
非常詳細GC學習筆記
GC學習筆記
這是我公司同事的GC學習筆記,寫得蠻詳細的,由淺入深,循序漸進,讓人一看就懂,特轉到這裡。
一、GC特性以及各種GC的選擇
1、垃圾回收器的特性
2、對垃圾回收器的選擇
2.1 連續 VS. 並行
2.2 併發 VS. stop-the-world
2.3 壓縮 VS. 不壓縮 VS. 複製
二、GC效能指標
三、分代回收
四、J2SE 5.0的HotSpot JVM上的GC學習 - 分代、GC型別、快速分配
五、J2SE 5.0的HotSpot JVM上的GC學習 - SerialGC
六、J2SE 5.0的HotSpot JVM上的GC學習 - ParallelGC
七、J2SE 5.0
的HotSpot JVM上的GC學習 - ParallelCompactingGC八、J2SE 5.0的HotSpot JVM上的GC學習 - CMS GC
九、啟動引數學習示例
1. GC特性以及各種GC的選擇
1.1 垃圾回收器的特性
該回收的物件一定要回收,不該回收的物件一定不能回收
一定要有效,並且要快!儘可能少的暫停應用的執行
需要在時間,空間,回收頻率這三個要素中平衡
記憶體碎片的問題(一種解決記憶體碎片的方法,就是壓縮)
可擴充套件性和可伸縮性(記憶體的分配和回收,不應該成為跑在多核多執行緒應用上的瓶頸)
對垃圾回收器的選擇
1.2 連續 VS. 並行
連續垃圾回收器,即使在多核的應用中,在回收時,也只有一個核被利用。
但並行GC會使用多核,GC任務會被分離成多個子任務,然後這些子任務在各個CPU上並行執行。
並行GC的好處是讓GC的時間減少,但缺點是增加了複雜度,並且存在產生記憶體碎片的可能。
1.3 併發 VS. stop-the-world
當使用stop-the-world 方式的GC在執行時,整個應用會暫停住的。
而併發是指GC可以和應用一起執行,不用stop the world。
一般的說,併發GC可以做到大部分的執行時間,是可以和應用併發的,但還是有一些小任務,不得不短暫的stop the world。
stop the world 的GC相對簡單,因為heap被凍結,物件的活動也已經停止。但缺點是可能不太滿足對實時性要求很高的應用。
相應的,併發GC的stop the world時間非常短,並且需要做一些額外的事情,因為併發的時候,物件的引用狀態有可能發生改變的。
所以,併發GC需要花費更多的時間,並且需要較大的heap。
1.4 壓縮 VS. 不壓縮 VS. 複製
在GC確定記憶體中哪些是有用的物件,哪些是可回收的物件之後,他就可以壓縮記憶體,把擁有的物件放到一起,並把剩下的記憶體進行清理。
在壓縮之後,分配物件就會快很多,並且記憶體指標可以很快的指向下一個要分配的記憶體地址。
一個不壓縮的GC,就原地把不被引用的物件回收,他並沒有對記憶體進行壓縮。好處就是回收的速度變快了;缺點呢,就是產生了碎片。
一般來說,在有碎片的記憶體上分配一個物件的代價要遠遠大於在沒有碎片的記憶體上分配。
另外的選擇是使用一個複製演算法的GC,他是把所有被引用的物件複製到另外一個記憶體區域中。
使用複製GC的好處就是,原來的記憶體區域,就可以被毫無顧忌的清空了。但缺點也很明顯,需要更多的記憶體,以及額外的時間來複制。
2. GC效能指標
幾個評估GC效能的指標
吞吐量 應用花在非GC上的時間百分比
GC負荷 與吞吐量相反,指應用花在GC上的時間百分比
暫停時間 應用花在GC stop-the-world 的時間
GC頻率 顧名思義
Footprint 一些資源大小的測量,比如堆的大小
反應速度 從一個物件變成垃圾道這個物件被回收的時間
一個互動式的應用要求暫停時間越少越好,然而,一個非互動性的應用,當然是希望GC負荷越低越好。
一個實時系統對暫停時間和GC負荷的要求,都是越低越好。
