE ip // ip<- opcode from rINST
GOTO_OPCODE ip // execute it
/* ------------------------------ */
這條 opcode 相當於什麼都沒做,然後移動 xPC,再去執行下一條 instruction;
通過上面這些分析,我們可以看出對 Dalvik 位元組碼解釋執行的執行模式:
- 在 Mterp 直譯器當中維護了一種對應關係:opcode 與實現這個 opcode 的彙編指令的對應關係
- 我們在解釋執行的時候,實際上是取出一條指令,通過 opcode 找到對應的彙編實現,然後執行
- 大部分 opcode 中都會包含取出下一條 instruction、然後跳轉執行的操作,形成一個迴圈
- 一些帶有 invoke 操作的 opcode 將會開啟下一個 Java 呼叫
例如,圖1中的 f 16:
/* ------------------------------ */
.balign 128
.L_op_invoke_virtual_quick: /* 0xe9 */
/* File: arm64/op_invoke_virtual_quick.S */
/* File: arm64/invoke.S */
/*
* Generic invoke handler wrapper.
*/
/* op vB, {vD, vE, vF, vG, vA}, [email protected] */
/* op {vCCCC..v(CCCC+AA-1)}, [email protected] */
.extern MterpInvokeVirtualQuick
EXPORT_PC
mov x0, xSELF
add x1, xFP, #OFF_FP_SHADOWFRAME
mov x2, xPC
mov x3, xINST
bl MterpInvokeVirtualQuick
cbz w0, MterpException
FETCH_ADVANCE_INST 3
bl MterpShouldSwitchInterpreters
cbnz w0, MterpFallback
GET_INST_OPCODE ip
GOTO_OPCODE ip
/* ------------------------------ */
從圖1中可以看到,其後會經過:
MterpInvokeVirtualQuick
|_
DoInvokeVirtualQuick
|_
DoCall
|_
DoCallCommon
|_
PerformCall
|_
ArtInterpreterToInterpreterBridge
|_
Execute
的呼叫棧開啟下一個 method 的解釋執行
1.4.2 PerformCall
art/runtime/common_dex_operations.h
inline void PerformCall(Thread* self,
const DexFile::CodeItem* code_item,
ArtMethod* caller_method,
const size_t first_dest_reg,
ShadowFrame* callee_frame,
JValue* result,
bool use_interpreter_entrypoint)
REQUIRES_SHARED(Locks::mutator_lock_) {
if (LIKELY(Runtime::Current()->IsStarted())) {
if (use_interpreter_entrypoint) {
interpreter::ArtInterpreterToInterpreterBridge(self, code_item, callee_frame, result);
} else {
interpreter::ArtInterpreterToCompiledCodeBridge(
self, caller_method, callee_frame, first_dest_reg, result);
}
} else {
interpreter::UnstartedRuntime::Invoke(self, code_item, callee_frame, result, first_dest_reg);
}
}
可以看到在上面的呼叫棧中,在執行 PerformCall 方法時會判斷 use_interpreter_entrypoint 是否為 true,從而選擇是跳轉到 ArtInterpreterToInterpreterBridge 進行解釋執行還是通過 ArtInterpreterToCompiledCodeBridge 跳轉到被呼叫 method 的 entry_point_from_quick_compiled_code_ 入口
1.4.3 DoCallCommon
art/runtime/interpreter/interpreter_common.cc
template <bool is_range,
bool do_assignability_check>
static inline bool DoCallCommon(ArtMethod* called_method,
Thread* self,
ShadowFrame& shadow_frame,
JValue* result,
uint16_t number_of_inputs,
uint32_t (&arg)[Instruction::kMaxVarArgRegs],
uint32_t vregC) {
bool string_init = false;
...
// Compute method information.
const DexFile::CodeItem* code_item = called_method->GetCodeItem();
// Number of registers for the callee's call frame.
uint16_t num_regs;
// 1、是否使用 interpreter 模式
const bool use_interpreter_entrypoint = !Runtime::Current()->IsStarted() ||
ClassLinker::ShouldUseInterpreterEntrypoint(
called_method,
called_method->GetEntryPointFromQuickCompiledCode());
if (LIKELY(code_item != nullptr)) {
...
} else {
DCHECK(called_method->IsNative() || called_method->IsProxyMethod());
num_regs = number_of_inputs;
}
// 2、Hack for String init:
...
// Parameter registers go at the end of the shadow frame.
DCHECK_GE(num_regs, number_of_inputs);
size_t first_dest_reg = num_regs - number_of_inputs;
DCHECK_NE(first_dest_reg, (size_t)-1);
// 3、Allocate shadow frame on the stack.
const char* old_cause = self->StartAssertNoThreadSuspension("DoCallCommon");
ShadowFrameAllocaUniquePtr shadow_frame_unique_ptr =
CREATE_SHADOW_FRAME(num_regs, &shadow_frame, called_method, /* dex pc */ 0);
ShadowFrame* new_shadow_frame = shadow_frame_unique_ptr.get();
// 4、Initialize new shadow frame by copying the registers from the callee shadow frame.
...
