
KUDU--秒級查詢的資料倉庫
## == Kudu 是什麼 ==
Kudu是ToddLipcon@Cloudera帶頭開發的儲存系統,其整體應用模式和HBase比較接近,即支援行級別的隨機讀寫,並支援批量順序檢索功能。
那既然有了HBase,為什麼還需要Kudu呢,簡單的說,就是嫌棄HBase在OLAP場合,SQL/MR類的批量檢索場景中,效能不夠好。通常這種海量資料OLAP場景,要不走預處理的路,比如像EBAY麒麟這樣走Cube管理的,或者像谷歌Mesa這樣按業務需求走預定義聚合操作。再有就是自己構建資料通道,串接實時和批量處理兩種系統,發揮各自的特長。
但是OLAP是個複雜的問題,場景眾多,必然不可能有完美的通用解決方案,Kudu定位於應對快速變化資料的快速分析型資料倉庫,希望靠系統自身能力,支撐起同時需要高吞吐率的順序和隨機讀寫的應用場景(可能的場景,比如時間序列資料分析,日誌資料實時監控分析),提供一個介於
那為什麼不能想辦法改進HBase呢?Todd自己做為HBase的重要貢獻者之一,沒有選擇這條路,自然是因為任何系統設計時都有Tradeoff,基於HBase的設計思想很難實現Kudu所定位的目標
相關連結
## == 核心思想 ==
### 資料模型:
資料模型定義上,Kudu管理的是類似關係型資料庫的結構化的表,表結構由類Sql的Schema進行定義,相比於HBase這樣的NoSql型別的資料庫,Kudu的行資料是由固定個數有明確型別定義的列組成,並且需要定義一個由一個或多個列組成的主鍵來對每行資料進行唯一索引,相比於傳統的關係型資料庫,kudu在索引上有更多的限制,比如暫時不支援二級索引,不支援主鍵的更新等等。
儘管表結構類似於關係型資料庫,但是Kudu自身並不提供SQL型別的語法介面,而是由上層其他系統實現,比如目前通過Impala提供SQL語法支援。
Kudu底層API,主要面對簡單的更新檢索操作,Insert/Update/Delete等必須指定一個主鍵進行,而Scan檢索型別的操作則支援條件過濾和投影等能力。
### 叢集架構:
Kudu的叢集架構基本和HBase類似,採用主從結構,Master節點管理元資料,Tablet節點負責分片管理資料,
和HBase不同的是,Kudu沒有藉助於HDFS儲存實際資料,而是自己直接在本地磁碟上管理分片資料,包括資料的Replication機制,kudu的Tablet
### 儲存結構:
因為資料是有嚴格Schema型別定義,所以Kudu底層可以使用列式儲存的方案來提高儲存和投影檢索效率(不過,設計kudu時,因果關係我估計是倒過來的,先決定要使用列式儲存,再決定需要schema)