一個嵌入式系統當然希望Footprint越小越好。
3. 分代回收
3.1 什麼是分代
當使用分代回收技術,記憶體會被分為幾個代(generation)。也就是說,按照物件存活的年齡,把物件放到不同的代中。
使用最廣泛的代,應屬年輕代和年老代了。
根據各種GC演算法的特徵,可以相應的被應用到不同的代中。
研究發現:
大部分的物件在分配後不久,就不被引用了。也就是,他們在很早就掛了。
只有很少的物件熬過來了。
年輕代的GC相當的頻繁,高效率並且快。因為年輕代通常比較小,並且很多物件都是不被引用的。
如果年輕代的物件熬過來了,那麼就晉級到年老代中了。如圖:
通常年老代要比年輕代大,而且增長也比較慢。所以GC在年老代發生的頻率非常低,不過一旦發生,就會佔據較長的時間。
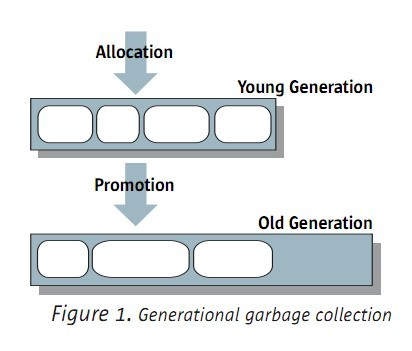
3.2 總結
年輕代通常使用時間佔優的GC,因為年輕代的GC非常頻繁
年老代通常使用善於處理大空間的GC,因為年老代的空間大,GC頻率低
4. J2SE 5.0的HotSpot JVM上的GC學習 - 分代、GC型別、快速分配
J2SE5.0 update 6 的HotSpot上有4個GC。
4.1 HotSpot上的分代
分成三部分:年輕代、年老代、永久代
很多的物件一開始是分配在年輕代的,這些物件在熬過了一定次數的young gc之後,就進入了年老代。同時,一些比較大的物件,一開始就可能被直接分配到年老代中(因為年輕代比較小嘛)。
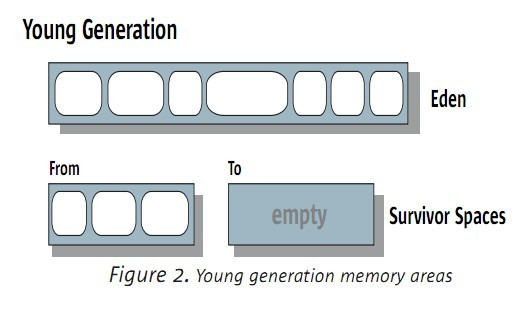
4.2 年輕代
年輕代也進行劃分,劃分成:一個Eden和兩個survivor。如下圖:
大部分的物件被直接分配到年輕代的eden區(之前已經提到了是,很大的物件會被直接分配到年老代中),
survivor區裡面放至少熬過一個YGC的物件,在survivor裡面的物件,才有機會被考慮提升到年老代中。
同一時刻,兩個survivor只被使用一個,另外一個是用來進行復制GC時使用的。
4.3 GC型別
年輕代的GC叫young GC,有時候也叫 minor GC。年老代或者永久代的GC,叫 full GC,也叫major GC。
也就是說,所有的代都會進行GC。
一般的,首先是進行年輕代的GC,(使用針對年輕代的GC),然後是年老代和永久代使用相同的GC。如果要壓縮(解決記憶體碎片問題),每個代需要分別壓縮。
有時候,如果年老區本身就已經很滿了,滿到無法放下從survivor熬出來的物件,那麼,YGC就不會再次觸發,而是會使用FullGC對整個堆進行GC(除了CMS這種GC,因為CMS不能對年輕代進行GC)
4.4 快速分配記憶體
多執行緒進行物件建立的時候,在為物件分配記憶體的時候,就應該保證執行緒安全,為此,就應該進入全域性鎖。但全域性鎖是非常消耗效能的。
為此,HotSpot引入了Thread Local Allocation Buffers (TLAB)技術,這種技術的原理就是為每個執行緒分配一個緩衝,用來分配執行緒自己的物件。
每個執行緒只使用自己的TLAB,這樣,就保證了不用使用全域性鎖。當TLAB不夠用的時候,才需要使用全域性鎖。但這時候對鎖的時候,頻率已經相當的低了。
為了減少TLAB對空間的消耗,分配器也想了很多方法,平均來說,TLAB佔用Eden區的不到1%。
5. J2SE 5.0的HotSpot JVM上的GC學習 - SerialGC
5.1 序列GC
序列GC,只使用單個CPU,並且會stop the world。
5.1.1 young 的序列GC
如下圖:
當發生ygc的時候,Eden和From的survivor區會將被引用的物件複製到To這個survivor種。
如果有些物件在To survivor放不下,則直接升級到年老區。
當YGC完成後,記憶體情況如下圖:
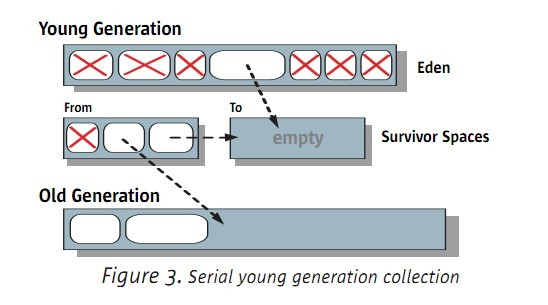
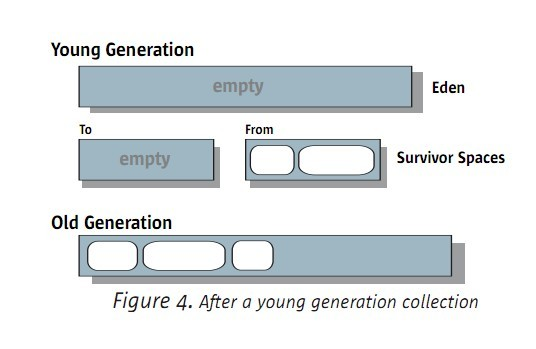
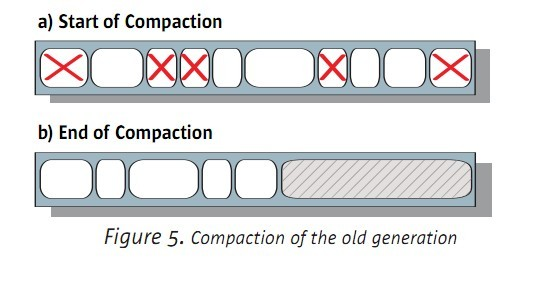
5.1.2 old區的序列GC
年老區和永久區使用的是Mark-Sweep-Compact的演算法。
mark階段是對有引用的物件進行標識
sweep是對垃圾進行清理
compact對把活著的物件進行遷移,解決記憶體碎片的問題
如下圖:
5.2 何時使用序列收集器
序列GC適用於對暫停時間要求不嚴,在客戶端下使用。
5.3 序列收集器的選擇
在J2SE5.0上,在非 server 模式下,JVM自動選擇序列收集器。
也可以顯示進行選擇,在java啟動引數中增加: -XX:+UseSerialGC 。
6. J2SE 5.0的HotSpot JVM上的GC學習 - ParallelGC
6.1 並行GC
現在已經有很多java應用跑在多核的機器上了。
並行的GC,也稱作吞吐量GC,這種GC把多個CPU都用上了,不讓CPU再空轉。
6.2 YGC的並行GC
YGC的情況,還是使用stop-the-world + 複製演算法的GC。
只不過是不再序列,而是充分利用多個CPU,減少GC負荷,增加吞吐量。
如下圖,序列YGC和並行YGC的比較:

6.3 年老區的並行GC
也是和序列GC一樣,在年老區和永久區使用Mark-Sweep-Compact,利用多核增加了吞吐量和減少GC負荷。
6.4 何時使用並行GC
對跑在多核的機器上,並且對暫停時間要求不嚴格的應用。因為頻率較低,但是暫停時間較長的Full GC還是會發生的。
6.5 選擇並行GC
在server模式下,並行GC會被自動選擇。
或者可以顯式選擇並行GC,加啟動JVM時加上引數: -XX:UseParallelGC
7. J2SE 5.0的HotSpot JVM上的GC學習 - ParallelCompactingGC
7.1 Parallel Compacting GC
parallelCompactingGC是在J2SE5.0 update6 引入的。
parallel compacting GC 與 parallel GC的不同地方,是在年老區的收集使用了一個新的演算法。並且以後,parallel compacting GC 會取代 parallem GC的。
7.2 YGC的並行壓縮GC
與並行GC使用的演算法一樣:stop-the-world 和 複製。
7.3 年老區的並行壓縮GC
他將把年老區和永久區從邏輯上劃分成等大的區域。
分為三個階段:
標記階段,使用多執行緒對存在引用的物件進行並行標記。
分析階段,GC對各個區域進行分析,GC認為,在經過上次GC後,越左邊的區域,有引用的物件密度要遠遠大於右邊的區域。所以就從左往右分析,當某個區域的密度達到一個值的時候,就認為這是一個臨界區域,所以這個臨界區域左邊的區域,將不會進行壓縮,而右邊的區域,則會進行壓縮。
壓縮階段,多各個需要壓縮的區域進行並行壓縮。
7.4 什麼時候使用並行壓縮GC
同樣的,適合在多核的機器上;並且此GC在FGC的時候,暫停時間會更短。
可以使用引數 -XX:ParallelGCThreads=n 來指定並行的執行緒數。
7.5 開啟並行壓縮GC
使用引數 -XX:+UseParallelOldGC
8. J2SE 5.0的HotSpot JVM上的GC學習 - CMS GC
8.1 Concurrent mark sweep GC
很多應用對響應時間的要求要大於吞吐量。
YGC並不暫停多少時間,但FGC對時間的暫用還是很長的。特別是在年老區使用的空間較多時。
因此, HotSpot引入了一個叫做CMS的收集器,也叫低延時收集器。
8.2 CMS的YGC
