
深度學習在自然語言處理中的應用: 集智俱樂部活動筆記
自然語言處理(Natural Language Processing, NLP)是人工智慧中的一個重要分支,從人工智慧這個領域剛發展起來的時候就一直是一個重要的研究方向,到現在也發展出了很多的細分領域和非常多的方法,大致上來說,我們可以認為是在 2013 年的時候,伴隨著 word2vec 這個 word embedding 的開源工具的出現,正式地將深度學習引進了 NLP
的研究中 —— 當然要認真考據的話,word embedding 的思想早在上世紀 80 年代的時候就已經初露端倪1,用神經網路來建模語言的工作也可以追溯到現為
IDL 科學家的徐偉在 2001 年的工作2以及 2003 年 Bengio 在 JMLR 上發表的著名論文《A Neural Probabilistic
Language Model》,大家去了解 word2vec/word embedding 的時候經常會見到的一張經典的模型圖(見圖
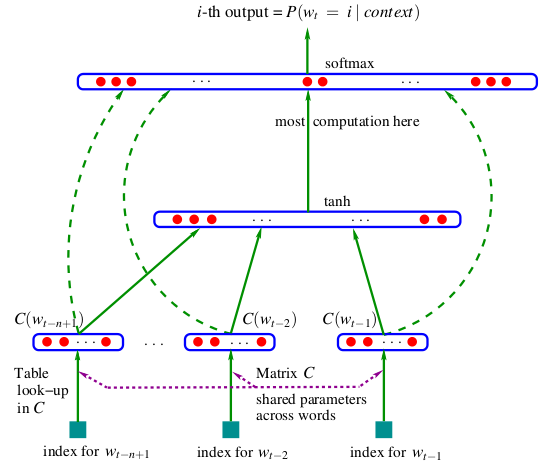
圖1 Bengio 的 NPLM
從不那麼嚴格的大眾的角度來看,可以說 word2vec 的出現是深度學習進入 NLP 領域的一個標誌性事件,其中的 word embedding 思想帶來了更好的文字的表示方法,也催生了各種在更高層級做 embedding 的工作,比如 sentence embedding,比如知識圖譜中實體和關係的 embedding(TransE/TransR等);而 sequence to sequence 思想的提出以及 attention 機制的出現,則在機器翻譯(Machine Translation, MT)領域產生了重要的作用。當然除此以外,CNN 和 GAN 乃至強化學習等最開始並不是用於 NLP 的方法,也被引入到 NLP 領域當中,並且取得了不錯的結果。
總得來說,深度學習給 NLP 研究帶來的新方法可以列舉如下:
- 以 embedding 為代表的表示學習
- sequence to sequence 模型/encoder-decoder 框架
- 注意力機制(Attention Mechanism)
- 記憶網路(Memory Network)
在 embedding 思想出現前,在各種 NLP 處理中都是用一個離散的值來表示每個詞的,這種表示方法稱為 one-hot 表示,是一種難以擴充套件、難以表達語義的方法。embedding 將一個詞表示為多維空間中的一個連續實數向量,能在一定程度上反映語義乃至上下位關係。word embedding 的價值不在於它能得出的「男人 - 女人 = 國王 - 王后」這種類比關係,而在於它作為 NLP 中基本處理單元的一個基礎表示,可以用來構建更高層級文字單元(句子、段落、篇章)的表示(見圖

圖2 句子的 embedding 表示