和HBase一樣,Kudu也是通過Tablet的分割槽來支援水平擴充套件,與HBase不同的是,Kudu的分割槽策略除了支援按照KeyRange來分割槽以外,還支援Hashbased的策略,實際上,在主鍵上,Kudu可以混合使用這兩種不同的策略
Hash分割槽的策略在一些場合下可以更好的做到負載均衡,避免資料傾斜,但是它最大的問題就是分割槽數一旦確定就很難再調整,所以目前Kudu的分割槽數必須預先指定(對Range的分割槽策略也有這個要求,估計是先簡單化統一處理),不支援動態分割槽分裂,合併等,因此表的分割槽一開始就需要根據負載和容量預先進行合理規劃。
在處理隨機寫的效率問題方面,Kudu的基本流程和HBase的方案差不多,在記憶體中對每個Tablet分割槽維護一個MemRowSet來管理最新更新的資料,當尺寸超過一定大小後Flush到磁碟上形成DiskRowSet,多個DiskRowSet在適當的時候進行歸併處理
和HBase採用的LSM(LogStructuredMerge)方案不同的是,Kudu對同一行的資料更新記錄的合併工作,不是在查詢的時候發生的(HBase會將多條更新記錄先後Flush到不同的Storefile中,所以讀取時需要掃描多個檔案,比較rowkey,比較版本等),而是在更新的時候進行,在Kudu中一行資料只會存在於一個DiskRowSet中,避免讀操作時的比較合併工作。那Kudu是怎麼做到的呢?對於列式儲存的資料檔案,要原地變更一行資料是很困難的,所以在Kudu中,對於Flush到磁碟上的DiskRowSet(DRS)資料,實際上是分兩種形式存在的,一種是Base的資料,按列式儲存格式存在,一旦生成,就不再修改,另一種是Delta檔案,儲存Base資料中有變更的資料,一個Base檔案可以對應多個Delta檔案,這種方式意味著,插入資料時相比HBase,需要額外走一次檢索流程來判定對應主鍵的資料是否已經存在。因此,Kudu是犧牲了寫效能來換取讀取效能的提升。
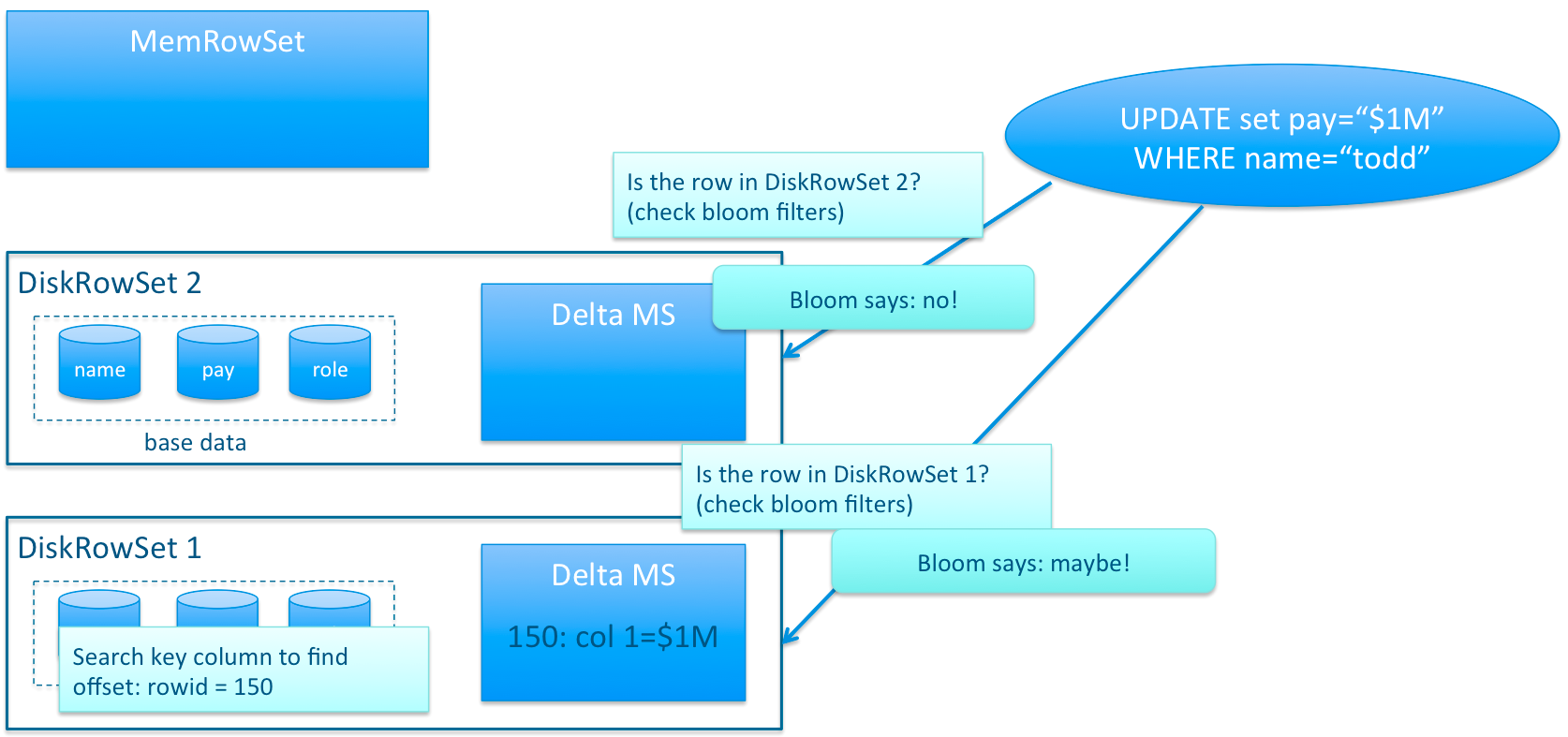
既然存在Delta資料,也就意味著資料查詢時需要同時檢索Base檔案和Delta檔案,這看起來和HBase的方案似乎又走到一起去了,不同的地方在於,Kudu的Delta檔案與Base檔案不同,不是按Key排序的,而是按被更新的行在Base檔案中的位移來檢索的,號稱這樣做,在定位Delta內容的時候,不需要進行字串比較工作,因此能大大加快定位速度。但是無論如何,Delta檔案的存在對檢索速度的影響巨大。因此Delta檔案的數量會需要控制,需要及時的和Base資料進行合併。由於Base檔案是列式儲存的,所以Delta檔案合併時,可以有選擇性的進行,比如只把變化頻繁的列進行合併,變化很少的列保留在Delta檔案中暫不合並,這樣做也能減少不必要的IO開銷。