與並行GC同樣的方式: stop-the-world 加上 copy。
8.3 CMS的FGC
CMS的FGC在大部分是和應用程式一起併發的!
CMS在FGC的時候,一開始需要做一個短暫的暫停,這個階段稱為最初標記:識別所有被引用的物件。
在併發標記時候,會和應用程式一起執行。
因為併發標記是和程式一起執行的,所以在併發標記結束的時候,不能保證所有被引用的物件都被標記,
為了解決這個問題,GC又進行了一次暫停,這個階段稱為:重標識(remark)。
在這個過程中,GC會重新對在併發標階段時候有修改的物件做標記。
因為remark的暫停要大於最初標記,所以在這時候,需要使用多執行緒來並行標記。
在上述動作完成之後,就可以保證所有被引用的物件都被標記了。
因此,併發清理階段就可以併發的收集垃圾了。
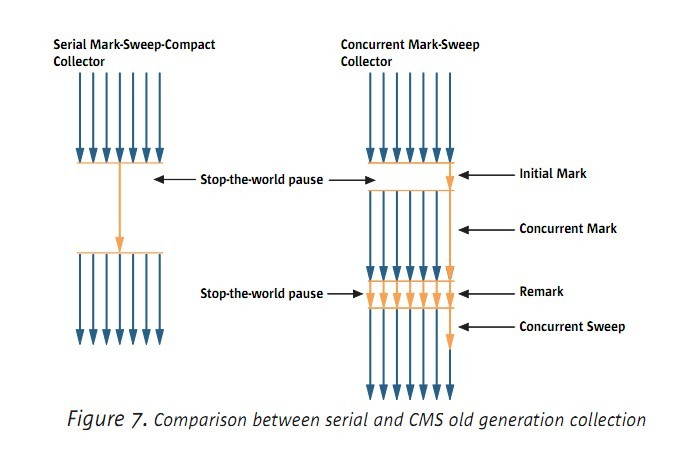
下圖是serial gc 和 CMS gc 的對比:
因為要增加很多額外的動作,比如對被引用的物件重新標記,增加了CMS的工作量,所以他的GC負荷也相應的增加。
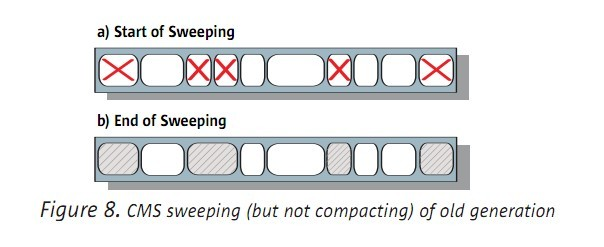
CMS是唯一沒有進行壓縮的GC。如下圖:
沒有壓縮,對於GC的過程,是節約了時間。但因此產生了記憶體碎片,所以對於新物件在年老區的分配,就產生了速度上的影響,
當然,也就包括了對YGC時間的影響了。
CMS的另一個缺點,就是他需要的堆比較大,因為在併發標記的時候和併發清除的時候,應用程式很有可能在不斷產生新的物件,而垃圾又還沒有被刪除。
另外,在最初標記之後的併發標記時,原先被引用的物件,有可能變成垃圾。但在這一次的GC中,這是沒有被刪除的。這種垃圾叫做:漂流垃圾。
最後,由於沒有進行壓縮,由此而帶來了記憶體碎片。
為了解決這個問題,CMS對熱點object大小進行了統計,並且估算之後的需求,然後把空閒的記憶體進行拆分或者合併來滿足後續的需求。
與其他的GC不同,CMS並不在年老區滿了之後才開始GC,他需要提前進行GC,用以滿足在GC同時需要額外的記憶體。
如果在GC的同時,記憶體不能滿足要求了,則GC就變成了並行GC或者序列GC。
為了防止這種情況,會根據上一次GC的統計來確定啟動時間。
或者是當年老區超過初始容量的話,CMS GC就會啟動。
初始容量的設定可以在JVM啟動時增加引數: -XX:CMSInitiatingOccupancyFraction=n
n是一個百分比,預設值為68。
總之,CMS比並行GC花費了更少的暫停時間,但是犧牲了吞吐量,以及需要更大的堆區。
8.4 額外模式
為了防止在併發標記的時候,GC執行緒長期佔用CPU,CMS可以把併發標記的時候停下來,把cpu讓給應用程式。
收集器會想併發標記分解成很小的時間串任務,在YGC之間來執行。
這個功能對於機器的CPU個數少,但又想降低暫停時間的應用來說,非常有用。
8.5 何時使用CMS
當CPU資源較空閒,並且需要很低的暫停時間時,可以選擇CMS。比如 web servers。
8.6 選擇CMS
選擇CMS GC: 增加引數 -XX:UseConcMarkSweepGC
開啟額外模式: 增加引數 -XX:+CMSIncreamentalMode
9. 結合線上啟動引數學習
線上的啟動引數
-Dprogram.name=run.sh -Xmx2g -Xms2g -Xmn256m -XX:PermSize=128m -Xss256k -XX:+DisableExplicitGC -XX:+UseConcMarkSweepGC -XX:+CMSParallelRemarkEnabled -XX:+UseCMSCompactAtFullCollection -XX:LargePageSizeInBytes=128m -XX:+UseFastAccessorMethods -XX:+UseCMSInitiatingOccupancyOnly -XX:CMSInitiatingOccupancyFraction=70 -Djava.awt.headless=true -Djava.net.preferIPv4Stack=true -Dcom.sun.management.config.file=/home/admin/web-deploy/conf/jmx/jmx_monitor_management.properties -Djboss.server.home.dir=/home/admin/web-deploy/jboss_server -Djboss.server.home.url=file\:/home/admin/web-deploy/jboss_server -Dapplication.codeset=GBK -Ddatabase.codeset=ISO-8859-1 -Ddatabase.logging=false -Djava.endorsed.dirs=/usr/alibaba/jboss/lib/endorsed
其中:
-Xmx2g -Xms2g 表示堆為2G
-Xmn256m 表示新生代為 256m
-Xss256k 設定每個執行緒的堆疊大小。JDK5.0以後每個執行緒堆疊大小為1M,以前每個執行緒堆疊大小為256K。更具應用的執行緒所需記憶體大小進行調整。在相同實體記憶體下,減小這個值能生成更多的執行緒。但是作業系統對一個程序內的執行緒數還是有限制的,不能無限生成,經驗值在3000~5000左右
-XX:PermSize=128m 表示永久區為128m
-XX:+DisableExplicitGC 禁用顯示的gc,程式程式中使用System.gc()中進行垃圾回收,使用這個引數後系統自動將 System.gc() 呼叫轉換成一個空操作
-XX:+UseConcMarkSweepGC 表示使用CMS
-XX:+CMSParallelRemarkEnabled 表示並行remark
-XX:+UseCMSCompactAtFullCollection 表示在FGC之後進行壓縮,因為CMS預設不壓縮空間的。
-XX:+UseCMSInitiatingOccupancyOnly 表示只在到達閥值的時候,才進行CMS GC
-XX:CMSInitiatingOccupancyFraction=70 設定閥值為70%,預設為68%。
-XX:+UseCompressedOops JVM優化之壓縮普通物件指標(CompressedOops),通常64位JVM消耗的記憶體會比32位的大1.5倍,這是因為物件指標在64位架構下,長度會翻倍(更寬的定址)。對於那些將要從32位平臺移植到64位的應用來說,平白無辜多了1/2的記憶體佔用,這是開發者不願意看到的。幸運的是,從JDK 1.6 update14開始,64 bit JVM正式支援了 -XX:+UseCompressedOops 這個可以壓縮指標,起到節約記憶體佔用的新引數.
關於-XX:+UseCMSInitiatingOccupancyOnly 和 -XX:CMSInitiatingOccupancyFraction ,詳細解釋見下:
The concurrent collection generally cannot be sped up but it can be started earlier.