這種思想還能拓展到其他領域如知識圖譜(見圖3)、複雜系統中。
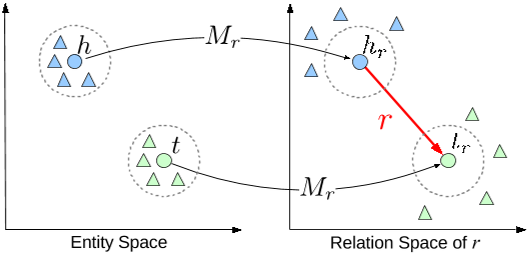
圖3 知識圖譜中的 TransR 模型
當然 word embedding 稱不上完美,它還做不到完美地表達語義,但不用對這些問題太過刻薄糾結。我非常同意呂正東老師以及很多 NLP 學者的觀點: word embedding 的效果在語言學層面還有尚待改進的地步,在留意這些問題的同時,還應該積極地去使用它去推動更復雜的 NLP 的研究和應用。
sequence to sequence 或說 encoder-decoder 框架最初是在機器翻譯中提出來的,以機器翻譯為例,其基本思想是:
- 將輸入的句子經過一個 RNN 生成一個能反映句子語義的向量,類似計算 sentence embedding 的過程,
- 用另一個 RNN ,從輸入句子的向量表達中解碼出另一個句子
第一個過程稱之為 encoding,第二個過程稱之為 decoding,整個模型非常的簡單優雅,不需要詞對齊,不需要額外的語言模型,輸入英語,直接得到法語,這樣便成了一個端到端(end-to-end)的模型,如圖4所示。
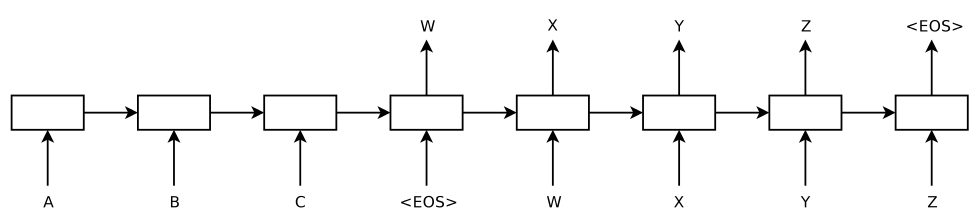
圖4 sequence to sequence 框架
之所以稱其為「框架」而不是模型,在於它提出了一種通用的、可擴充套件的模型設計方式,其中的 encoder 和 decoder 都可以換成其他型別的神經網路結構,從而被廣泛應用到不同的領域中,比如語音識別、OCR、自動駕駛、機器翻譯、對話、image caption……而在 encoder-decoder 的基礎上,為了改進機器翻譯系統,attention 機制又被提了出來。
attention 是一種在根據模型內部狀態動態聚焦於輸入或輸出不同部分的一種機制,比如說做機器翻譯時在不同時刻關注源語言文字中不同的詞,如圖5所示。
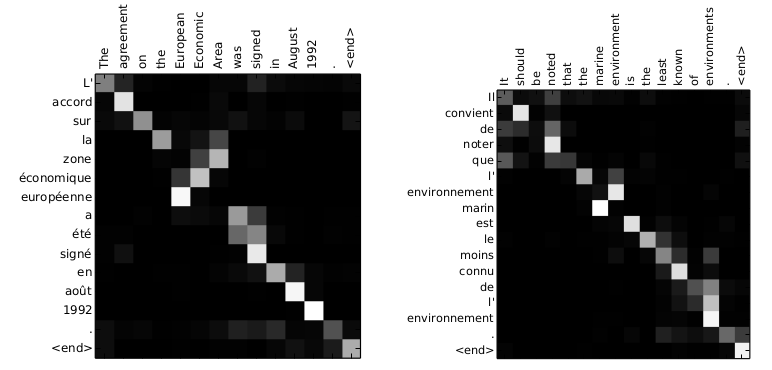
圖5 神經機器翻譯中的 attention 矩陣
在 image caption 任務中,要為一張圖片生成描述性文字,在這裡,attention 會根據當前要生成的詞去聚焦於圖片的不同區域,見圖6。

圖6 Image Caption 中的 attention
memory network 則是一種附帶額外儲存結構的神經網路模型,通過這個額外的儲存結構來記憶更豐富的資訊,使得模型具有更強的表達能力和學習能力。在這之中,對這個儲存結構中資訊的訪問,使用的就是 attention 機制;相應的,在機器翻譯和 image caption 這些任務中使用 encoder-decoder 模型時,也可以把 encoder 產生的輸入的表達當作是 memory,attention 機制是在這個 memory 上挑選合適的內容。總之,在相關的場景中,我們可以認為 memory 是一個可以容納有用資訊的資料結構,而 attention 則是操作這個資料結構的一種方式,這也是這次活動中最主要討論的內容。
