
網路爬蟲—作者:王曉坤
網路爬蟲作業
一、題目
羊車門作業已釋出,很快就會有同學提交作業,在此作業基礎上,我們釋出本網路爬蟲作業。
本作業共分兩部分,第一部分必做,第二部分選作。
第一部分:
請分析作業頁面,爬取已提交作業資訊,並生成已提交作業名單,儲存為英文逗號分隔的csv檔案。檔名為:hwlist.csv 。
檔案內容範例如下形式:
學號,姓名,作業標題,作業提交時間,作業URL
20194010101,張三,羊車門作業,2018-11-13 23:47:36.8,http://www.cnblogs.com/sninius/p/12345678.html
20194010102,李四,羊車門,2018-11-14 9:38:27.03,
*注1:如製作定期爬去作業爬蟲,請注意爬取頻次不易太過密集;
*注2:本部分作業用到部分庫如下所示:
(1)requests —— 第3方庫
(2)json —— 內建庫
第二部分:
在生成的 hwlist.csv 檔案的同文件夾下,建立一個名為 hwFolder 資料夾,為每一個已提交作業的同學,新建一個以該生學號命名的資料夾,將其作業網頁爬去下來,並將該網頁檔案存以學生學號為名,“.html”為副檔名放在該生學號資料夾中。
二、原始碼
import requests import json import os import shutil import datetime import time #———————————————————————————————————————————————————————————————————————————————————————————————————————————————————— def GetUrl(url): '''爬取網頁內容函式.引數:網址''' try: r = requests.get(url) #獲取網頁內容 r.raise_for_status() #返回異常,r.status_code是200,返回 None r.encoding = r.apparent_encoding # 轉化編碼, 根據r.apparent_encoding的結果轉碼 print('網頁內容讀取成功!') return r #返回網頁內容 except: print("產生異常") #———————————————————————————————————————————————————————————————————————————————————————————————————————————————————— def CreatFolder(FolderName): ''' 建立資料夾函式,引數資料夾的名稱(字串)''' exist=os.path.exists(FolderName) #判斷是否存在,存在返回真,否則返回假。 if not exist: os.mkdir(FolderName) print('{}資料夾建立成功!'.format(FolderName)) else: shutil.rmtree(FolderName) CreatFolder(FolderName) print('{}資料夾已存在,將其刪除後重建!\n'.format(FolderName)) #————————————————————————————————————————————————————————————————————————————————————————————————————————————————— def HW(url): r0=GetUrl(url) #呼叫函式爬取網頁 data0=json.loads(r0.text) #將json格式資料轉換為字典 #建立hwlist.csv with open ('hwlist.csv','w')as f: zero=('學號',',','姓名',',','作業標題',',','作業提交時間',',','作業URL','\n') #寫入第一行內容 f.writelines(zero) for i in data0['data']: xuehao=str(i['StudentNo'])+"\t" #在時間和日期後加上“\t”,轉換為格式 date=i['DateAdded'].replace('T',' ')+"\t" #用EXCEL開啟的時候,不會出現錯誤的形式 one=(xuehao,',',i['RealName'],',',i['Title'],',',date,',',i['Url'],'\n') f.writelines(one) #建立hwFolder資料夾 FolderName='hwFolder' CreatFolder(FolderName) os.chdir(FolderName) #進入hwFolder資料夾 #建立學生的資料夾和檔案 for i in data0['data']: name=str(i['StudentNo']) #得到學號 CreatFolder(name) #建立以學號命名的資料夾 os.chdir(name) #進入以學號命名的資料夾 with open (name+'.html','wb') as fp: #覆蓋寫模式和二進位制檔案模式,對以學號命名.html檔案 進行操作(必須以二進位制檔案模式) Url=i['Url'] r1=GetUrl(Url) #獲取該學號同學羊車門作業的網頁 fp.write(r1.content) #r1.content獲取網頁的內容,並寫入以該同學學號命名.html檔案中 #a=type(r1.content) #print(a) print("{}.html檔案內容建立成功。\n".format(name)) os.chdir('..') #返回上一層目錄,即hwFolder資料夾 #———————————————————————————————————————————————————————————————————————————————————————————————————————————————————— #定時爬取網頁內容 #if __name__=='__main__': flag=0 #設定一個值 now=datetime.datetime.now() print(now) sched_timer=datetime.datetime(now.year, now.month, now.day, now.hour, now.minute, now.second) + datetime.timedelta(seconds=5) print(sched_timer) while (True): url="https://edu.cnblogs.com/Homework/GetAnswers?homeworkId=2420&_=1543326450118" now=datetime.datetime.now() if sched_timer<now<sched_timer+datetime.timedelta(seconds=5): time.sleep(1) HW(url) #執行函式 flag=1 else: if flag==1: sched_timer=sched_timer+datetime.timedelta(minutes=2) #2分鐘後執行 flag=0 print("程式執行完成!!")
三、結果
第一次讀取檔案
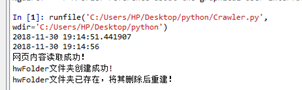
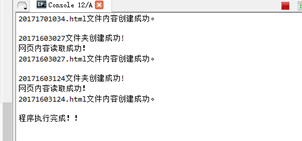
第二次讀取檔案
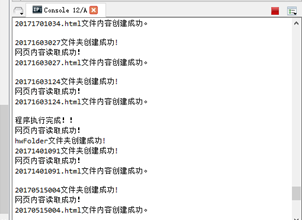
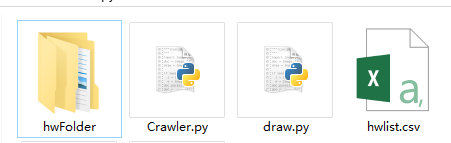
建立hwlist.csv檔案,hwFloder資料夾
hwlist.csv檔案內容