A concurrent collection starts running when the percentage of allocated space in the old generation crosses a threshold. This threshold is calculated based on general experience with the concurrent collector. If full collections are occurring, the concurrent collections may need to be started earlier. The command line flag CMSInitiatingOccupancyFraction can be used to set the level at which the collection is started. Its default value is approximately 68%. The command line to adjust the value is
-XX:CMSInitiatingOccupancyFraction=<percent>
The concurrent collector also keeps statistics on the promotion rate into the old generation for the application and makes a prediction on when to start a concurrent collection based on that promotion rate and the available free space in the old generation. Whereas the use of CMSInitiatingOccupancyFraction must be conservative to avoid full collections over the life of the application, the start of a concurrent collection based on the anticipated promotion adapts to the changing requirements of the application. The statistics that are used to calculate the promotion rate are based on the recent concurrent collections. The promotion rate is not calculated until at least one concurrent collection has completed so at least the first concurrent collection has to be initiated because the occupancy has reached CMSInitiatingOccupancyFraction . Setting CMSInitiatingOccupancyFraction to 100 would not cause only the anticipated promotion to be used to start a concurrent collection but would rather cause only non-concurrent collections to occur since a concurrent collection would not start until it was already too late. To eliminate the use of the anticipated promotions to start a concurrent collection set UseCMSInitiatingOccupancyOnly to true.
-XX:+UseCMSInitiatingOccupancyOnly