
Java過濾敏感詞
課程設計做了個部落格系統,為了對評論進行敏感詞過濾,所以去看了下DFA
在Java中實現敏感詞過濾的關鍵就是DFA演算法的實現。首先我們對上圖進行剖析。在這過程中我們認為下面這種結構會更加清晰明瞭。
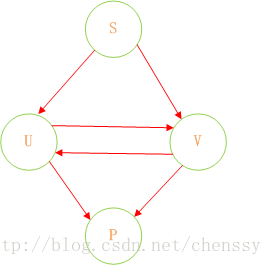
同時這裡沒有狀態轉換,沒有動作,有的只是Query(查詢)。我們可以認為,通過S query U、V,通過U query V、P,通過V query U P。通過這樣的轉變我們可以將狀態的轉換轉變為使用Java集合的查詢。
誠然,加入在我們的敏感詞庫中存在如下幾個敏感詞:日本人、日本鬼子、毛.澤.東。那麼我需要構建成一個什麼樣的結構呢?
首先:query 日 ---> {本}、query 本 --->{人、鬼子}、query 人 --->{null}、query 鬼 ---> {子}。形如下結構:
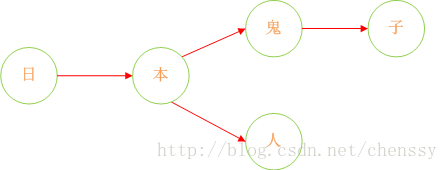
下面我們在對這圖進行擴充套件:
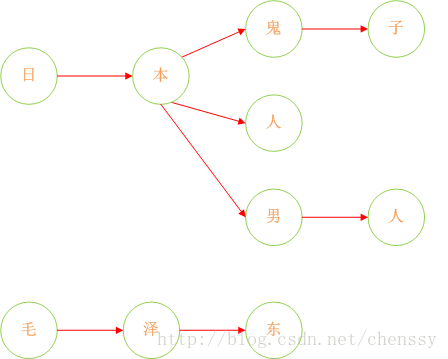
這樣我們就將我們的敏感詞庫構建成了一個類似與一顆一顆的樹,這樣我們判斷一個詞是否為敏感詞時就大大減少了檢索的匹配範圍。比如我們要判斷日本人,根據第一個字我們就可以確認需要檢索的是那棵樹,然後再在這棵樹中進行檢索。
但是如何來判斷一個敏感詞已經結束了呢?利用標識位來判斷。
所以對於這個關鍵是如何來構建一棵棵這樣的敏感詞樹。下面我已Java中的HashMap為例來實現DFA演算法。具體過程如下:
日本人,日本鬼子為例
1、在hashMap中查詢“日”看其是否在hashMap中存在,如果不存在,則證明已“日”開頭的敏感詞還不存在,則我們直接構建這樣的一棵樹。跳至3。
2、如果在hashMap中查詢到了,表明存在以“日”開頭的敏感詞,設定hashMap = hashMap.get("日"),跳至1,依次匹配“本”、“人”。
3、判斷該字是否為該詞中的最後一個字。若是表示敏感詞結束,設定標誌位isEnd = 1,否則設定標誌位isEnd = 0;
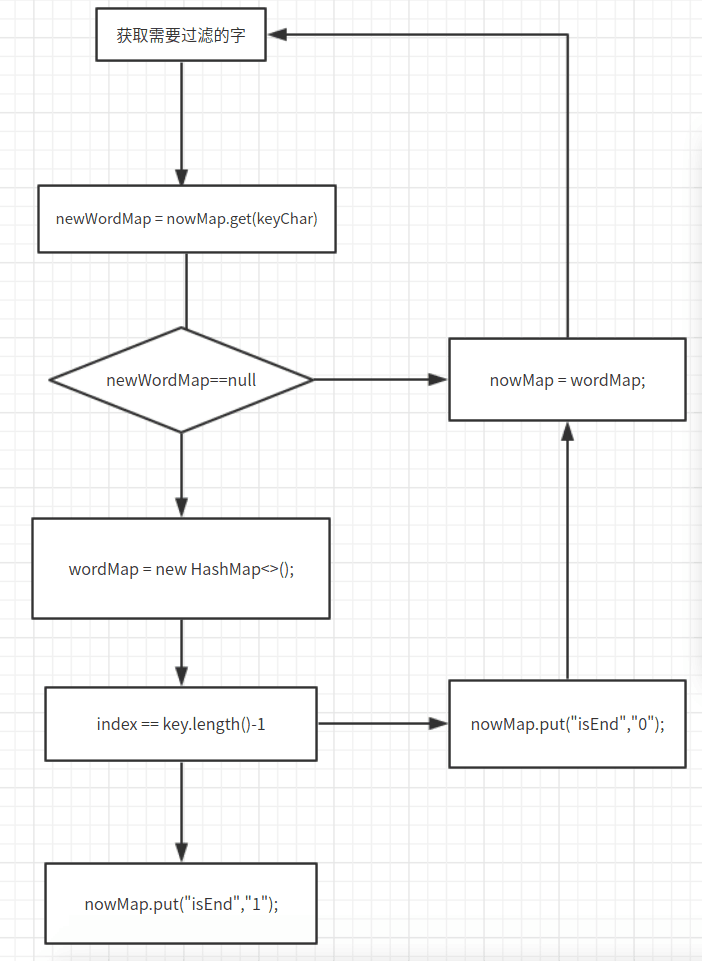
首先需要建立一個敏感詞庫:
- /**
- * 讀取敏感詞庫,將敏感詞放入HashSet中,構建一個DFA演算法模型:<br>
- * 中 = {
- * isEnd = 0
- * 國 = {<br>
- * isEnd = 1
- * 人 = {isEnd = 0
- * 民 = {isEnd = 1}
- * }
- * 男 = {
- * isEnd = 0
- * 人 = {
- * isEnd = 1
- * }
- * }
- * }
- * }
- * 五 = {
- * isEnd = 0
- * 星 = {
- * isEnd = 0
- * 紅 = {
- * isEnd = 0
- * 旗 = {
- * isEnd = 1
- * }
- * }
- * }
- * }
- */
/** * 建立敏感詞彙樹 * @param keyWordSet */ public void createWords(Set<String> keyWordSet) { sensitiveWordMap = new HashMap(keyWordSet.size()); Map nowMap = null; Map<String,String> wordMap = null; String key = null; for (String word : keyWordSet) { nowMap = sensitiveWordMap; key = word; for (int index=0 ; index<key.length() ; index++) { char keyChar = key.charAt(index); Object newWordMap = nowMap.get(keyChar); if (newWordMap!