
深度學習——Face Verificaton(人臉驗證)與Face Recognition(人臉識別)在FaceNet的應用案例
一、綜述
人臉識別領域主要有兩個範疇:Face Verificaton(人臉驗證)與Face Recognition(人臉識別)
1、Face Verificaton(人臉驗證):1:1的匹配問題。如果你有一張輸入圖片以及某人的ID或名字,
系統要做的是:驗證輸入照片是否是這個人。
在人臉驗證中,會看到兩張影象,並且必須告訴他們是否屬於同一個人。
最簡單的方法是逐個比較兩個影象,如果原始影象之間的距離小於選定的閾值,則它可能是同一個人!

不是使用原始影象,而是可以學習一個影象的編碼f(img),比較這種編碼影象的元素可以
更準確地判斷兩張圖片是否屬於同一個人。
2、Face Recognition(人臉識別):1:k的匹配
輸出:如果是在k個人臉庫中的人,輸出相應的ID,或者識別失敗。
3、該案例中實驗內容:
(1)構建 Triplet Loss 三元組損失函式
(2)使用預訓練模型將人臉影象對映到128維編碼向量
(3)使用這些編碼來執行Face Verificaton 臉部驗證 和 Face Recognition 臉部識別
二、FaceNet簡介
FaceNet學習一個神經網路,將人臉影象編碼為128維的數字向量作為提取的特徵 。
利用歐氏距離比較兩個這樣的向量,可以確定兩張圖片是否屬於同一個人。

從圖中可以看出,若取閾值為1.1,可以很輕易的區分出兩張照片是不是同一個人
網路結構:

上圖是文章中所採用的網路結構,其中,前半部分就是一個普通的卷積神經網路,
但是與一般的深度學習架構不一樣,Facenet沒有使用Softmax作為損失函式,而是先接了一個l2**嵌入(Embedding)層。
所謂嵌入,可以理解為一種對映關係,即將特徵從原來的特徵空間中對映到一個新的特徵空間,新的特徵就可以稱為原來特徵的一種嵌入。這裡的對映關係是將卷積神經網路末端全連線層輸出的特徵對映到一個超球面上,也就是使其特徵的二範數歸一化,然後再以Triplet Loss為監督訊號,獲得網路的損失與梯度。
三、Triplet Loss——三元組損失函式
也正是這篇文章的特點所在,接下來我們重點介紹一下。
顧名思義,Triplet Loss 三元組損失函式也就是:根據三張圖片組成的三元組(Triplet)計算而來的損失(Loss)。
其中,三元組由Anchor(A),Negative(N),Positive(P)組成,任意一張圖片都可以作為一個基點(A),然後與它屬於同一人的圖片就是它的P,與它屬於同一人的圖片就是它的N。
Triplet Loss的學習目標可以形象的表示如下圖:
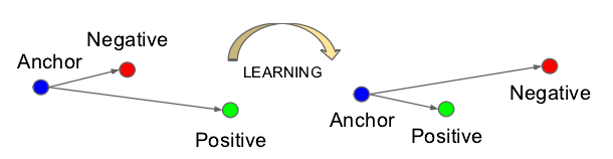
網路沒經過學習之前,A和P的歐式距離可能很大,A和N的歐式距離可能很小,如上圖左邊,在網路的學習過程中,A和P的歐式距離會逐漸減小,而A和N的距離會逐漸拉大。
也就是說,網路會直接學習特徵間的可分性:同一類的特徵之間的距離要儘可能的小,而不同類之間的特徵距離要儘可能的大。
意思就是說通過學習,使得類間的距離要大於類內的距離。
損失函式為:
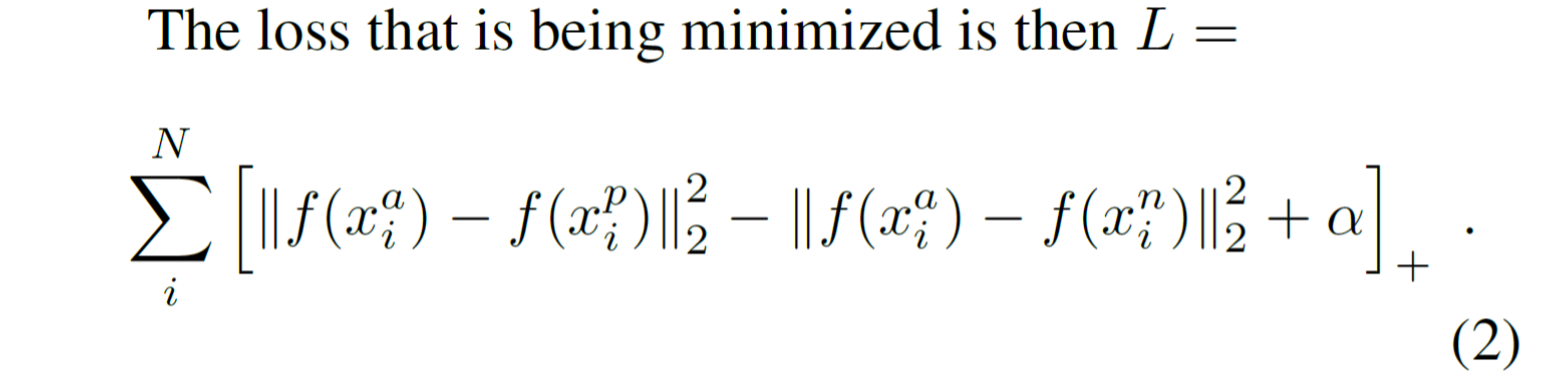
其中,左邊的二範數表示類內距離,右邊的二範數表示類間距離,α是一個常量。優化過程就是使用梯度下降法使得損失函式不斷下降,即類內距離不斷下降,類間距離不斷提升。
提出了這樣一種損失函式之後,實踐過程中,還有一個難題需要解決,也就是從訓練集裡選擇適合訓練的三元組。
選擇最佳的三元組
理論上說,為了保證網路訓練的效果最好,我們要選擇hard positive
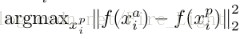
以及hard negative
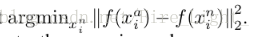
來作為我們的三元組。
但是實際上是這樣做會有問題:如果選擇最Hard的三元組會造成區域性極值,網路可能無法收斂至最優值。
因此google大佬們的做法是在mini-batch中挑選所有的 positive 影象對,因為這樣可以使得訓練的過程更加穩固。對於Negative的挑選,大佬們使用了semi-hard的Negative,也就是滿足a到n的距離大於a到p的距離的Negative,而不去選擇那些過難的Negative。
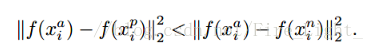
四、人臉驗證案例應用步驟詳解
(一)將人臉影象編碼成128維的向量
1、利用卷積神經網路執行影象的編碼
FaceNet網路模型利用很多的資料和很多的時間進行訓練的,因此,按照應用深度學習中的常見做法,
讓我們載入其他人已經預先訓練好的權重。網路架構遵循Szegedy等人的Inception v2模型。
提供了的一個初始網路的實現可以在檔案inception_v2.py中檢視它是如何實現的。
inception_v2.py檔案的程式碼如下:
import numpy as np
import tensorflow as tf
import os
from numpy import genfromtxt
from keras import backend as K
from keras.layers import Conv2D, ZeroPadding2D, Activation, Input, concatenate
from keras.models import Model
from keras.layers.normalization import BatchNormalization
from keras.layers.pooling import MaxPooling2D, AveragePooling2D
import fr_utils