// 5、PerformCall
PerformCall(self,
code_item,
shadow_frame.GetMethod(),
first_dest_reg,
new_shadow_frame,
result,
use_interpreter_entrypoint);
if (string_init && !self->IsExceptionPending()) {
SetStringInitValueToAllAliases(&shadow_frame, string_init_vreg_this, *result);
}
return !self->IsExceptionPending();
}
可以看到在 DoCallCommon 中主要做了5件事,詳細的細節暫時先不關注,主要看一下 use_interpreter_entrypoint,其是通過 ClassLinker::ShouldUseInterpreterEntrypoint 方法取得的值
1.4.4 ClassLinker::ShouldUseInterpreterEntrypoint
art/runtime/class_linker.cc
bool ClassLinker::ShouldUseInterpreterEntrypoint(ArtMethod* method, const void* quick_code) {
if (UNLIKELY(method->IsNative() || method->IsProxyMethod())) {
return false;
}
if (quick_code == nullptr) {
return true;
}
Runtime* runtime = Runtime::Current();
instrumentation::Instrumentation* instr = runtime->GetInstrumentation();
if (instr->InterpretOnly()) {
return true;
}
if (runtime->GetClassLinker()->IsQuickToInterpreterBridge(quick_code)) {
// Doing this check avoids doing compiled/interpreter transitions.
return true;
}
if (Dbg::IsForcedInterpreterNeededForCalling(Thread::Current(), method)) {
// Force the use of interpreter when it is required by the debugger.
return true;
}
if (runtime->IsJavaDebuggable()) {
// For simplicity, we ignore precompiled code and go to the interpreter
// assuming we don't already have jitted code.
// We could look at the oat file where `quick_code` is being defined,
// and check whether it's been compiled debuggable, but we decided to
// only rely on the JIT for debuggable apps.
jit::Jit* jit = Runtime::Current()->GetJit();
return (jit == nullptr) || !jit->GetCodeCache()->ContainsPc(quick_code);
}
if (runtime->IsNativeDebuggable()) {
DCHECK(runtime->UseJitCompilation() && runtime->GetJit()->JitAtFirstUse());
// If we are doing native debugging, ignore application's AOT code,
// since we want to JIT it (at first use) with extra stackmaps for native
// debugging. We keep however all AOT code from the boot image,
// since the JIT-at-first-use is blocking and would result in non-negligible
// startup performance impact.
return !runtime->GetHeap()->IsInBootImageOatFile(quick_code);
}
return false;
}
可以看到上面每個判斷條件都會作為是否使用 Interpreter 模式的一個依據,我們主要關注一下下面幾個條件:
- quick_code == nullptr
- instr->InterpretOnly()
- IsQuickToInterpreterBridge(quick_code)
- ……
當上面這幾個條件有一個滿足時,ShouldUseInterpreterEntrypoint 就會返回 true,使用 Interpreter 模式
二、總結
Interpreter 模式的執行流程如下所示:
相關推薦
ART 虛擬機器 — Interpreter 模式
前言 ART 虛擬機器執行 Java 方法主要有兩種模式:quick code 模式和 Interpreter 模式 quick code 模式:執行 arm 彙編指令 Interpreter 模式:由直譯器解釋執行 Dalvik 位元組碼 本篇文章就來講一
Android上的ART虛擬機器
本會講解Android上的ART虛擬機器。 我的部落格中,還有另外兩篇關於Android虛擬機器的文章也可以配套閱讀: Android上的Dalvik虛擬機器 Android上ART虛擬機器 從Android 5.0(Lollipop)開始,Android Runtime(下文簡稱ART)
Java方法在art虛擬機器中的執行
