
網路爬蟲初步:從一個入口連結開始不斷抓取頁面中的網址併入庫
前言:
在上一篇《網路爬蟲初步:從訪問網頁到資料解析》中,我們討論瞭如何爬取網頁,對爬取的網頁進行解析,以及訪問被拒絕的網站。在這一篇部落格中,我們可以來了解一下拿到解析的資料可以做的事件。在這篇部落格中,我主要是說明要做的兩件事,一是入庫,二是遍歷拿到的連結繼續訪問。如此往復,這樣就構成了一個網路爬蟲的雛形。
筆者環境:
系統: Windows 7
CentOS 6.5
執行環境: JDK 1.7
Python 2.6.6
IDE: Eclipse Release 4.2.0
PyCharm 4.5.1
資料庫: MySQL Ver 14.14 Distrib 5.1.73
效果圖:
這裡只擷取開始的一部分資料。這些資料我是儲存在MySQL中的。

思路梳理:
前面說到,我們拿到資料要做兩件:資料儲存與資料分析。
我們整個邏輯過程是這樣的:
1.Java傳遞連結引數給Python;
2.Python解析HTML返回必要資訊給Java;
3.Java拿到資料進行入庫;
4.對解析出的有效連結進行繼續遍歷(這裡是採用圖的廣度優先遍歷)
5.反覆以上的4個步驟,直到沒有可繼續訪問的有效連結為止,這裡是使用遞迴迭代。
關於資料儲存,倒是沒有什麼好說的。因為我是在Linux(CentOS)下執行程式的。所以,你的Linux中必須要有MySQL,另外,我是通過Java來進行資料庫操作的,所以這裡你的系統中也有要Mysql的Java驅動包。
開發過程:
1.Python解析資料
get_html_response.py
# encoding=utf-8 import HTMLParser import utils as utils class ListWebParser(HTMLParser.HTMLParser): def __init__(self): HTMLParser.HTMLParser.__init__(self) self.tagAFlag = False self._name = None self._address = None self._info = [] def handle_starttag(self, tag, attrs): if tag == 'a': for name, value in attrs: if name == 'href' and utils.isMatch(value, '^http'): self._info.append((self._name, self._address)) self.tagAFlag = True self._address = value self._name = None # print 'Address: ', value def handle_endtag(self, tag): if tag == 'a': self.tagAFlag = False def handle_data(self, data): if self.tagAFlag: name = data.decode('utf-8') if self._name: self._name = str(self._name) + ' ' + name else: self._name = name def getLinkList(self): return self._info
html_parser.py
# encoding=utf-8
'''
對Html檔案進行解析
'''
import sys
reload(sys)
sys.setdefaultencoding('utf8')
from list_web_parser import ListWebParser
import get_html_response as geth
def main(html):
myp = ListWebParser()
get_html = geth.get_html_response(html)
myp.feed(get_html)
link_list = myp.getLinkList()
myp.close()
for item in link_list:
if item[0] and item[1]:
print item[0], '$#$', item[1]
if __name__ == "__main__":
if not sys.argv or len(sys.argv) < 2:
print 'You leak some arg.' # http://www.cnblogs.com/Stone-sqrt3/
main(sys.argv[1])2.Java入庫
對於Java中對資料庫的操作,也沒什麼好說說明的。如果你寫地JDBC,那麼這對於你而言將是小菜一碟。關鍵程式碼如下:
public class DBServer {
private String mUrl = DBModel.getMysqlUrl();
private String mUser = DBModel.getMysqlUesr();
private String mPassword = DBModel.getMysqlPassword();
private String mDriver = DBModel.getMysqlDerver();
private Connection mConn = null;
private Statement mStatement = null;
public DBServer() {
initEvent();
}
private void initEvent() {
mUrl = DBModel.getMysqlUrl();
mUser = DBModel.getMysqlUesr();
mPassword = DBModel.getMysqlPassword();
mDriver = DBModel.getMysqlDerver();
try {
Class.forName(mDriver).newInstance();
mConn = DriverManager.getConnection(mUrl, mUser, mPassword);
mStatement = mConn.createStatement();
} catch (Exception e) {
e.printStackTrace();
}
}
/**
* 資料庫查詢
* TODO
* DBServer
* @param sql
* 查詢的sql語句
*/
public void select(String sql) {
try {
ResultSet rs = mStatement.executeQuery(sql);
while (rs.next()) {
String name = rs.getString("name");
System.out.println(name);
}
rs.close();
} catch (SQLException e) {
e.printStackTrace();
}
}
/**
* 插入新資料
* DBServer
* @param sql
* 插入的sql語句
*/
public int insert(String sql) {
try {
int raw = mStatement.executeUpdate(sql);
return raw;
} catch (SQLException e) {
e.printStackTrace();
return 0;
}
}
/**
* 某一個網址是否已經存在
* DBServer
* @param sql
* 查詢的sql語句
*/
public boolean isAddressExist(String sql) {
try {
ResultSet rs = mStatement.executeQuery(sql);
if (rs.next()) {
return true;
}
rs.close();
} catch (SQLException e) {
e.printStackTrace();
}
return false;
}
public void close() {
try {
if (mConn != null) {
mConn.close();
}
if (mStatement != null) {
mStatement.close();
}
} catch (Exception e) {
e.printStackTrace();
}
}
}3.Java進行遞迴訪問連結
/**
* 遍歷從某一節點開始的所有網路連結
* LinkSpider
* @param startAddress
* 開始的連結節點
*/
private static void ErgodicNetworkLink(String startAddress) {
SpiderQueue queue = getAddressQueue(startAddress);
// System.out.println(queue.toString());
SpiderQueue auxiliaryQueue = null; // 記錄訪問某一個網頁中解析出的網址
while (!queue.isQueueEmpty()) {
WebInfoModel model = queue.poll();
// TODO 判斷資料庫中是否已經存在
if (model == null || DBBLL.isWebInfoModelExist(model)) {
continue;
}
// TODO 如果不存在就繼續訪問
auxiliaryQueue = getAddressQueue(model.getAddres());
System.out.println(auxiliaryQueue);
// TODO 對已訪問的address進行入庫
DBBLL.insert(model);
if (auxiliaryQueue == null) {
continue;
}
while (!auxiliaryQueue.isQueueEmpty()) {
queue.offer(auxiliaryQueue.poll());
}
}
}
/**
* 獲得某一連結下的所有合法連結
* LinkSpider
* @param htmlText
* 網路連結
* @return
*/
private static SpiderQueue getAddressQueue(String htmlText) {
if (htmlText == null) {
return null;
}
SpiderQueue queue = PythonUtils.getAddressQueueByPython(htmlText);
return queue;
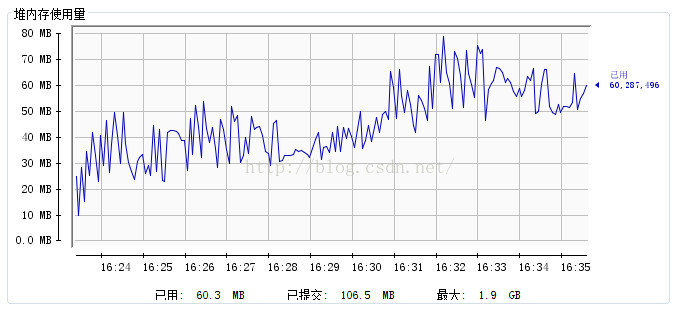
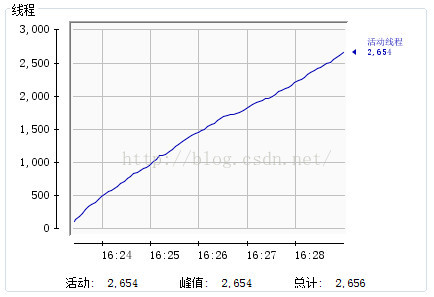
}本程式的記憶體及執行緒情況:
記憶體:
執行緒:
爬取速度:

要點說明:
1.系統中的MySQL及MySQL包
你的Linux中必須要有MySQL,另外,我是通過Java來進行資料庫操作的,所以這裡你的系統中也有要Mysql的Java驅動包。這一點在上面也有說明,不過這裡還是要強調一下。如果你寫過JDBC的程式,那麼這個驅動包,我想你應該是有的,如果你沒寫過,那就去下一個吧。
2.需要一個輔助Queue
在上面的程式碼中,我們可以看到我們有兩個SpiderQueue。一個是我們待訪問的佇列queue,儲存我們將要訪問的連結列表;另一個是輔助佇列auxiliaryQueue,用於獲得從Python解析出來的資料。
3.使用圖的廣度優先搜尋演算法進行連結爬取
這是從連結的相關性上考慮的。如果選擇深度優先,那麼隨著遍歷的深入,可能連結的相關性就會越來越小了。而廣度優先搜尋則不會這樣,因為我們都知道在同一個頁面中的連結總是會因為一些因素要展示在同一個頁面中,那麼它們的相關性就會比較靠譜。
4.單執行緒與多執行緒
完成以上操作,如果你的程式正常執行。在前期是比較快的,可是到了穩定期的時候就一般是1s鍾出一條資料。這個有點慢,我會在下一篇部落格利用多執行緒來解決這個問題。
5.MySQL中新增一個叫cipher_address的欄位
此欄位用於address的加密生成(MD5 or SHA1)。下面舉個例子:

可能你有一個疑問,為什麼要這個欄位?如果你這樣思考了,那麼對於你,是有益的。我們知道其實MySQL對一個很長的字串進行select的時候,是相對來說比較慢的。這時,我們可以把這個address進行雜湊一下,形成一個長度適中,又比較相近的字串,這樣MySQL在比較時會容易一些(當然,你可以不使用這個欄位)。
6.OOM異常
完全按照本文中的程式碼和講解來進行編碼的話,會獲得一個OOM的異常(我的程式是跑了1天半的時時間)。如下:
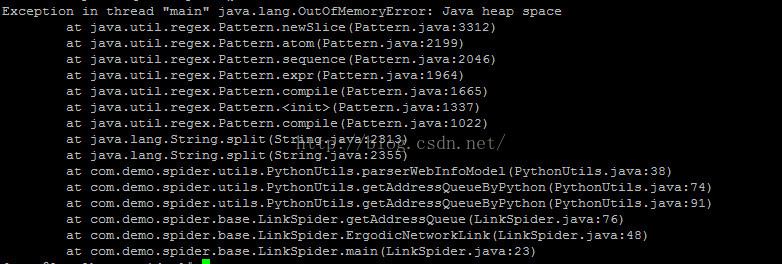
數量大概在23145條左右

對於這一點在上面關於記憶體和執行緒的展示圖中可以看到原因。