from keras.layers.core import Lambda, Flatten, Dense
import tensorflow.contrib.slim as slim
def inception_block_1a(X):
"""
Implementation of an inception block
"""
X_3x3 = Conv2D(96, (1, 1), data_format='channels_first', name='inception_3a_3x3_conv1')(X)
X_3x3 = BatchNormalization(axis=1, epsilon=0.00001, name='inception_3a_3x3_bn1')(X_3x3)
X_3x3 = Activation('relu')(X_3x3)
X_3x3 = ZeroPadding2D(padding=(1, 1), data_format='channels_first')(X_3x3)
X_3x3 = Conv2D(128, (3, 3), data_format='channels_first', name='inception_3a_3x3_conv2')(X_3x3)
X_3x3 = BatchNormalization(axis=1, epsilon=0.00001, name='inception_3a_3x3_bn2')(X_3x3)
X_3x3 = Activation('relu')(X_3x3)
X_5x5 = Conv2D(16, (1, 1), data_format='channels_first', name='inception_3a_5x5_conv1')(X)
X_5x5 = BatchNormalization(axis=1, epsilon=0.00001, name='inception_3a_5x5_bn1')(X_5x5)
X_5x5 = Activation('relu')(X_5x5)
X_5x5 = ZeroPadding2D(padding=(2, 2), data_format='channels_first')(X_5x5)
X_5x5 = Conv2D(32, (5, 5), data_format='channels_first', name='inception_3a_5x5_conv2')(X_5x5)
X_5x5 = BatchNormalization(axis=1, epsilon=0.00001, name='inception_3a_5x5_bn2')(X_5x5)
X_5x5 = Activation('relu')(X_5x5)
X_pool = MaxPooling2D(pool_size=3, strides=2, data_format='channels_first')(X)
X_pool = Conv2D(32, (1, 1), data_format='channels_first', name='inception_3a_pool_conv')(X_pool)
X_pool = BatchNormalization(axis=1, epsilon=0.00001, name='inception_3a_pool_bn')(X_pool)
X_pool = Activation('relu')(X_pool)
X_pool = ZeroPadding2D(padding=((3, 4), (3, 4)), data_format='channels_first')(X_pool)
X_1x1 = Conv2D(64, (1, 1), data_format='channels_first', name='inception_3a_1x1_conv')(X)
X_1x1 = BatchNormalization(axis=1, epsilon=0.00001, name='inception_3a_1x1_bn')(X_1x1)
X_1x1 = Activation('relu')(X_1x1)
# CONCAT
inception = concatenate([X_3x3, X_5x5, X_pool, X_1x1], axis=1)
return inception
def inception_block_1b(X):
X_3x3 = Conv2D(96, (1, 1), data_format='channels_first', name='inception_3b_3x3_conv1')(X)
X_3x3 = BatchNormalization(axis=1, epsilon=0.00001, name='inception_3b_3x3_bn1')(X_3x3)
X_3x3 = Activation('relu')(X_3x3)
X_3x3 = ZeroPadding2D(padding=(1, 1), data_format='channels_first')(X_3x3)
X_3x3 = Conv2D(128, (3, 3), data_format='channels_first', name='inception_3b_3x3_conv2')(X_3x3)
X_3x3 = BatchNormalization(axis=1, epsilon=0.00001, name='inception_3b_3x3_bn2')(X_3x3)
X_3x3 = Activation('relu')(X_3x3)
X_5x5 = Conv2D(32, (1, 1), data_format='channels_first', name='inception_3b_5x5_conv1')(X)
X_5x5 = BatchNormalization(axis=1, epsilon=0.00001, name='inception_3b_5x5_bn1')(X_5x5)