前言 ART 虛擬機器執行 Java 方法主要有兩種模式:quick code 模式和 Interpreter 模式 quick code 模式:執行 arm 彙編指令 Interpreter 模式:由直譯器解釋執行 Dalvik 位元組碼 在之前的文章
Android 6.0中art虛擬機器編譯dex時已完全放棄使用LLVM
記得在Android 4.4釋出的時候,Google正式引入了稱做ART(Android Run Time)的虛擬機器,用來取代傳統的Dalvik虛擬機器。 ART虛擬機器最大的特點就是,將程式碼優化的過程從Davlik的JIT(Just In Time)模式轉換成了AOT
用於Android ART虛擬機器JNI呼叫的NativeBridge介紹
有一個專案叫做Android-X86,它是一個可以在X86平臺上執行的Android系統。目前許多市面上銷售的Intel Atom處理器的平板電腦,就是使用的這個系統。對於普通用Java程式碼編寫的程式來說,理論上在Android-X86平臺上執行是沒有任何問題的。但是,如
虛擬機器網路模式
https://www.cnblogs.com/xuan52rock/p/5295069.html 橋接模式 """ 宿主機,宿主機所在區域網內的主機 虛擬機器 如果虛擬機器橋接模式, 那麼虛擬機器和宿主機 和 其他主機 ,同在一個區域網內 VMware橋接模式,也就是將虛擬機器的
mac下連線VirtualBox虛擬機器(NAT模式)
選擇設定 -> 網路 -> 高階 -> 埠設定 Settings -> Network -> Advanced -> Port Forwardings 填寫如圖所示: 然後就可以開始連線! ssh -p 2222
【轉載】VMware虛擬機器nat模式連不上網
我的虛擬機器總是各種連不上網,每次都要折騰一番。現在我把虛擬機器連不上網的原因總體排查一下,按照流程一步步來,基本上可以解決大部分人的問題。首先,在VMware的編輯->虛擬網路編輯器重新建立NAT網路(之前的要刪掉,新建的同樣選擇VMnet8就可以)。如果還不能上網,
虛擬機器NAT模式不能ping通物理機的解決方法
第一次遇到這個問題的解決方法是恢復了一下VM的虛擬網路編輯器恢復了預設設定 第二次又出現了這個問題我真的不想再這樣解決了,因為如果恢復預設設定它會把你自定義的網路配置刪除,再次配置又怕麻煩。 於是想了想,出現這個Nat不能PING通物理機的原因究竟是什麼?把根本問題解決了
linux 虛擬機器NAT模式網路配置
NAT模式的具體配置 NAT方式:虛擬機器可以上外網,可以訪問宿主計算機所在網路的其他計算機(反之不行)。 1.1.1. 檢視虛擬機器的網路引數 1) 開啟虛擬機器,選擇選單“編輯”》“編輯虛擬網路”,如下圖: 2) 選中列表
linux下kvm虛擬機器nat模式下上不了網
1、物理機開啟路由轉發功能: 有ip的情況下能ping通閘道器但是ping不通DNS: vim /etc/sysctl.conf 末行新增: net.ipv4.ip_forward=1 sysctl
虛擬機器NAT模式的網路設定
一、原理部分 1.我們都曉得,各電腦連線同一個交換機,才能同處於一個網段,進而相互通訊。由此可以總結相互通訊的條件,即: ① 把各個主機的網絡卡連線到同一個交換機(同一個網路) ②各個網絡卡的ip地址設定為同一個網段 2.虛擬機器安裝好後 ①虛擬機器上會有3個虛擬的交換機(
(十二)Android 系統啟動原理(art 虛擬機器)
一、虛擬機器的啟動 Android 是一個 Linux 的虛擬機器,當虛擬機器啟動的時候,會執行手機根目錄下的 init.rc(實際上就是 .sh 檔案) 這個可執行檔案。 在 init.rc 中,有一行 on init 執行命令。這是呼叫 in
vmware 虛擬機器 nat模式設定靜態ip,達到上網與主機相互通訊
nat模式上網。因為nat本身就能上網為什麼還要設定ip。這有點自找麻煩。但是在叢集這是必須的。 nat模式,可是自動獲取ip,不需要設定即可實現上網,缺點不能和主機通訊。 nat模式設定靜態ip,達到上網與主機相互通訊: 安裝完成虛擬機器VMware,在網路連線
Android面試補習(一).JVM,DVM,ART虛擬機器
每天都在學習,最近在找找實習工作,在家等待的時候就會複習一下以前的知識,避免太久沒接觸生疏了,寫個部落格作為記錄吧,每次都會分享一些實用的,易懂的知識,畢竟我們實習生能瞭解的就這個層次。 第一篇就是關於虛擬機器,有點吊的,不過別怕,知識一些粗淺的
Android ART虛擬機器
轉載自:https://blog.csdn.net/luoshengyang/article/details/45017207 Android與ios相比,一直被人詬病它的流暢性。android的流暢性問題,有一部分原因就歸結於它的應用程式和部分系統服務是執行
開啟虛擬機器顯示“次虛擬環境中的長模式將被禁用”
近日,給一新機安裝VMware虛擬機器,在開啟虛擬機器的時候出現下圖的提示,無法正常開啟: 出現上圖的原因,主要是bios介面沒開啟對應的許可權,需要進入該模式下開啟,各電腦進入bios命令不一,有點F2,F1,F12 如下圖,將兩者的許可權都設定為enable狀態儲
虛擬機器安裝CentOS 7後無法上網問題解決辦法(NAT 模式)
虛擬機器安裝CentOS 7後無法上網問題解決辦法(NAT 模式) 1.進入系統目錄,cd /etc/sysconfig/network-scripts/ 檢視 ifcfg-eno** 檔案,最新的檔名稱為ifcfg-ens33檔案。 裡面有一項配置檔
虛擬機器橋接模式 ping 不通物理機的問題
這種情況的出現也不知道為啥, 首先開啟虛擬機器 點 “編輯”裡的 “虛擬網路編輯器”--- 然後在“橋接到”那裡由“自動”改成“個人區域網”,右下角點應用...然後你會發現依然ping不通,所以這個時候你再回到這裡,把它改回“自動”,然後點應用... 他就居然可以ping
安裝linux虛擬機器配置靜態ip(橋接模式)
1、centOs7、VMware Workstation14 2、常規新建虛擬機器操作後,來到選擇連線模式: 這裡選擇橋接模式,複製物理網路連線狀態(就是把實際的主機網絡卡資訊拷貝一份,讓虛擬機器也有一份和主機一樣的網絡卡)可不選, 關閉後,左上角點選編輯----虛擬網路編輯器 Vmnet0是