
Phoenix四貼之三:hive整合
0.前期準備,偽分散式的hbase搭建(這裡簡單演示一下)
Hbase的偽分散式安裝部署(使用三個程序來當作叢集)
在這裡,下載的是1.2.3版本
關於hbase和hadoop的版本對應資訊,可參考官檔的說明
tar -zxvf hbase-1.2.6-bin.tar.gz -C /opt/soft/
cd /opt/soft/hbase-1.2.6/
vim conf/hbase-env.sh
#在內部加入export JAVA_HOME=/usr/local/jdk1.8(或者source /etc/profile)
#配置Hbase
mkdir /opt/soft/hbase-1.2.6/data
vim conf/hbase-site.xml
#####下面是在hbase-site.xml新增的項#####
< 啟動Hbase
[[email protected] ~]# /opt/soft/hbase-1.2.6/bin/hbase-daemon.sh start zookeeper 可以看出,新增了HQuorumPeer,HRegionServer和HMaster三個程序。
通過http://yyh4:16030/訪問Hbase的web頁面
至此,Hbase的偽分散式叢集搭建完畢
1. 安裝部署
1.1 安裝預編譯的Phoenix
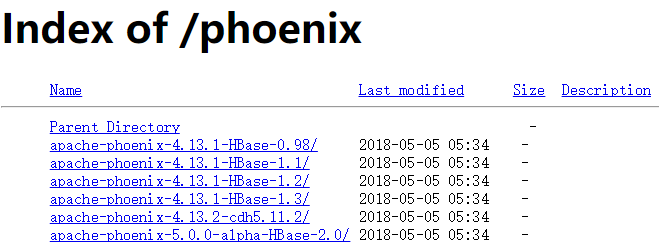
1.下載並解壓最新版的phoenix-[version]-bin.tar包
地址:http://apache.fayea.com/phoenix/apache-phoenix-4.13.1-HBase-1.2/bin/
理由:hbase是1.2.6版本的,所以選用4.13.1版本的phoenix,
將phoenix-[version]-server.jar放入服務端和master節點的HBase的lib目錄下
重啟HBase
將phoenix-[version]-client.jar新增到所有Phoenix客戶端的classpath
#將phoenix-[version]-server.jar放入服務端和master節點的HBase的lib目錄下
#將phoenix-[version]-client.jar新增到所有Phoenix客戶端的classpath
[root@yyh4 /]# cd /opt/soft
[root@yyh4 soft]# tar -zxvf apache-phoenix-4.13.1-HBase-1.2-bin.tar.gz
[root@yyh4 soft]# cp apache-phoenix-4.13.1-HBase-1.2-bin/phoenix-4.13.1-HBase-1.2-server.jar hbase-1.2.6/lib/
[root@yyh4 soft]# cp apache-phoenix-4.13.1-HBase-1.2-bin/phoenix-4.13.1-HBase-1.2-client.jar hbase-1.2.6/lib/2 使用Phoenix
若要在命令列執行互動式SQL語句:
執行過程 (要求python及yum install python-argparse)
在phoenix-{version}/bin 目錄下
$ /opt/soft/apache-phoenix-4.13.1-HBase-1.2-bin/bin/sqlline.py localhost可以進入命令列模式
0: jdbc:phoenix:localhost>退出命令列的方式是執行 !quit
0: jdbc:phoenix:localhost>!quit
0: jdbc:phoenix:localhost> help其餘常見指令
!all Execute the specified SQL against all the current connections
!autocommit Set autocommit mode on or off
!batch Start or execute a batch of statements
!brief Set verbose mode off
!call Execute a callable statement
!close Close the current connection to the database
!closeall Close all current open connections
!columns List all the columns for the specified table
!commit Commit the current transaction (if autocommit is off)
!connect Open a new connection to the database.