X_5x5 = Activation('relu')(X_5x5)
X_5x5 = ZeroPadding2D(padding=(2, 2), data_format='channels_first')(X_5x5)
X_5x5 = Conv2D(64, (5, 5), data_format='channels_first', name='inception_3b_5x5_conv2')(X_5x5)
X_5x5 = BatchNormalization(axis=1, epsilon=0.00001, name='inception_3b_5x5_bn2')(X_5x5)
X_5x5 = Activation('relu')(X_5x5)
X_pool = AveragePooling2D(pool_size=(3, 3), strides=(3, 3), data_format='channels_first')(X)
X_pool = Conv2D(64, (1, 1), data_format='channels_first', name='inception_3b_pool_conv')(X_pool)
X_pool = BatchNormalization(axis=1, epsilon=0.00001, name='inception_3b_pool_bn')(X_pool)
X_pool = Activation('relu')(X_pool)
X_pool = ZeroPadding2D(padding=(4, 4), data_format='channels_first')(X_pool)
X_1x1 = Conv2D(64, (1, 1), data_format='channels_first', name='inception_3b_1x1_conv')(X)
X_1x1 = BatchNormalization(axis=1, epsilon=0.00001, name='inception_3b_1x1_bn')(X_1x1)
X_1x1 = Activation('relu')(X_1x1)
inception = concatenate([X_3x3, X_5x5, X_pool, X_1x1], axis=1)
return inception
def inception_block_1c(X):
X_3x3 = fr_utils.conv2d_bn(X,
layer='inception_3c_3x3',
cv1_out=128,
cv1_filter=(1, 1),
cv2_out=256,
cv2_filter=(3, 3),
cv2_strides=(2, 2),
padding=(1, 1))
X_5x5 = fr_utils.conv2d_bn(X,
layer='inception_3c_5x5',
cv1_out=32,
cv1_filter=(1, 1),
cv2_out=64,
cv2_filter=(5, 5),
cv2_strides=(2, 2),
padding=(2, 2))
X_pool = MaxPooling2D(pool_size=3, strides=2, data_format='channels_first')(X)
X_pool = ZeroPadding2D(padding=((0, 1), (0, 1)), data_format='channels_first')(X_pool)
inception = concatenate([X_3x3, X_5x5, X_pool], axis=1)
return inception
def inception_block_2a(X):
X_3x3 = fr_utils.conv2d_bn(X,
layer='inception_4a_3x3',
cv1_out=96,
cv1_filter=(1, 1),
cv2_out=192,
cv2_filter=(3, 3),
cv2_strides=(1, 1),
padding=(1, 1))
X_5x5 = fr_utils.conv2d_bn(X,
layer='inception_4a_5x5',
cv1_out=32,
cv1_filter=(1, 1),
cv2_out=64,
cv2_filter=(5, 5),
cv2_strides=(1, 1),
padding=(2, 2))
X_pool = AveragePooling2D(pool_size=(3, 3), strides=(3, 3), data_format='channels_first')(X)
X_pool = fr_utils.conv2d_bn(X_pool,
layer='inception_4a_pool',
cv1_out=128,
cv1_filter=(1, 1),
padding=(2, 2))
X_1x1 = fr_utils.conv2d_bn(X,
layer='inception_4a_1x1',
cv1_out=256,
cv1_filter=(1, 1))
inception = concatenate([X_3x3, X_5x5, X_pool, X_1x1], axis=1)
return inception
def inception_block_2b(X):
# inception4e
X_3x3 = fr_utils.conv2d_bn(X,
layer='inception_4e_3x3',
cv1_out=160,
cv1_filter=(1, 1),
cv2_out=256,
cv2_filter=(3, 3),
cv2_strides=(2, 2),
padding=(1, 1))
