
Android ART虛擬機器
轉載自:https://blog.csdn.net/luoshengyang/article/details/45017207
Android與ios相比,一直被人詬病它的流暢性。android的流暢性問題,有一部分原因就歸結於它的應用程式和部分系統服務是執行虛擬機器之上的,也就是執行在Dalvik虛擬機器之上,而ios的應用程式和系統服務都是直接執行本地機器指令的。除了使用ATR替換Dalvik之外,我們也應當看到,Android從3。0開始,就不遺餘力地改進系統的流暢性。例如,3.0增加了對應用程式2D UI的硬體加速渲染,也就是GPU渲染。在此之前,應用程式的2D UI一直都是使用軟體渲染,也就是CPU渲染。又如4.1通過Project Butter,在UI架構中引用了VSYNC、Triple Buffer和HWComposer等技術,極大地提高UI的流暢性。
ART之所以會比Dalvik快,是因為ART執行的是本地機器指令,而Dalvik執行的是Dex位元組碼,通過直譯器執行。儘管Dalvik也會對頻繁執行的程式碼進行JIT生成本地機器指令來執行,但畢竟在應用程式執行的過程中將Dex位元組碼翻譯成本地機器指令也會影響到應用程式本身的執行,因此即使Dalvik使用了JIT,也在一定程度上也比不上直接就可以執行本地機器指令的執行時。
Dalvik就是android 4.4及職權使用的虛擬機器。它使用的是JIT(just in time)技術來進行程式碼轉譯,每次執行應用的時候,Dalvik將程式的程式碼編譯為機器語言執行。隨著硬體水平的發展以及人民對更高效能的需求,Dalvik虛擬機器的不足日益突出。而應運而生的ART(Android Run Time)虛擬機器,其處理機制根本上的區別是它採用AOT(Ahead of TIme)技術,會在應用程式安裝時就轉換成機器語言,不再在執行時解釋,從而優化了應用執行的速度。在記憶體管理方面,ART也有比較大的改進,對記憶體分配和回收都做了演算法優化,降低了記憶體碎片化程度,回收時間也得以縮短。
與Dalvik虛擬機器垃圾回收機制一樣,ART執行時垃圾收集機制也涉及到類似於Zygote堆、Active堆、Card Table、Heap Bitmap和Mark Stack等概念,如圖一所示:
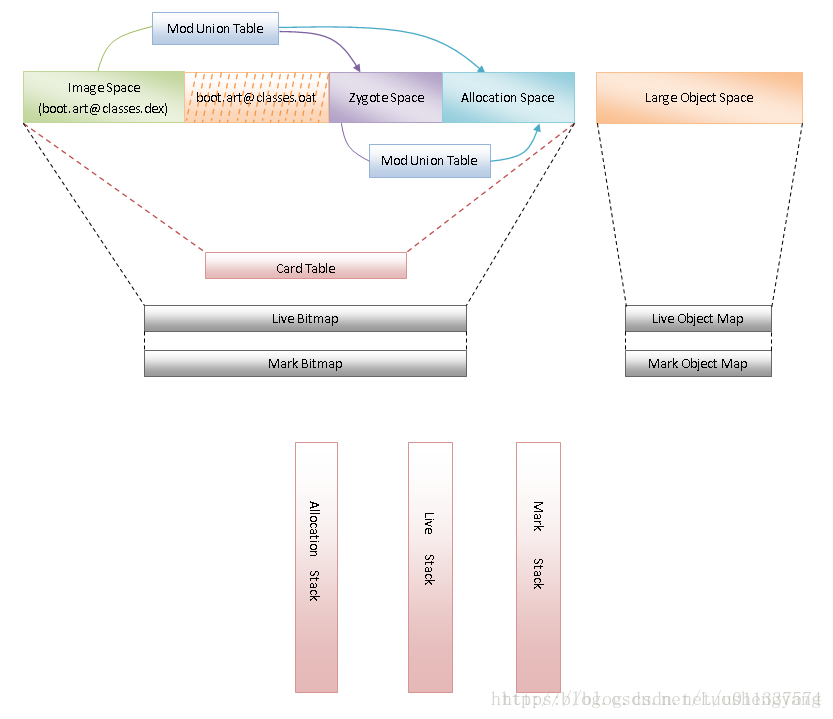
從圖1可以看到,ART執行時堆劃分為4個空間,分別是Image Space、Zygote Space、Allocation Space和Large Object Space。其中,Image Space 、Zygote Space、Allocation Space是在地址上連續的空間,稱為Continuous Space,而Large ObjectSpace 是一些離散地址的集合,用來分配一些大物件,稱為Discontinuous Space。
在Image Space和Zygote Space之間,隔著一段用來對映system@[email protected]@classes.oat檔案的記憶體。system@[email protected]@classes.oat是一個OAT檔案,它是由在系統啟動類路徑中的所有Dex檔案翻譯得到的,而Image Space空間就包含了那些需要預載入的系統類物件。這意味著需要預載入的類物件是在生成system@[email protected]@classes.oat這個OAT檔案的時候建立並且儲存在檔案system@[email protected]@classes.oat中,以後只要系統啟動類路徑中的DEX檔案不發生變化(即不發生更新升級),那麼以後每次系統啟動只需要將檔案system@[email protected]@classes.oat直接對映到記憶體即可,省去了建立各個類物件的時間。之前使用Dalvik虛擬機器作為應用程式執行時,每次系統啟動時,都需要為那些預載入的類建立類物件。因此,雖然ART執行時第一次啟動時會比較慢,但是以後啟動實際上會更快。