從應用上來說,深度學習給以下 NLP 任務帶來了比較大的推動作用:
- 機器翻譯
- 對話系統(Dialogue/Chatbot/Question Answering)
- 自動推理
當然,這其中最受關注的就是機器翻譯和對話系統了,畢竟語言的最終目的是用於進行交流,機器翻譯能夠讓原來語言不同的兩個人能夠互相交流,而對話系統則能讓人和機器以人類熟悉的方式進行交流,備受關注都是理所當然的。機器翻譯在 NLP 領域中一直都是比較重要的一個方向,從應用意義上來說是一件能極大提高人類交流效率的事情,從學術意義上來說是一個數據相對充足且定義相對良好的研究問題,在神經機器翻譯(Neural Machine Translation, NMT)突破前,就已經有基於統計學方法的統計機器翻譯(Statistical Machine Translation, SMT)並且得到廣泛應用。隨著 encoder-decoder 框架和 attention 機制的提出,NMT 已經大幅超越了傳統 SMT,並且在翻譯問題上對 attention 機制的改進仍然在繼續。
談到 NMT,當然離不開 Google 的翻譯系統,圖7就是 Google 神經機器翻譯系統(Google Neural Machine Translation, GNMT) 的模型結構,看起來有點複雜,其實就是 encoder-decoder 結構:左側框圖是 encoder 部分,右側框圖是 decoder 部分,它們之間靠 attention 機制聯絡起來。
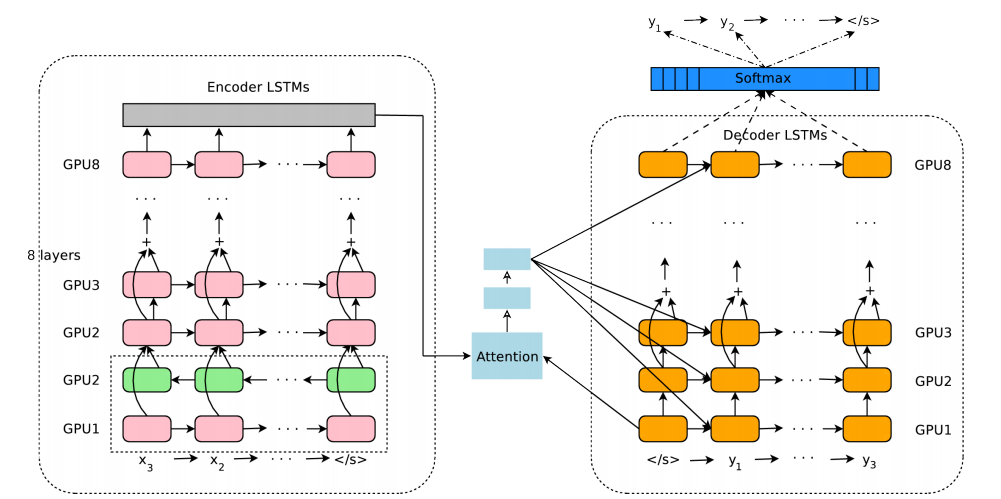
圖7 GNMT 模型結構
Google 在 NMT 方面的翻譯效果,一方面固然來源於新的方法,另一方面也在於 Google 龐大的資料積累和強大的工程能力。資料是深度學習中很重要的成分,我在 Quora 上看到有人用「without data, it's nothing」來評論 NLP 的 Python 工具包 NLTK,在深度學習這塊,我覺得也可以這樣講 —— 當然這麼講是強調資料的重要性,並不是說深度學習就不重要了,「巧婦難為無米之炊 」,要做好一桌可口的飯菜,原材料、烹飪工具和廚藝是缺一不可的。
在對話方面,我們現在已經可以很簡單地使用基於 encoder-decoder 的模型來得到一個用於對話的生成模型,在處理單輪對話和某些特定領域的多輪對話上取得不錯的結果。最簡單的辦法,是將 encoder-decoder 框架用到對話領域,仿照機器翻譯的方法,將對話看作是一個翻譯問題,根據使用者的話語來生成對應的迴應。區別於傳統的基於檢索和基於規則、模板的方法,生成模型可以完全是資料驅動的, 在有足夠豐富資料的情況下 ,可以幾乎不需要人工介入學習過程內部。圖8是一個例子。