X_5x5 = fr_utils.conv2d_bn(X,
layer='inception_4e_5x5',
cv1_out=64,
cv1_filter=(1, 1),
cv2_out=128,
cv2_filter=(5, 5),
cv2_strides=(2, 2),
padding=(2, 2))
X_pool = MaxPooling2D(pool_size=3, strides=2, data_format='channels_first')(X)
X_pool = ZeroPadding2D(padding=((0, 1), (0, 1)), data_format='channels_first')(X_pool)
inception = concatenate([X_3x3, X_5x5, X_pool], axis=1)
return inception
def inception_block_3a(X):
X_3x3 = fr_utils.conv2d_bn(X,
layer='inception_5a_3x3',
cv1_out=96,
cv1_filter=(1, 1),
cv2_out=384,
cv2_filter=(3, 3),
cv2_strides=(1, 1),
padding=(1, 1))
X_pool = AveragePooling2D(pool_size=(3, 3), strides=(3, 3), data_format='channels_first')(X)
X_pool = fr_utils.conv2d_bn(X_pool,
layer='inception_5a_pool',
cv1_out=96,
cv1_filter=(1, 1),
padding=(1, 1))
X_1x1 = fr_utils.conv2d_bn(X,
layer='inception_5a_1x1',
cv1_out=256,
cv1_filter=(1, 1))
inception = concatenate([X_3x3, X_pool, X_1x1], axis=1)
return inception
def inception_block_3b(X):
X_3x3 = fr_utils.conv2d_bn(X,
layer='inception_5b_3x3',
cv1_out=96,
cv1_filter=(1, 1),
cv2_out=384,
cv2_filter=(3, 3),
cv2_strides=(1, 1),
padding=(1, 1))
X_pool = MaxPooling2D(pool_size=3, strides=2, data_format='channels_first')(X)
X_pool = fr_utils.conv2d_bn(X_pool,
layer='inception_5b_pool',
cv1_out=96,
cv1_filter=(1, 1))
X_pool = ZeroPadding2D(padding=(1, 1), data_format='channels_first')(X_pool)
X_1x1 = fr_utils.conv2d_bn(X,
layer='inception_5b_1x1',
cv1_out=256,
cv1_filter=(1, 1))
inception = concatenate([X_3x3, X_pool, X_1x1], axis=1)
return inception
def faceRecoModel(input_shape):
"""
FaceNet網路採用Inception模型進行訓練
Arguments:
input_shape -- 資料集中影象的形狀
Returns:
model -- Keras中的初始化一個函式式模型Model()
"""
# 將輸入定義為具有形狀input_shape的張量
X_input = Input(input_shape)
# Zero-Padding
X = ZeroPadding2D((3, 3))(X_input)
# First Block
X = Conv2D(64, (7, 7), strides=(2, 2), name='conv1')(X)
X = BatchNormalization(axis=1, name='bn1')(X)
X = Activation('relu')(X)
# Zero-Padding + MAXPOOL
X = ZeroPadding2D((1, 1))(X)
X = MaxPooling2D((3, 3), strides=2)(X)
# Second Block
X = Conv2D(64, (1, 1), strides=(1, 1), name='conv2')(X)
X = BatchNormalization(axis=1, epsilon=0.00001, name='bn2')(X)
X = Activation('relu')(X)
# Zero-Padding + MAXPOOL
X = ZeroPadding2D((1, 1))(X)
# Second Block
X = Conv2D(192, (3, 3), strides=(1, 1), name='conv3')(X)
X = BatchNormalization(axis=1, epsilon=0.00001, name='bn3')(X)
X = Activation('relu')(X)
# Zero-Padding + MAXPOOL
X = ZeroPadding2D((1, 1))(X)
X = MaxPooling2D(pool_size=3, strides=2)(X)
# Inception 1: a/b/c
X = inception_block_1a(X)