hwFloder資料夾
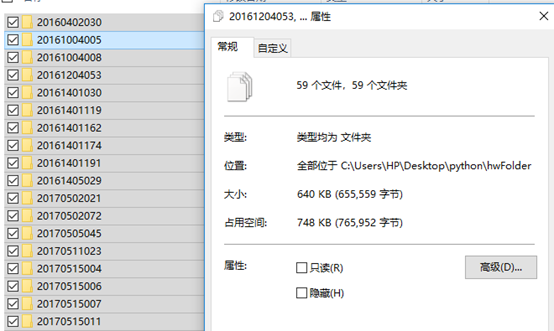
hwFloder資料夾,子資料夾中檔案及內容

四、思考與總結
1.字尾為.csv的檔案
最終的結果儲存在一個.csv檔案下。.csv檔案預設以EXCLE開啟,
但是,開啟後結果顯示,學號列沒有完全顯示,時間列沒有顯示年/月/日。

解決方法:
在學號和日期後面連線一個”\t”,(必須是雙引號),可以將學號和日期顯示出來。
更改後結果:
Excel中

記事本

拓展:
1.為什麼選用字尾為.csv的檔案?
(1)寫csv檔案的效率很高。2. csv檔案的大小遠遠小於生成的Excel檔案。並且隨著Excel檔案的變大儲存效率會降低的。
(參見網頁:http://www.blogjava.net/hongqiang/archive/2012/07/10/382668.html)
(2)有一個csv的模組
推薦網頁(https://www.cnblogs.com/pyxiaomangshe/p/8026483.html)
2.用到一個shutil模組,shutil模組和os模組是對檔案,資料夾操作的。
os.remove ——刪除檔案
os.mkdir ——刪除空的資料夾
shutil. rmtree ——遞迴刪除非空資料夾,
網址:https://blog.csdn.net/huilaojia123/article/details/53939845
https://www.aliyun.com/jiaocheng/480630.html
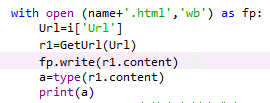
3.with open (name+'.html','wb') as fp:
注:只能用”wb”寫,b:二進位制檔案模式.因為r1.content,他的型別是<class 'bytes'>

4.Requests庫
爬取網頁內容可以自定義一個函式,增加判斷條件,增強程式碼健壯性!

https://www.cnblogs.com/hanbb/p/7221659.html?utm_source=itdadao&utm_medium=referral
4. if __name__ == '__main__' 的解釋
https://blog.csdn.net/yjk13703623757/article/details/77918633/
5.定時爬取網頁內容參考的網頁
https://blog.csdn.net/qq807237096/article/details/78794039
6. datetime模組
https://blog.csdn.net/cmzsteven/article/details/64906245
https://www.cnblogs.com/wenBlog/p/6023742.html