除了Delta檔案合併,DRS自身也會需要合併,為了保障檢索延遲的可預測性(這一點是HBase的痛點之一,比如分割槽發生MajorCompaction時,讀寫效能會受到很大影響),Kudu的compaction策略和HBase相比,有很大不同,kudu的DRS資料檔案的compaction,本質上不是為了減少檔案數量,實際上KuduDRS預設是以32MB為單位進行拆分的,DRS的compaction並不減少檔案數量,而是對內容進行排序重組,減少不同DRS之間key的overlap,進而在檢索的時候減少需要參與檢索的DRS的數量。
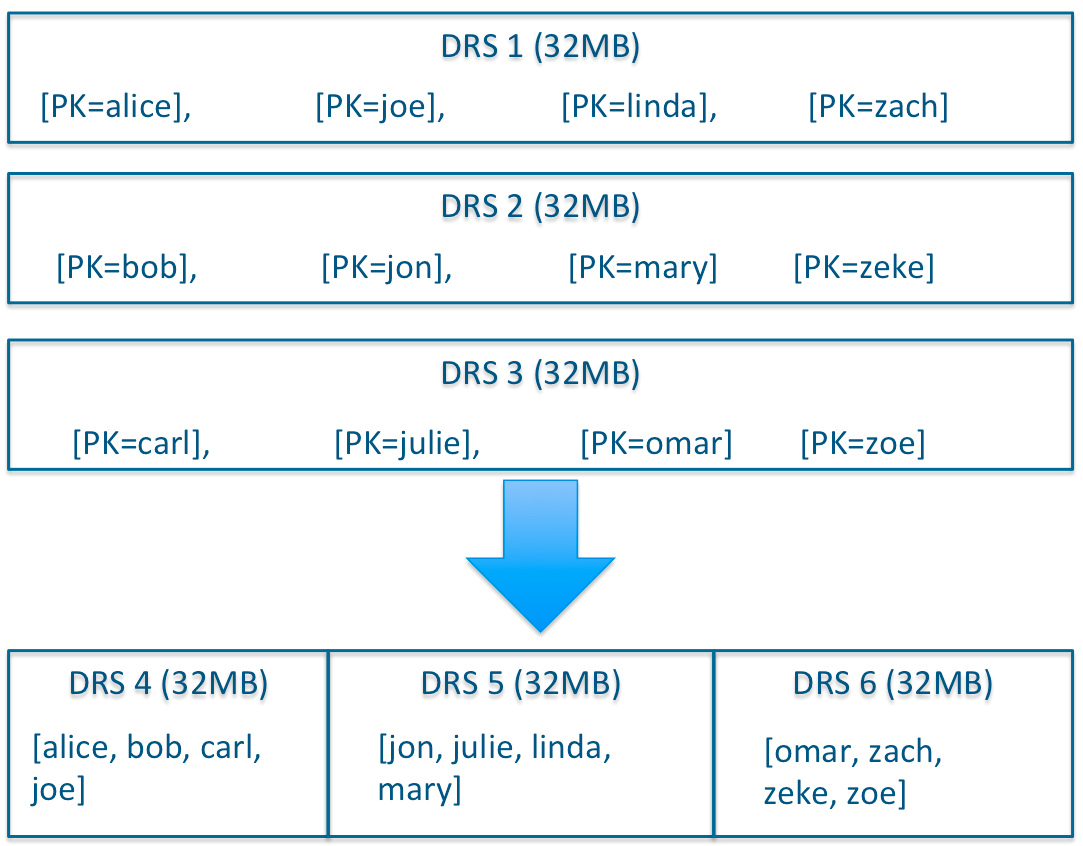
以32MB這樣小的單位進行拆分,也是為了能夠以有限的資源快速的完成compaction的任務,及時根據系統負載調整Compaction行為,而不至於像HBase一樣,MajorCompaction動作成為導致效能不穩定的一個重要因素。所以對於Kudu來說,IO操作可以是一個持續平緩的過程,這點對響應的可預測性至關重要。
### 其它
Kudu底層核心程式碼使用C++開發,對外提供JavaAPI介面,沒有使用Java開發核心程式碼,也許有部分原因是希望通過自己管理記憶體,更好的適應和利用當前伺服器上普遍越來越大的記憶體空間(256G+),另外也便於在關鍵邏輯中更好的優化程式碼。
## == 小結 ==
總體來說,個人感覺,Kudu本質上是將效能的優化,寄託在以列式儲存為核心的基礎上,希望通過提高儲存效率,加快欄位投影過濾效率,降低查詢時CPU開銷等來提升效能。而其他絕大多數設計,都是為了解決在列式儲存的基礎上支援隨機讀寫這樣一個目的而存在的。比如類Sql的元資料結構,是提高列式儲存效率的一個輔助手段,唯一主鍵的設定也是配合列式儲存引入的定製策略,至於其他如Delta儲存,compaction策略等都是在這個設定下為了支援隨機讀寫,降低latency不確定性等引入的一些Tradeoff方案
官方測試結果上,如果是存粹的隨機讀寫,或者單行的檢索請求這類場景,由於這些Tradeoff的存在,HBASE的效能吞吐率是要優於Kudu不少的(2倍到4倍),kudu的優勢還是在支援類SQL檢索這樣經常需要進行投影操作的批量順序檢索分析場合。
目前kudu還處在Incubator階段,並且還沒有成熟的線上應用(小米走在了前面,做了一些業務應用的嘗試),在資料安全,備份,系統健壯性等方面也還要打個問號,所以是否使用kudu,什麼場合,什麼時間點使用,是個需要好好考量的問題;)
轉載自:http://blog.csdn.net/colorant/article/details/50803226