X = inception_block_1b(X)
X = inception_block_1c(X)
# Inception 2: a/b
X = inception_block_2a(X)
X = inception_block_2b(X)
# Inception 3: a/b
X = inception_block_3a(X)
X = inception_block_3b(X)
# Top layer
X = AveragePooling2D(pool_size=(3, 3), strides=(1, 1), data_format='channels_first')(X)
X = Flatten()(X)
X = Dense(128, name='dense_layer')(X)
# L2 normalization
X = Lambda(lambda x: K.l2_normalize(x, axis=1))(X)
# Create model instance
model = Model(inputs=X_input, outputs=X, name='FaceRecoModel')
return model其中,fr_utils.py檔案下的conv2d_bn函式的程式碼為:
def conv2d_bn(x,
layer=None,
cv1_out=None,
cv1_filter=(1, 1),
cv1_strides=(1, 1),
cv2_out=None,
cv2_filter=(3, 3),
cv2_strides=(1, 1),
padding=None):
num = '' if cv2_out == None else '1'
tensor = Conv2D(cv1_out, cv1_filter, strides=cv1_strides, data_format='channels_first', name=layer + '_conv' + num)(
x)
tensor = BatchNormalization(axis=1, epsilon=0.00001, name=layer + '_bn' + num)(tensor)
tensor = Activation('relu')(tensor)
if padding == None:
return tensor
tensor = ZeroPadding2D(padding=padding, data_format='channels_first')(tensor)
if cv2_out == None:
return tensor
tensor = Conv2D(cv2_out, cv2_filter, strides=cv2_strides, data_format='channels_first', name=layer + '_conv' + '2')(
tensor)
tensor = BatchNormalization(axis=1, epsilon=0.00001, name=layer + '_bn' + '2')(tensor)
tensor = Activation('relu')(tensor)
return tensor注意:這個FaceNet網路採用的是96*96的彩色RGB作為輸入,特別地,將m張人臉影象作為一個張量,
形狀為(m,nc,nh,nw) = (m,3,96,96),輸出為形狀為(m,128)的矩陣,將每個輸入的臉部影象轉換成128維的向量。
最後的全連線層採用128個神經元,該模型確保輸出是尺寸為128維的編碼向量。然後比較編碼後的兩個人臉影象,如下所示:

通過計算兩個編碼影象的歐氏距離,並與設定的閾值進行比較就可以確定兩張圖片是否代表同一個人。
訓練系統,確保:同一人的兩幅影象的編碼非常相似(距離很近),兩幅不同人物影象的編碼有很大不同(距離儘可能遠)。
(二)、定義Triplet Loss ——三元組損失函式
三元組損失函式:將同一人的兩個影象(Anchor 和 Positive)的編碼之間的距離“拉”到更近的位置(最小化),
同時將兩個不同人的影象(Anchor 和 Negative)的編碼之間的距離“拉”得更遠(最大化)。
原理示意圖如下所示:將從左到右呼叫圖片 Anchor(A),Positive(P),Negative(N)

對於一張圖片x,我們定義它編碼後的影象用 f(x) 表示,其中 f 是由神經網路計算的函式。

訓練系統需要通過三元組的影象(A,P,N),其中:
A:“Anchor”影象,是一個人的圖片;P:“Positive”影象,與“Anchor”為同一個人的影象;
N:“Negative”影象,與“Anchor”為不同人的影象。
這些構成三元組的影象是從我們的訓練資料集中挑選出來的,定義
訓練要確保某個人“Anchor”


至少一個

因此,最小化下面的三元組目標函式:

注:採用標註


另外,第一段(1)是表示給定三元組的Anchor“A”和Positive“P”之間的平方距離(歐氏距離), 希望這個值很小。
第二段(2)是表示給定三元組的Anchor“A”和Negative“N”之間的平方距離(歐氏距離), 希望這個值比較大,在它前面有一個負號是合理的。
小結:三元組損失函式的定義分為以下四個步驟:
(1)計算“anchor”和“positive”編碼後影象的歐式距離(A,P,N)
(2)計算“anchor”和“negative”編碼後圖像的歐氏距離

(3)對於每一個訓練樣本計算

(4)優化目標函式

(5)三元組損失函式的構建及測試
#多個網路層的堆疊,通過向Sequential模型傳遞一個layer的list來構造該模型
from keras.models import Sequential
from keras.models import Model
from keras.layers.merge import Concatenate