!dbinfo Give metadata information about the database
!describe Describe a table
!dropall Drop all tables in the current database
!exportedkeys List all the exported keys for the specified table
!go Select the current connection
!help Print a summary of command usage
!history Display the command history
!importedkeys List all the imported keys for the specified table
!indexes List all the indexes for the specified table
!isolation Set the transaction isolation for this connection
!list List the current connections
!manual Display the SQLLine manual
!metadata Obtain metadata information
!nativesql Show the native SQL for the specified statement
!outputformat Set the output format for displaying results
(table,vertical,csv,tsv,xmlattrs,xmlelements)
!primarykeys List all the primary keys for the specified table
!procedures List all the procedures
!properties Connect to the database specified in the properties file(s)
!quit Exits the program
!reconnect Reconnect to the database
!record Record all output to the specified file
!rehash Fetch table and column names for command completion
!rollback Roll back the current transaction (if autocommit is off)
!run Run a script from the specified file
!save Save the current variabes and aliases
!scan Scan for installed JDBC drivers
!script Start saving a script to a file
!set Set a sqlline variable
!sql Execute a SQL command
!tables List all the tables in the database
!typeinfo Display the type map for the current connection
!verbose Set verbose mode on若要在命令列執行SQL指令碼
$ sqlline.py localhost ../examples/stock_symbol.sql測試ph:
#建立表
CREATE TABLE yyh ( pk VARCHAR PRIMARY KEY,val VARCHAR );
#增加,修改表資料
upsert into yyh values ('1','Helldgfho');
#查詢表資料
select * from yyh;
#刪除表(如果是建立表,則同時刪除phoenix與hbase表資料,如果是建立view,則不刪除hbase的資料)
drop table test;3.(HIVE和Phoenix整合)Phoenix Hive的Phoenix Storage Handler
Apache Phoenix Storage Handler是一個外掛,它使Apache Hive能夠使用HiveQL從Apache Hive命令列訪問Phoenix表。
Hive安裝程式
使hive提供phoenix-{version}-hive.jar:
#在phoenix節點:
[[email protected] apache-phoenix-4.13.1-HBase-1.2-bin]#
scp phoenix-4.13.1-HBase-1.2-hive.jar yyh3://opt/soft/apache-hive-1.2.1-bin/lib
#第1步:在hive-server節點:hive-env.sh(這裡不需要,因為lib內部)
#HIVE_AUX_JARS_PATH = <jar的路徑>
#第2步:將屬性新增到hive-site.xml(也不需要),以便Hive MapReduce作業可以使用.jar:
#<屬性>
# <名稱> hive.aux.jars.path </名稱>
# <值>檔案:// <路徑> </值>
#</屬性>表建立和刪除
Phoenix Storage Handler支援INTERNAL和EXTERNAL Hive表。
建立內部表
對於INTERNAL表,Hive管理表和資料的生命週期。建立Hive表時,也會建立相應的Phoenix表。一旦Hive表被刪除,鳳凰表也被刪除。
create table phoenix_yyh (
s1 string,
s2 string
)
STORED BY 'org.apache.phoenix.hive.PhoenixStorageHandler'
TBLPROPERTIES (
"phoenix.table.name" = "yyh",
"phoenix.zookeeper.quorum" = "yyh4",
"phoenix.zookeeper.znode.parent" = "/hbase",
"phoenix.zookeeper.client.port" = "2181",
"phoenix.rowkeys" = "s1, i1",
"phoenix.column.mapping" = "s1:s1, i1:i1, f1:f1, d1:d1",
"phoenix.table.options" = "SALT_BUCKETS=10, DATA_BLOCK_ENCODING='DIFF'"
);建立EXTERNAL表
對於EXTERNAL表,Hive與現有的Phoenix表一起使用,僅管理Hive元資料。從Hive中刪除EXTERNAL表只會刪除Hive元資料,但不會刪除Phoenix表。
create external table ayyh
(pk string,
value string)
STORED BY 'org.apache.phoenix.hive.PhoenixStorageHandler'
TBLPROPERTIES (
"phoenix.table.name" = "yyh",
"phoenix.zookeeper.quorum" = "yyh4",
"phoenix.zookeeper.znode.parent" = "/hbase",
"phoenix.column.mapping" = "pk:PK,value:VAL",
"phoenix.rowkeys" = "pk",
"phoenix.table.options" = "SALT_BUCKETS=10, DATA_BLOCK_ENCODING='DIFF'"
);屬性
- phoenix.table.name