Zygote Space和Allocation Space與Dalvik虛擬機器垃圾收集機制中的Zygote堆和Active堆的作用是一樣的。Zygote Space在Zygote程序和應用程式程序之間共享的,而Allocation Space則是每個程序獨佔的。同樣的,Zygote 程序一開始只有一個Image Space和一個Zygote Space。在Zygote程序fork第一個子程序之前,就會吧Zygote Space一分為二,原來的已經被使用的部分堆還叫Zygote Space,而未使用的那部分堆就叫Allocation Space。以後的物件都在Allocation Space上分配。Large Object Space就是一些離散地址的集合,用來分配一些大物件,比如分配圖片。
通過上述這種方式,就可以使得Image Space和Zygote Space在Zygote程序和應用程式程序之間進行共享,而Allocation Space就每個程序都獨立地擁有一份。注意,雖然Image Space和Zygote Space都是在Zygote程序和應用程式程序之間進行共享,但是前者的物件只建立一次,而後者的物件需要在系統每次啟動時根據執行情況都重新建立一遍。
ART垃圾收集過程
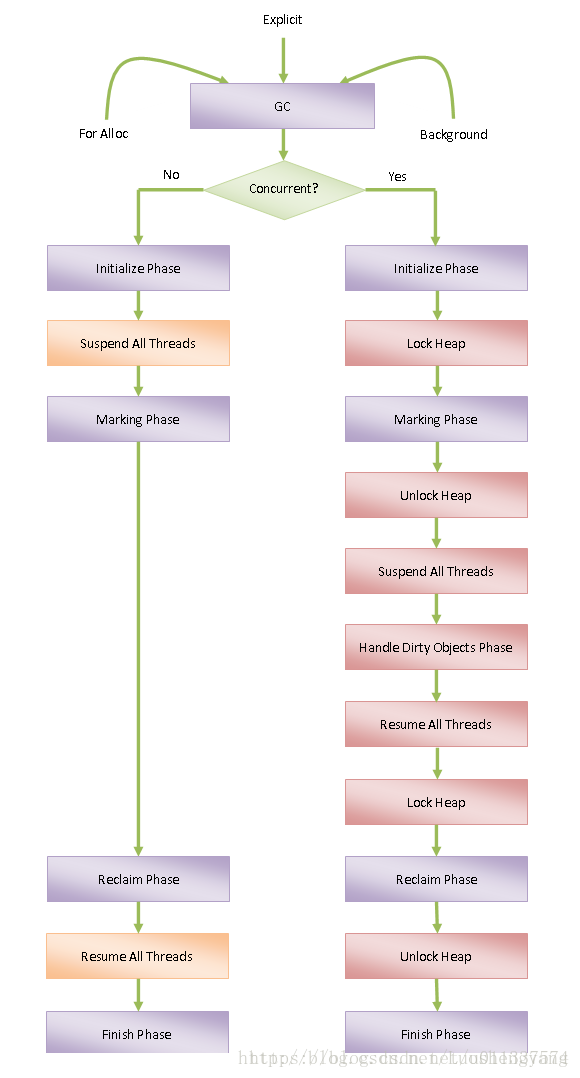
ART執行的每一個Space都有不同的回收策略,ART執行時根據這個特性提供了Mark Sweep、Partial Mark Sweep和Sticky Mark Sweep等三種回收力度不同的垃圾收集器。其中,Mark Sweep的垃圾回收力度最大,它會同時回收Zygote Space、Allocation Space和Large Object Space的垃圾,Partial MarkSweep的垃圾回收力度居中,它只會同時回收Allocation Space 和Large Object Space的垃圾,而Sticky Mark Sweep的垃圾回收力度最小,它只會回收Allocation Stack的垃圾,即上次GC以後分配出來的又不再使用了的物件。力度越大的垃圾收集器,回收垃圾時需要的時候也就越長。這樣我們就可以在應用程式執行的過程中根據不同的情景使用不同的垃圾收集器,那就可以更有效地執行垃圾回收過程。另外在Android 5.0以後的ART中,還引入了Semi-Space(SS)GC和Generaltional Semi-Space(GSS)、Mark-Compact(Mc)GC的三個Compaction GC,可以有效地解決記憶體碎片問題。
Semi-Space(SS)GC和Generational Semi-Space(GSS)GC是ART執行時引進的兩個Compacting GC。它們的共同點都具有一個From Space和一個To Space。在GC執行期間,在From Space分配的還存活的物件會被一次拷貝到To Space中,這樣就可以達到消除記憶體碎片的目的。