from keras.layers import Conv2D,ZeroPadding2D,Activation,Input,concatenate
from keras.layers.normalization import BatchNormalization
from keras.layers.pooling import MaxPooling2D,AveragePooling2D
# Flatten層將多維的輸入一維化,常用在卷積層和全連線層的過渡
# Dense層是常用的全連線層
from keras.layers.core import Lambda,Flatten,Dense
from keras.initializers import glorot_uniform #基於uniform均勻分佈的初始化方式
from keras.engine.topology import Layer
from keras import backend as K
K.set_image_data_format("channels_first") #設定影象維度順序
# import cv2
import os
import numpy as np
from numpy import genfromtxt #建立陣列表格資料
import pandas as pd
import tensorflow as tf
# from fr_utils import *
# from inception_v2 import *
#當ndarray裡面的存放的資料維度過大時,在控制檯會出現不能將ndarray完全
# 輸出情況,中間部分的結果會用省略號打印出來.
np.set_printoptions(threshold=np.nan)
# FRmodel = faceRecoModel(input_shape=(3, 96, 96))
#三元組損失函式的構建
def triplet_loss(y_true,y_pred,alpha=0.2):
"""
Arguments:
y_true:真正的標籤值,在keras中定義損失函式時不需要它
y_pred:Python列表,包含三個物件:
anchor -- anchor影象的編碼, 形狀為(None, 128)
positive -- positive影象的編碼, 形狀為(None, 128)
negative -- negative影象的編碼, 形狀為(None, 128)
alpha:間隔/超引數
return:
loss -- 真實的數字,損失值
"""
anchor,positive,negative = y_pred[0],y_pred[1],y_pred[2]
#1、計算編碼後所有的“anchor”和“positive”影象的歐式距離
#tf.subtract:減,tf.square:平方,reduce_sum(x,axis=1):對x按列(這裡是特徵)相加
pos_dist = tf.reduce_sum(tf.square(tf.subtract(anchor,positive)))
# 2、計算編碼後所有的“anchor”和“negative”影象的歐式距離
neg_dist = tf.reduce_sum(tf.square(tf.subtract(anchor,negative)))
#3、前兩個距離相減並加上alpha
bias_dist = pos_dist - neg_dist + alpha
#4、求bias_dist和0的最大值,並對訓練樣本求和
#reduce_sum(x,axis=0):對x按行(這裡是所有的訓練樣本)相加
loss = tf.reduce_sum(tf.maximum(bias_dist,0))
return loss
#測試
with tf.Session() as sess:
tf.set_random_seed(1)
y_true = (None,None,None)
y_pred = (tf.random_normal([3,128],mean=6,stddev=0.1,seed=1),
tf.random_normal([3,128],mean=1,stddev=1,seed=1),
tf.random_normal([3,128],mean=3,stddev=4,seed=1))
loss = triplet_loss(y_true,y_pred)
print("loss = ",sess.run(loss))
#執行結果:
loss = 528.1432(三)、載入預訓練的模型
FaceNet是通過最小化三元組損失函式進行訓練的,訓練需要大量的資料和計算,在這裡我們不是直接訓練,
我們載入預先訓練好的模型如下,執行需要幾分鐘的時間:
FRmodel.compile(optimizer = 'adam', loss = triplet_loss, metrics = ['accuracy'])
load_weights_from_FaceNet(FRmodel)其中,load_weights_from_faceNet函式的具體程式碼如下:
WEIGHTS = [
'conv1', 'bn1', 'conv2', 'bn2', 'conv3', 'bn3',
'inception_3a_1x1_conv', 'inception_3a_1x1_bn',
'inception_3a_pool_conv', 'inception_3a_pool_bn',
'inception_3a_5x5_conv1', 'inception_3a_5x5_conv2', 'inception_3a_5x5_bn1', 'inception_3a_5x5_bn2',
'inception_3a_3x3_conv1', 'inception_3a_3x3_conv2', 'inception_3a_3x3_bn1', 'inception_3a_3x3_bn2',