- Specifies the Phoenix table name #指定Phoenix表名
- Default: the same as the Hive table #預設值:與Hive表相同
- phoenix.zookeeper.quorum
- Specifies the ZooKeeper quorum for HBase
- Default: localhost #預設:localhost
- phoenix.zookeeper.znode.parent
- Specifies the ZooKeeper parent node for HBase #指定HBase的ZooKeeper父節點
- Default: /hbase
- phoenix.zookeeper.client.port
- Specifies the ZooKeeper port #指定ZooKeeper埠
- Default: 2181
- phoenix.rowkeys
- The list of columns to be the primary key in a Phoenix table #Phoenix列表中的主列
- Required #必填
- phoenix.column.mapping
- Mappings between column names for Hive and Phoenix. See Limitations for details #Hive和Phoenix的列名之間的對映。詳情請參閱限制。
資料提取,刪除和更新
資料提取可以通過Hive和Phoenix支援的所有方式完成:
Hive:
insert into table T values (....);
insert into table T select c1,c2,c3 from source_table;Phoenix:
upsert into table T values (.....);
Phoenix CSV BulkLoad toolsAll delete and update operations should be performed on the Phoenix side. See Limitations for more details. #所有刪除和更新操作都應在鳳凰方面執行。請參閱限制瞭解更多詳情。
其他配置選項
這些選項可以在Hive命令列介面(CLI)環境中設定。
Performance Tuning效能調整
| Parameter | Default Value | Description |
|---|---|---|
| phoenix.upsert.batch.size | 1000 | Batch size for upsert.批量大小 |
| [phoenix-table-name].disable.wal | false | Temporarily sets the table attribute DISABLE_WAL to true. Sometimes used to improve performance#暫時將表格屬性DISABLE_WAL設定為true。有時用於提高效能 |
| [phoenix-table-name].auto.flush | false | When WAL is disabled and if this value is true, then MemStore is flushed to an HFile.#當WAL被禁用時,如果該值為true,則MemStore被重新整理為HFile |
Query Data查詢資料
You can use HiveQL for querying data in a Phoenix table. A Hive query on a single table can be as fast as running the query in the Phoenix CLI with the following property settings: hive.fetch.task.conversion=more and hive.exec.parallel=true
#您可以使用HiveQL查詢Phoenix表中的資料。單個表上的Hive查詢可以像執行Phoenix CLI中的查詢一樣快,並具有以下屬性設定:hive.fetch.task.conversion = more和hive.exec.parallel = true
| Parameter | Default Value | Description |
|---|---|---|
| hbase.scan.cache | 100 | Read row size for a unit request#讀取單位請求的行大小 |
| hbase.scan.cacheblock | false | Whether or not cache block#是否快取塊 |
| split.by.stats | false | If true, mappers use table statistics. One mapper per guide post. |
| [hive-table-name].reducer.count | 1 | Number of reducers. In Tez mode, this affects only single-table queries. See Limitations. |
| [phoenix-table-name].query.hint | Hint for Phoenix query (for example, NO_INDEX) |
限制
- Hive update and delete operations require transaction manager support on both Hive and Phoenix sides. Related Hive and Phoenix JIRAs are listed in the Resources section. #Hive更新和刪除操作需要Hive和Phoenix兩方的事務管理器支援。相關的Hive和Phoenix JIRA列在參考資料部分。
- Column mapping does not work correctly with mapping row key columns. #列對映無法正確使用對映行鍵列。
- MapReduce and Tez jobs always have a single reducer . #MapReduce和Tez作業總是隻有一個reducer。
資源
- PHOENIX-2743 : Implementation, accepted by Apache Phoenix community. Original pull request contains modification for Hive classes.#實施,被Apache Phoenix社群接受。原始請求包含對Hive類的修改。
- PHOENIX-331 : An outdated implementation with support of Hive 0.98.#支援Hive 0.98的過時實施。
4 整合的全步驟預覽
#注意這樣的操作,尤其是大小寫的處理,其實更符合所有元件
#####虛擬叢集測試概要#####
#hbase shell
#habse節點 2列,3資料
create 'YINGGDD','info'
put 'YINGGDD', 'row021','info:name','phoenix'
put 'YINGGDD', 'row012','info:name','hbase'
put 'YINGGDD', 'row012','info:sname','shbase'
#phoenix 節點