=null) { nowMap = (Map) newWordMap; } else { wordMap = new HashMap<>(); wordMap.put("isEnd","0"); nowMap.put(keyChar,wordMap); nowMap = wordMap; } if (index == key.length()-1) { nowMap.put("isEnd","1"); } } } }
敏感詞庫我們一個簡單的方法給實現了,那麼如何實現檢索呢?檢索過程無非就是hashMap的get實現,找到就證明該詞為敏感詞,否則不為敏感詞。過程如下:假如我們匹配“中國人民萬歲”。
1、第一個字“中”,我們在hashMap中可以找到。得到一個新的map = hashMap.get("")。
2、如果map == null,則不是敏感詞。否則跳至3
3、獲取map中的isEnd,通過isEnd是否等於1來判斷該詞是否為最後一個。如果isEnd == 1表示該詞為敏感詞,否則跳至1。
通過這個步驟我們可以判斷“中國人民”為敏感詞,但是如果我們輸入“中國女人”則不是敏感詞了。
/** * 獲取敏感詞彙集 * @param txt * @param matchType * @return */ public Set<String> getSensitiveWord(String txt,int matchType) { Set<String> sensitiveWordList = new HashSet<>(); for (int index=0;index<txt.length();index++) { int length = checkSensitiveWord(txt,index,matchType); if (length>0) { sensitiveWordList.add(txt.substring(index,index+length)); index = index + length - 1; } } return sensitiveWordList; } /** * 匹配 判斷敏感詞彙 * @param txt * @param beginIndex * @param matchType * @return */ public int checkSensitiveWord(String txt,int beginIndex,int matchType) { boolean flag = false; int wordFlag = 0; char word = 0; Map nowMap = sensitiveWordMap; for (int index=beginIndex ; index<txt.length() ; index++) { word = txt.charAt(index); nowMap = (Map) nowMap.get(word); if (nowMap!=null) { wordFlag++; if ("1".equals(nowMap.get("isEnd"))) { flag = true; if (FilterUtil.minMatchTYpe == matchType) { break;//最小匹配直接跳出 } } } else { //不存在,直接返回 break; } } System.out.println(wordFlag+" "+flag); if (wordFlag<2 || !flag) { return 0; } return wordFlag; }需要一個詞庫:點選下載詞庫,提取碼:tk3g