'inception_3b_3x3_conv1', 'inception_3b_3x3_conv2', 'inception_3b_3x3_bn1', 'inception_3b_3x3_bn2',
'inception_3b_5x5_conv1', 'inception_3b_5x5_conv2', 'inception_3b_5x5_bn1', 'inception_3b_5x5_bn2',
'inception_3b_pool_conv', 'inception_3b_pool_bn',
'inception_3b_1x1_conv', 'inception_3b_1x1_bn',
'inception_3c_3x3_conv1', 'inception_3c_3x3_conv2', 'inception_3c_3x3_bn1', 'inception_3c_3x3_bn2',
'inception_3c_5x5_conv1', 'inception_3c_5x5_conv2', 'inception_3c_5x5_bn1', 'inception_3c_5x5_bn2',
'inception_4a_3x3_conv1', 'inception_4a_3x3_conv2', 'inception_4a_3x3_bn1', 'inception_4a_3x3_bn2',
'inception_4a_5x5_conv1', 'inception_4a_5x5_conv2', 'inception_4a_5x5_bn1', 'inception_4a_5x5_bn2',
'inception_4a_pool_conv', 'inception_4a_pool_bn',
'inception_4a_1x1_conv', 'inception_4a_1x1_bn',
'inception_4e_3x3_conv1', 'inception_4e_3x3_conv2', 'inception_4e_3x3_bn1', 'inception_4e_3x3_bn2',
'inception_4e_5x5_conv1', 'inception_4e_5x5_conv2', 'inception_4e_5x5_bn1', 'inception_4e_5x5_bn2',
'inception_5a_3x3_conv1', 'inception_5a_3x3_conv2', 'inception_5a_3x3_bn1', 'inception_5a_3x3_bn2',
'inception_5a_pool_conv', 'inception_5a_pool_bn',
'inception_5a_1x1_conv', 'inception_5a_1x1_bn',
'inception_5b_3x3_conv1', 'inception_5b_3x3_conv2', 'inception_5b_3x3_bn1', 'inception_5b_3x3_bn2',
'inception_5b_pool_conv', 'inception_5b_pool_bn',
'inception_5b_1x1_conv', 'inception_5b_1x1_bn',
'dense_layer'
]
def load_weights():
# Set weights path
dirPath = './weights'
fileNames = filter(lambda f: not f.startswith('.'), os.listdir(dirPath))
paths = {}
weights_dict = {}
for n in fileNames:
paths[n.replace('.csv', '')] = dirPath + '/' + n
for name in WEIGHTS:
if 'conv' in name:
conv_w = genfromtxt(paths[name + '_w'], delimiter=',', dtype=None)
conv_w = np.reshape(conv_w, conv_shape[name])
conv_w = np.transpose(conv_w, (2, 3, 1, 0))
conv_b = genfromtxt(paths[name + '_b'], delimiter=',', dtype=None)
weights_dict[name] = [conv_w, conv_b]
elif 'bn' in name:
bn_w = genfromtxt(paths[name + '_w'], delimiter=',', dtype=None)
bn_b = genfromtxt(paths[name + '_b'], delimiter=',', dtype=None)
bn_m = genfromtxt(paths[name + '_m'], delimiter=',', dtype=None)
bn_v = genfromtxt(paths[name + '_v'], delimiter=',', dtype=None)
weights_dict[name] = [bn_w, bn_b, bn_m, bn_v]
elif 'dense' in name:
dense_w = genfromtxt(dirPath + '/dense_w.csv', delimiter=',', dtype=None)
dense_w = np.reshape(dense_w, (128, 736))
dense_w = np.transpose(dense_w, (1, 0))
dense_b = genfromtxt(dirPath + '/dense_b.csv', delimiter=',', dtype=None)