#opt/soft/apache-phoenix-4.13.1-HBase-1.2-bin/bin/sqlline.py yyh4
create table "YINGGDD" ("id" varchar primary key, "info"."name" varchar, "info"."sname" varchar);
select * from "YINGGDD";
#hive節點
#beeline -u jdbc:hive2://yyh3:10000
create external table yingggy ( id string,
name string,
sname string)
STORED BY 'org.apache.phoenix.hive.PhoenixStorageHandler'
TBLPROPERTIES ("phoenix.table.name" = "YINGGDD" ,
"phoenix.zookeeper.quorum" = "yyh4" ,
"phoenix.zookeeper.znode.parent" = "/hbase",
"phoenix.column.mapping" = "pk:id,name:name,sname:sname",
"phoenix.rowkeys" = "id",
"phoenix.table.options" = "SALT_BUCKETS=10, DATA_BLOCK_ENCODING='DIFF'");
select * from yingggy; ############公司內部叢集測試###############
#hive 111 --- ph 113
#ph表
beeline -u jdbc:hive2://192.168.1.111:10000/dm -f /usr/local/apache-hive-2.3.2-bin/bin/yyh.sql
add jar /usr/local/apache-hive-2.3.2-bin/lib/phoenix-4.9.0-cdh5.9.1-hive.jar;
add jar /usr/local/apache-hive-2.3.2-bin/lib/phoenix-4.9.0-HBase-1.2-hive.jar;
add jar /usr/local/apache-hive-2.3.2-bin/lib/phoenix-4.9.0-HBase-1.2-client.jar;
#driver#phoenix-4.9.0-HBase-1.2-hive.org.apache.phoenix.jdbc.PhoenixDriver
create external table ayyh
(pk string,
value string)
STORED BY 'org.apache.phoenix.hive.PhoenixStorageHandler'
TBLPROPERTIES (
"phoenix.table.name" = "yyh",
"phoenix.zookeeper.quorum" = "192.168.1.112",
"phoenix.zookeeper.znode.parent" = "/hbase",
"phoenix.column.mapping" = "pk:PK,value:VAL",
"phoenix.rowkeys" = "pk",
"phoenix.table.options" = "SALT_BUCKETS=10, DATA_BLOCK_ENCODING='DIFF'"
);
#113作為hive的客戶端,去建立表格
cd ~
beeline -u jdbc:hive2://192.168.1.111:10000/dm -u hive -f yyha.sql
#117登陸hive查看錶格
beeline -u jdbc:hive2://192.168.1.111:10000/dm -e "select * from ayyh limit 3"5目前的踩坑記
5.1 stored類找不到
Error: Error while compiling statement: FAILED: SemanticException Cannot find class 'org.apache.phoenix.hive.PhoenixStorageHandler' (state=42000,code=40000)
##分析如下,缺少jar包#匯入add jar解決5.2 No suitable driver found for jdbc:phoenix
#因此,進入beeline以後,用add jar(公司叢集,不允許頻繁啟動):
0: jdbc:hive2://yyh3:10000> add jar /opt/soft/apache-hive-1.2.1-bin/lib/phoenix-4.13.1-HBase-1.2-hive.jar;
INFO : Added [/opt/soft/apache-hive-1.2.1-bin/lib/phoenix-4.13.1-HBase-1.2-hive.jar]
相關推薦
Phoenix四貼之三:hive整合
0.前期準備,偽分散式的hbase搭建(這裡簡單演示一下)Hbase的偽分散式安裝部署(使用三個程序來當作叢集)在這裡,下載的是1.2.3版本關於hbase和hadoop的版本對應資訊,可參考官檔的說明tar -zxvf hbase-1.2.6-bin.tar.gz -C /opt/soft/
cd /opt
Phoenix三貼之三:Phoenix和hive的整合
0.前期準備,偽分散式的hbase搭建(這裡簡單演示一下)
Hbase的偽分散式安裝部署(使用三個程序
Hive命令之三:hive的資料匯入匯出
Hive 資料的匯入匯出:
一 Hive資料匯出
1、匯出資料到本地檔案系統:
insert overwrite local directory '/software/data/data1' select * f
MyBatis初級實戰之三:springboot整合druid
OpenWrite版:
### 歡迎訪問我的GitHub
[https://github.com/zq2599/blog_demos](https://github.com/zq2599/blog_demos)
內容:所有原創文章分類彙總及配套原始碼,涉及Java、Docker、Kubernetes、De
spring boot 系列之三:spring boot 整合JdbcTemplate
closed com context boot pin pan url wired ace 前面兩篇文章我們講了兩件事情:
通過一個簡單實例進行spring boot 入門
修改spring boot 默認的服務端口號和默認context path
這篇文章我們來看下怎
UVM暫存器篇之三:暫存器模型的整合(上)
本文轉自:http://www.eetop.cn/blog/html/28/1561828-6266220.html
我們在上一節大致瞭解了與暫存器相關的流程,包括暫存器描述檔案和UVM暫存器模型生成。從上節給的暫存器模型流程圖中我們可以看到,接下來需要考慮選擇與DUT暫存器介面一致的匯流排UV
Spring Boot 系統之三:Spring Boot 整合JdbcTemplate
前面兩篇文章我們講了兩件事情:
通過一個簡單例項進行Spring Boot 入門
修改Spring Boot 預設的服務埠號和預設context path
這篇文章我們來看下怎麼通過JdbcTemplate進行資料的持久化。
一、程式碼實現
1、修改pom.xml檔案
座標系轉換之三:尤拉角、四元數、旋轉矩陣、方向餘弦矩陣、旋轉向量、軸角表示
座標轉換有很多種方法,不同的領域有不同的使用習慣。
上兩篇文章我們講了旋轉矩陣和尤拉角,可知尤拉角是可以由旋轉矩陣轉化而來。
那麼怎麼從尤拉角轉化為旋轉矩陣呢?
