
EM演算法逼近GMM引數針對二維資料點的python實現
阿新 • • 發佈:2019-02-07
GMM即高斯混合模型,是將資料集看成是由多個高斯分佈線性組合而成,即資料滿足多個高斯分佈。EM演算法用來以迭代的方式尋找GMM中個高斯分佈的引數以及權值。GMM可以用來做k分類,而混合的高斯分佈個數也就是分類數K。
當資料Y都是一維的時候,我們假設由兩個高斯分佈組成
就有概率密度函式
PI和1-PI作為各自分佈的權值
這樣EM的實現步驟就很簡單了

一維情況下實際上那些引數都是一些數
當資料點為多維的向量時,就要做一些調整,原本的均值變為均值向量,方程要變成協方差矩陣。
E步:
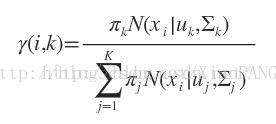
M步:
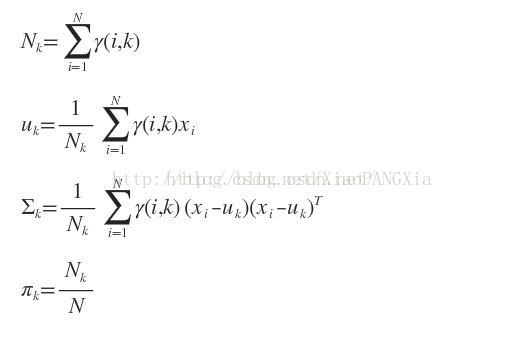
下面針對二維資料集做了Python實現
# -*- coding: UTF-8 -*- import matplotlib.pyplot as plt import numpy as np from scipy import stats import math import sys import random reload(sys) sys.setdefaultencoding('utf-8') parameter_dict = {} parameter_dict["Mu_1"] = np.array([0, 0]) parameter_dict["Sigma_1"] = np.array([[1, 0], [0, 1]]) parameter_dict["Mu_2"] = np.array([0, 0]) parameter_dict["Sigma_2"] = np.array([[1, 0], [0, 1]]) parameter_dict["Pi_weight"] = 0.5 parameter_dict["gama_list"] = [] def set_parameter(mu_1, sigma_1, mu_2, sigma_2, pi_weight): parameter_dict["Mu_1"] = mu_1 parameter_dict["Mu_1"].shape = (2, 1) parameter_dict["Sigma_1"] = sigma_1 parameter_dict["Mu_2"] = mu_2 parameter_dict["Mu_2"].shape = (2, 1) parameter_dict["Sigma_2"] = sigma_2 parameter_dict["Pi_weight"] = pi_weight def PDF(data, Mu, sigma): """ 二元正態分佈概率密度函式 :param data: 一個二維資料點,ndarray :param Mu: 均值,ndarray :param Sigama: 協方差陣ndarray :return:該資料點的概率密度值 """ sigma_sqrt = math.sqrt(np.linalg.det(sigma)) # 協方差矩陣絕對值的1/2次 sigma_inv = np.linalg.inv(sigma) # 協方差矩陣的逆 data.shape = (2, 1) Mu.shape = (2, 1) minus_mu = data - Mu minus_mu_trans = np.transpose(minus_mu) res = (1.0 / (2.0 * math.pi * sigma_sqrt)) * math.exp( (-0.5) * (np.dot(np.dot(minus_mu_trans, sigma_inv), minus_mu))) return res def E_step(Data): """ E-step: compute responsibilities 計算出本輪gama_list :param Data:一系列二維的資料點 :return:gama_list """ # 協方差矩陣 sigma_1 = parameter_dict["Sigma_1"] sigma_2 = parameter_dict["Sigma_2"] pw = parameter_dict["Pi_weight"] mu_1 = parameter_dict["Mu_1"] mu_2 = parameter_dict["Mu_2"] parameter_dict["gama_list"] = [] for point in Data: gama_i = (pw * PDF(point, mu_2, sigma_2)) / ( (1.0 - pw) * PDF(point, mu_1, sigma_1) + pw * PDF(point, mu_2, sigma_2)) parameter_dict["gama_list"].append(gama_i) def M_step(Data): """ M-step: compute weighted means and variances 更新均值與協方差矩陣 在此例中, gama_i對應Mu_2,Var_2 (1-gama_i)對應Mu_1,Var_1 :param X:一系列二維的資料點 :return: """ N_1 = 0 N_2 = 0 for i in range(len(parameter_dict["gama_list"])): N_1 += 1.0 - parameter_dict["gama_list"][i] N_2 += parameter_dict["gama_list"][i] # 更新均值 