與SS GC相比,GSS GC 還多了一個Promote Space。當一個物件是在上一次GC之前分配的,並且在當前GC中仍然是存活的,那麼它就會被拷貝到Promote Space中,而不是To Space中。這相當於是簡單地將物件劃分為新生代和老生代的,即在上一次GC之前分配的物件屬於老生代的,而在上一次GC之後分配的物件屬於新生代的。一般來說,老生代物件的存活性要比新生代的久,因此將它們拷貝到Promote Space中去,可以避免每次執行SS GC或者GSS GC時,都需要對它們進行無用的處理。
總結來說,SS GC和GSS GC的執行過程就如下圖所示:
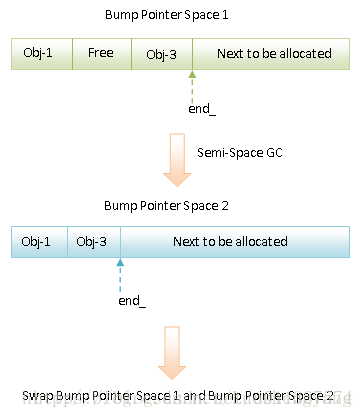
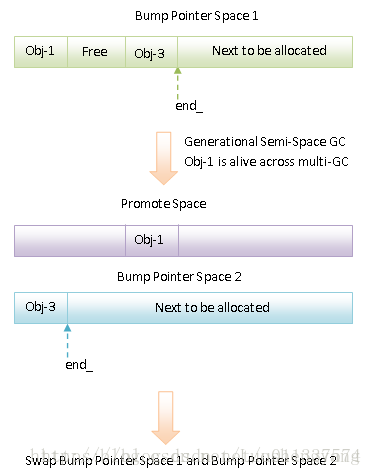
如上圖所示,Bump Pointer Space 1和Bump Pointer Space2就是我們前面說的From Space和To Space。
除了Semi-Space GC和Generational Semi-Space GC,ART執行時還引入了第三種Compacting GC:Mark-Compact(MC) GC。這三種GC雖然都是Compacting GC,不過它們的實現方式卻有很大不同。SSGC和GSS GC需兩個Space來壓縮記憶體,而MC GC只需一個Space來壓縮記憶體。
Mark-compact GC主要是針對ART執行時正在使用的Bump Pointer Space進行壓縮,如下圖所示:
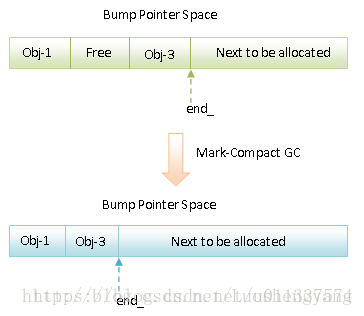
從圖1可以看出,當Mark-Compact GC執行完成之後,原來位於Bump Pointer Space上的仍然存活的物件會被一次移動至原Bump Pointer Space的左側,並且按地址從小到大緊湊地排列在一起。這個過程不需要藉助於額外的Space來完成。這一點是Mark-Compact GC與Semi-Space GC、Generational Semi-Space GC的顯著區別。
ART 與Dalvik比較
1、ART有很多GC方式可以選擇,而Dalvik只有一種GC方式。
2、ART通過額外記錄新分配的物件來支援更好的輕量級Sticky GC。
ART中新增的輕量級回收kGcTypeSticky只回收上次GC後再Allocation Space中新分配的垃圾物件,Heap 類的成員函式RecordAllocation首先是記錄當前已經分配的記憶體位元組數以及物件數,為了Sticky GC,還要接著再將新分配的物件壓入到Heap類的成員變數allocation_stack_描述的Allocation Stack中去,而Dalvik虛擬機器直接將新分配出來的物件記錄在Live Bitmap中。如果不能成功將新分配的物件壓入到Allocation Stack中,就說明上次GC以來,新分配的物件太多了,因此這時候就需要執行一個Sticky GC,將Allocation Stack裡面的垃圾進行回收,然後再嘗試將新分配的物件壓入到Allocation Stack中,直到成功為止。
3、大記憶體塊額外單獨管理,可以提高記憶體分配和回收效率。
4、減少Suspend時間。
對於並行GC,在Handle Dirty Object階段是在掛起ART執行時執行緒的前提下進行的,因此,如果把所有的Dirty Card 都放在Handle Dirty Object階段處理,那麼就會可能會造成應用程式停頓時間過長。於是,ART執行時就在並行Marking階段也幫忙著處理Dirty Card,通過這種方式儘量減少在Handle Dirty Object階段需要處理的Dirty Card,以達到減少應用程式因為GC造成的停頓時間。另外ART在垃圾回收過程中,也減少了掛起非GC執行緒的次數。