尤拉角(Euler angles)與旋轉矩陣(Rotation Matrix)
假設座標
效能優化之三:將Dottrace過程加入持續整合
之前分享過一篇如何做介面效能分析的文章,但是整個分析過程有點繁瑣,需要寫一個控制檯程式呼叫被測介面,再預熱、啟動dottrace追蹤,最後才能得到我們想要的效能分析報告。如果有辦法一鍵生成效能分析報告,那就會省很多不必要的時間。這裡我們就藉助Jenkins自動化完成這一過程。
目標:
把Dottrace的效能
VCSA 6.5 HA配置 之三 :準備工作
vmware vcenter ha 高可用 vcsa 接著上一篇文章部署完成VCSA 6.5後,還需要做一些準備工作才能開啟高可用功能,本篇文章主要就講述如何為vCenter 高可用進行準備工作配置vCenter HA網絡從vCenter HA的架構圖中可以看出對於vCenter HA的高
Linux學習之三:文件夾系統的結構和相對(絕對)路徑
sharp 二進制 沒有 數據 csharp pan 用戶 ont 臨時 理解每個目錄的作用
bin 二進制文件
boot 系統的啟動文件、內核
dev 設備文件
etc 配置文件
home 用戶的家目錄
lib 鏈接庫文件
l
RabbitMQ系列教程之三:發布/訂閱(Publish/Subscribe)
mqc 標題 整合 參數 cti 事情 return 控制臺 run (本教程是使用Net客戶端,也就是針對微軟技術平臺的) 在前一個教程中,我們創建了一個工作隊列。工作隊列背後的假設是每個任務會被交付給一個【工人】。在這一部分我們將做一些完全不同的事情--我們將向多個
OSPF詳解之三:OSPF LSA詳解
ospf lsa詳解 forwarding address OSPF LSA詳解OSPF V2版本中常用的主要有6類LSA,分別是Router-LSA、Network-LSA、Network-summary-LSA、ASBR-summary-LSA、AS-External-LSA、NSSA-LSA,接
Django運維後臺的搭建之三:用url去精細定制與反向解析
django 反向解析 參數傳遞 url指向 上一篇文章裏,我們做了一個alionlineecs(阿裏雲線上環境服務器)的添加界面,但是要知道我們的計劃裏是有六個分支的,而alionlineecs僅僅是其中之一,要是每一個都這麽寫的話,那麽views.py肯定又臭又長,充滿了大量的復制片段。對
camera攝像原理之三:色溫和自動白平衡【轉】
mil gho 實現 技術分享 處理 目標 紅旗 適應 如果 轉自:http://blog.csdn.net/ghostyu/article/details/7912863
色溫的定義:將黑體從絕對零度開始加溫,溫度每升高一度稱為1開氏度(用字母K表示),當溫度升高到一定
Halcon學習之三:有關圖像通道的函數
spa com detail too pan targe 個數 word pop 黑白攝像機會返回每個像素所對應的能量采用結果,這些結果組成了一幅單通道灰度值圖像,而對於RGB彩色攝像機,它將返回每個像素所對應的三個采樣結果,也就是一幅三通道圖像。下面這些是與圖像通道有關的
SoC嵌入式軟件架構設計之三:代碼分塊(Bank)設計原則
post 介紹 讀寫 cor 層次 clas rom bank 分配
上一節講述了在沒有MMU的CPU(如80251、MIPS M控制器系列、ARM cortex m系列)上實現虛擬內存管理的集成硬件設計方法。新設計的內存管理管理單元要實現虛擬內存管理還須要
初識Redis系列之三:Redis支持的數據類型及使用
ted print 數據類型 eight 排序 sorted ring hang 無序 支持的數據類型有五種:
string(字符串)、hash(哈希)、list(列表)、set(集合)及zset(sorted set:有序集合);
下面分別對這幾種類型進行簡單的Redis
緩存系列之三:redis安裝及基本數據類型命令使用
pytho children tile 指令 sed eject 檢測 install 文件的 一:Redis是一個開源的key-value存儲系統。與Memcached類似,Redis將大部分數據存儲在內存中,支持的數據類型包括:字符串、哈希表、鏈表、集合、有序集合以及基
SIPp常用腳本之三:UAC
pause rep iso sof app peer ati test level UAC是作為SIP消息的發起端,可以控制消息速率什麽的,方便極了。
一、uac.xml
<?xml version="1.0" encoding="ISO-8859-1" ?>