weights_dict[name] = [dense_w, dense_b]
return weights_dict
def load_weights_from_FaceNet(FRmodel):
# Load weights from csv files (which was exported from Openface torch model)
weights = WEIGHTS
weights_dict = load_weights()
# Set layer weights of the model
for name in weights:
if FRmodel.get_layer(name) != None:
FRmodel.get_layer(name).set_weights(weights_dict[name])
elif FRmodel.get_layer(name) != None:
FRmodel.get_layer(name).set_weights(weights_dict[name])(四)、人臉驗證(Face Verification)模型的應用
建立一個數據庫,其中包含每個人的影象編碼向量,我們採用函式img_to_encoding函式得到每個影象的編碼向量,
它基本上在指定的影象上執行前向傳播的模型,程式碼如下:
def img_to_encoding(image_path, model):
img1 = cv2.imread(image_path, 1)
img = img1[..., ::-1]
img = np.around(np.transpose(img, (2, 0, 1)) / 255.0, decimals=12)
x_train = np.array([img])
embedding = model.predict_on_batch(x_train)
return embedding執行程式碼構建資料庫(以Python字典表示), 該資料庫將每個人的姓名對應於他們臉部影象的128維編碼。
現在,當有人出現在你的門前並刷他們的身份證(因此給你的名字)時,你可以在資料庫中查詢他們的編碼,
並用它來驗證站在前門的人是否與資料中的人匹配。
執行函式verify()驗證門前攝像頭影象(image_path)是否與資料庫比對的人的身份一致,分為以下步驟:
(1)從image_path路徑中計算影象的編碼。
(2)計算關於此編碼影象與儲存在資料庫中的需要比對身份的人的編碼影象之間的歐式距離(3)如果距離小於0.7則表示驗證同一個的身份成功,否則驗證失敗。
#人臉驗證
def verify(image_path, identity, database, model):
"""
驗證"image_path" 路徑下編碼的人臉影象與待比對的人的身份是否一致
Arguments:
image_path -- 影象的路徑
identity -- 字串型別, 需要驗證的人的身份名稱
database -- python字典,將人名(字串)對映到它們的影象編碼(向量)
model -- Keras下Inception v2模型
Returns:
dist -- image_path和資料庫待比對人的編碼影象的距離
door_open -- True,門開啟. False 門不開.
"""
# 1: 用img_to_encoding()函式來計算影象的編碼
encoding = img_to_encoding(image_path, model)
# 2: 計算待比對的兩幅圖片的歐氏距離
dist = np.linalg.norm(encoding - database[identity], ord=2) #二範數/歐式距離
# print("dist=",dist)
# 3: 如果距離小於0.7則開門,否則不開
if dist < 0.75:
print("It's " + str(identity) + ", welcome home!")
door_open = True
else:
print("It's not " + str(identity) + ", please go away")
door_open = False
return dist, door_open
database = {}
dist_list = []
siml_list = []
#迴圈讀取兩個資料夾裡面待比對的影象並編碼,依照歐氏距離進行判定
for i in range(1,51):
filename1 = str(i)
filename2 = str(i)+"a"
database[filename1] = img_to_encoding("images1/"+filename1 + ".jpg", FRmodel)
dist, door_open = verify("images2/"+filename2 + ".jpg", filename1, database, FRmodel)
#將距離和開門狀態的結果分別新增到兩個列表中
dist_list.append(dist)
siml_list.append(door_open)
print("dist_list = ",dist_list)
print("siml_list = ",siml_list)
print("Accuracy:",siml_list.count(True)/len(siml_list))
#將距離和開門狀態的結果利用pandas儲存到csv的檔案中
distance = pd.DataFrame(data={"similar":siml_list,"distance":dist_list})
distance.to_csv("E:/Image_Similarity/dist_siml.csv")五、人臉識別案例應用步驟詳解
未完待續