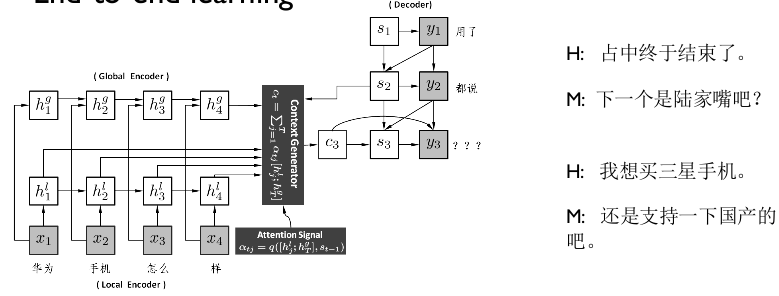
圖8 Neural Responding Machine
但我們能看出來,對話和翻譯本質上是兩個不同的事情,翻譯是在兩個不同語言但具有相同語義的文字之間做轉換,對話則不是這樣的,它是一個持續的過程,我們會希望它能記憶上下文、能識別實體、能辨別細微的感情等等等等。再加上在對話這個領域,資料的積累還不夠,健全的評價標準還有待建立和完善。按照呂老師的看法,對話是比翻譯複雜一到兩個量級的任務,在真正得到突破前,可能還需要一定時間去提高我們對對話這個任務的認識。基本上來說,這兩年在對話任務上所做的工作,也經常使用 encoder-decoder 框架,attention 機制基本也是標配,在多輪對話需要處理上下文時則還會使用如 memory network 之類帶額外儲存結構的模型來記憶上下文。除此以外,學術界還嘗試了很多其他方法來用在對話任務上,比如整合知識圖譜來提供精確的回答,比如應用強化學習來讓優化對話結果3(見圖9)。
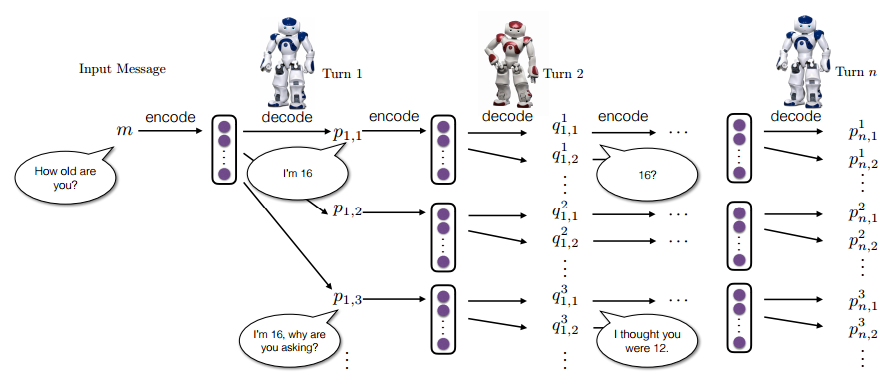
圖9 強化學習在對話中的應用
在另外一個應用「自動推理」上,按我的看法,可以分為兩部分。我們談推理的時候,可以是在談形式邏輯的推理,也可以是自然語言層面的事實、因果、關係的推理,形式邏輯的推理可以用來做定理證明、類比歸納等各種事情,也是人工智慧中的一個重要研究領域,這一塊的定義是比較明確的;而自然語言推理則很難給出一個公認的定義,對此呂老師的觀點是,如果我們在處理一個 NLP 任務時,需要對輸入進行多遍處理,那麼這個 NLP 任務就可以被認為是一個自然語言推理的任務。比如說 Facebook AI Research(FAIR) 用 memory network 在 bAbI 資料集(見圖10)做的問答4,就可以認為是一個推理過程。

圖10 FAIR 的 bAbI 資料集
bAbI 資料集是 FAIR 設計的用來考察對話系統個方面能力的一個數據集,包含了十幾種從易到難的推理任務,此後有不少做對話或者推理的工作都通過這個資料集來評判模型的表達能力,比如 15 年 8 月香港中文大學 Baolin Peng 的 Neural Reasoner5,圖11是 Neural Reasoner 的模型結構,很顯然也可以看作是一個 encoder-decoder 的模型。
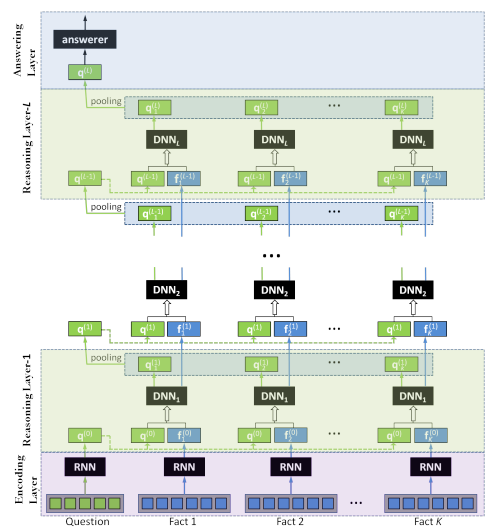
圖11 Neural Reasoner
不管是形式邏輯的推理,還是自然語言推理,它都是在一定的知識基礎上去做推理的,特別是自然語言推理,對於何謂知識何謂推理,都得是在一個具體的場景下才能界定清楚。據呂老師講,他創立的「深度好奇」就是嘗試將自然語言推理的技術應用到法律領域上,比如去做法律條文的理解和推斷,想一想還是蠻酷的。