new_mu_1 = np.array([0, 0]) new_mu_2 = np.array([0, 0]) for i in range(len(parameter_dict["gama_list"])): new_mu_1 = new_mu_1 + Data[i] * (1 - parameter_dict["gama_list"][i]) / N_1 new_mu_2 = new_mu_2 + Data[i] * parameter_dict["gama_list"][i] / N_2 # 很重要,numpy對一維向量無法轉置,必須指定shape new_mu_1.shape = (2, 1) new_mu_2.shape = (2, 1) new_sigma_1 = np.array([[0, 0], [0, 0]]) new_sigma_2 = np.array([[0, 0], [0, 0]]) for i in range(len(parameter_dict["gama_list"])): data_tmp = [0, 0] data_tmp[0] = Data[i][0] data_tmp[1] = Data[i][1] vec_tmp = np.array(data_tmp) vec_tmp.shape = (2, 1) new_sigma_1 = new_sigma_1 + np.dot((vec_tmp - new_mu_1), (vec_tmp - new_mu_1).transpose()) * (1.0 - parameter_dict["gama_list"][i]) / N_1 new_sigma_2 = new_sigma_2 + np.dot((vec_tmp - new_mu_2), (vec_tmp - new_mu_2).transpose()) * parameter_dict["gama_list"][i] / N_2 # print np.dot((vec_tmp-new_mu_1), (vec_tmp-new_mu_1).transpose()) new_pi = N_2 / len(parameter_dict["gama_list"]) # 更新類變數 parameter_dict["Mu_1"] = new_mu_1 parameter_dict["Mu_2"] = new_mu_2 parameter_dict["Sigma_1"] = new_sigma_1 parameter_dict["Sigma_2"] = new_sigma_2 parameter_dict["Pi_weight"] = new_pi def EM_iterate(iter_time, Data, mu_1, sigma_1, mu_2, sigma_2, pi_weight, esp=0.0001): """ EM演算法迭代執行 :param iter_time: 迭代次數,若為None則迭代至約束esp為止 :param Data:資料 :param esp:終止約束 :return: """ set_parameter(mu_1, sigma_1, mu_2, sigma_2, pi_weight) if iter_time == None: while (True): old_mu_1 = parameter_dict["Mu_1"].copy() old_mu_2 = parameter_dict["Mu_2"].copy() E_step(Data) M_step(Data) delta_1 = parameter_dict["Mu_1"] - old_mu_1 delta_2 = parameter_dict["Mu_2"] - old_mu_2 if math.fabs(delta_1[0]) < esp and math.fabs(delta_1[1]) < esp and math.fabs( delta_2[0]) < esp and math.fabs(delta_2[1]) < esp: break else: for i in range(iter_time): pass def EM_iterate_trajectories(iter_time, Data, mu_1, sigma_1, mu_2, sigma_2, pi_weight, esp=0.0001): """ EM演算法迭代執行,同時畫出兩個均值變化的軌跡 :param iter_time:迭代次數,若為None則迭代至約束esp為止 :param Data: 資料 :param esp: 終止約束 :return: """ mean_trace_1 = [[], []] mean_trace_2 = [[], []] set_parameter(mu_1, sigma_1, mu_2, sigma_2, pi_weight) if iter_time == None: while (True): old_mu_1 = parameter_dict["Mu_1"].copy() old_mu_2 = parameter_dict["Mu_2"].copy() E_step(Data) M_step(Data) delta_1 = parameter_dict["Mu_1"] - old_mu_1 delta_2 = parameter_dict["Mu_2"] - old_mu_2 mean_trace_1[0].append(parameter_dict["Mu_1"][0][0]) mean_trace_1[1].append(parameter_dict["Mu_1"][1][0]) mean_trace_2[0].append(parameter_dict["Mu_2"][0][0]) mean_trace_2[1].append(parameter_dict["Mu_2"][1][0]) if math.fabs(delta_1[0]) < esp and math.fabs(delta_1[1]) < esp and math.fabs( delta_2[0]) < esp and math.fabs(delta_2[1]) < esp: break else: for i in range(iter_time): pass plt.subplot(121) plt.xlim(xmax=5, xmin=2) plt.ylim(ymax=90, ymin=60) plt.xlabel("eruptions") plt.ylabel("waiting") plt.plot(mean_trace_1[0], mean_trace_1[1], 'r-') plt.plot(mean_trace_1[0], mean_trace_1[1], 'b^') plt.subplot(122) plt.xlim(xmax=4, xmin=0) plt.ylim(ymax=60, ymin=40) plt.xlabel("eruptions") plt.ylabel("waiting") plt.plot(mean_trace_2[0], mean_trace_2[1], 'r-') plt.plot(mean_trace_2[0], mean_trace_2[1], 'bo') plt.show() def EM_iterate_times(Data, mu_1, sigma_1, mu_2, sigma_2, pi_weight, esp=0.0001): # 返回迭代次數 set_parameter(mu_1, sigma_1, mu_2, sigma_2, pi_weight) iter_times = 0 while (True): iter_times += 1 old_mu_1 = parameter_dict["Mu_1"].copy() old_mu_2 = parameter_dict["Mu_2"].copy() E_step(Data) M_step(Data) delta_1 = parameter_dict["Mu_1"] - old_mu_1 delta_2 = parameter_dict["Mu_2"] - old_mu_2 if math.fabs(delta_1[0]) < esp and math.fabs(delta_1[1]) < esp and math.fabs( delta_2[0]) < esp and math.fabs(delta_2[1]) < esp: break return iter_times def task_1(): # 讀取資料,猜初始值,執行演算法 Data_list = [] with open("old_faithful_geyser_data.txt", 'r') as in_file: for line in in_file.readlines(): point = [] point.append(float(line.split()[1])) point.append(float(line.split()[2])) Data_list.append(point) Data = np.array(Data_list) Mu_1 = np.array([3, 60]) Sigma_1 = np.array([[10, 0], [0, 10]]) Mu_2 = np.array([1, 30]) Sigma_2 = np.array([[10, 0], [0, 10]]) Pi_weight = 0.5 EM_iterate_trajectories(None, Data, Mu_1, Sigma_1, Mu_2, Sigma_2, Pi_weight) def task_2(): """ 執行50次,看迭代次數的分佈情況 這裡協方差矩陣都取[[10, 0], [0, 10]] mean值在一定範圍內隨機生成50組數 :return: """ # 讀取資料,猜初始值,執行演算法 Data_list = [] with open("old_faithful_geyser_data.txt", 'r') as in_file: for line in in_file.readlines(): point = [] point.append(float(line.split()[1])) point.append(float(line.split()[2])) Data_list.append(point) Data = np.array(Data_list) try: # 在10以內猜x1,在100以內隨機取x2 x_11 = 5 x_12 = 54 x_21 = 2 x_22 = 74 Mu_1 = np.array([x_11, x_12]) Sigma_1 = np.array([[10, 0], [0, 10]]) Mu_2 = np.array([x_21, x_22]) Sigma_2 = np.array([[10, 0], [0, 10]]) Pi_weight = 0.5 iter_times = EM_iterate_times(Data, Mu_1, Sigma_1, Mu_2, Sigma_2, Pi_weight) print iter_times except Exception, e: print e # task_1() task_2()