《機器學習實戰》第七章學習筆記(AdaBoost)
一、整合學習
整合學習(ensemble learning)通過構建並結合多個學習器來完成學習任務,有時也被稱為多分類器系統(multi-classifier system)、基於委員會的學習(committee-based learning)等。
整合學習將多個學習器進行結合,常可獲得比單一學習器顯著優越的泛化效能。這對“弱學習器”(weak learner)尤為明顯,因此,整合學習的很多理論研究都是針對弱學習器進行的,而基學習器有時也被直接稱為弱學習器。
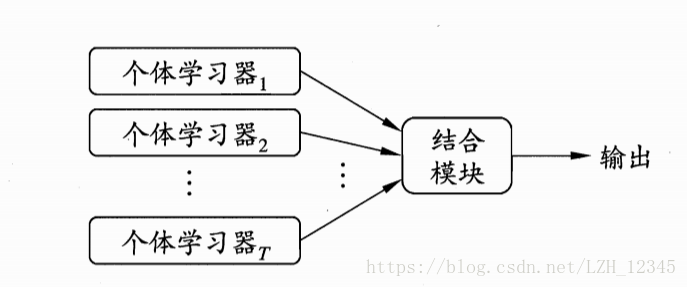
整合學習的一般結構:先產生一組“個體學習器”,再用某種策略將它們結合起來。個體學習器通常由一個現有的學習演算法從訓練資料產生。整合可以只包含同種型別的個體學習器(同質整合中,個體學習器又稱基學習器),稱為同質整合;也可以包含不同型別的個體學習器(異質整合中,個體學習器又稱元件學習器),稱為異質整合。
想要獲得好的整合,對個體學習器有兩個要求:
- 準確性,個體學習器至少不差於弱學習器;
- 多樣性,個體學習器之間要有差異。
整合學習方法有兩大類:
- 個體學習器間存在強依賴關係、必須序列生成序列化方法,例如:Boosting
- 個體學習器間不存在強依賴關係、可同時生成的並行化方法,例如:Bagging和“隨機森林”(Random Forest)
二、Bagging:基於資料隨機重抽樣的分類器構建方法
自舉匯聚法(bootstrap aggregating),也稱為bagging方法,是在從原始資料集選擇S次後得到S個新資料集的一種技術。新資料集和原資料集的大小相等。每個資料集都是通過在原始資料集中隨機選擇一個樣本來進行替換而得到的。這裡的替換就意味著可以多次地選擇同一樣本。這一性質就允許新資料集中可以有重複的值,而原始資料集的某些值在新集合中則不再出現。
在S個數據集建好之後, 將某個學習演算法分別作用於每個資料集就得到了S個分類器。當我們要對新資料進行分類時,就可以應用這S個分類器進行分類。與此同時,選擇分類器投票結果中最多的類別作為最後的分類結果。
隨機森林(random forest)是一種更先進的bagging方法。


三、Boosting

3.1 AdaBoost演算法

3.2 程式碼實現
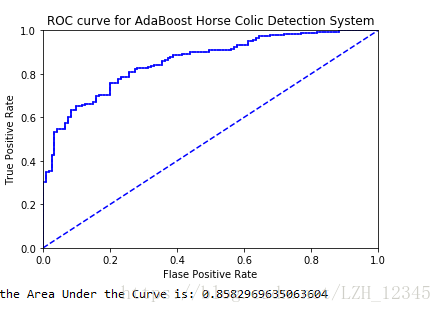
# -*- coding: utf-8 -*- """ Created on Thu Apr 26 19:01:54 2018 利用AdaBoost演算法從疝氣病症預測病馬死亡率 @author: lizihua """ from numpy import matrix,ones,shape,mat,zeros,log,multiply,exp,sign import matplotlib.pyplot as plt import numpy as np #載入簡單資料 def loadSimpData(): datMat = matrix([[1,2.1],[2,1.1],[1.3,1],[1,1],[2,1]]) classLabels = [1,1,-1,-1,1] return datMat, classLabels #自適應載入資料 def loadDataSet(fileName): numFeat = len(open(fileName).readline().split('\t')) dataMat = [];labelMat = [] fr = open(fileName) for line in fr.readlines(): lineArr = [] curLine = line.strip().split('\t') for i in range(numFeat-1): lineArr.append(float(curLine[i])) dataMat.append(lineArr) labelMat.append(float(curLine[-1])) return dataMat,labelMat #單層決策樹生成函式 #dataMatrix:訓練陣列;dimen列索引;threshVal:閾值;threshIneq:比較符號 def stumpClassify(dataMatrix,dimen,threshVal,threshIneq): #初始化返回陣列,全部設定為1 retArray = ones((shape(dataMatrix)[0],1)) #比較符號是小於(less than)時: if threshIneq == 'lt': #將訓練陣列中某列值小於等於閾值的對應索引對應的返回陣列的元素設定為-1 retArray[dataMatrix[:,dimen] <= threshVal] = -1.0 #否則,比較符號是大於gt(great than)時: else: retArray[dataMatrix[:,dimen] > threshVal] = -1.0 return retArray #遍歷stumpClassify()函式所有可能輸入值,並找到資料集上最佳的單層決策樹 def bulidStump(dataArr,classLabels,D): dataMatrix = mat(dataArr) labelMat = mat(classLabels).T m,n = shape(dataMatrix) #numSteps:步數;bestStump儲存最佳單層決策樹的相關資訊;bestClasEst:最佳預測結果 numSteps = 10.0;bestStump = {};bestClasEst = mat(zeros((m,1))) #minError取無窮大 minError = np.inf #遍歷所有特徵 for i in range(n): rangeMin = dataMatrix[:,i].min() rangeMax = dataMatrix[:,i].max() stepSize = (rangeMax-rangeMin)/numSteps #遍歷所有步長,步長即閾值,閾值設定為整個取值範圍之外也是可以的 for j in range(-1,int(numSteps)+1): #在大於和小於之間切換 for inequal in ['lt','gt']: threshVal = (rangeMin + float(j)*stepSize) predictedVals = stumpClassify(dataMatrix,i,threshVal,inequal) errArr = mat(ones((m,1))) errArr[predictedVals == labelMat] = 0 #計算加權錯誤率 weightError = D.T*errArr #print("split:dim %d,thresh %.2f,thresh inequal: %s,the weighted error is %.3f"%(i,threshVal,inequal,weightError)) #找到最小錯誤率的最佳單層決策樹,並儲存相關資訊 if weightError < minError: minError = weightError bestClasEst = predictedVals.copy() bestStump['dim'] = i bestStump['thresh'] = threshVal bestStump['ineq'] = inequal return bestStump,minError,bestClasEst #基於單層決策樹(DS,decision stump)的AdaBoost訓練過程 #輸入引數:資料集、類別標籤、迭代次數(預設為40) def adaBoostTrainDS(dataArr,classLabels,numIt=40): weakClassArr = [] m = shape(dataArr)[0] D = mat(ones((m,1))/m) aggClassEst = mat(zeros((m,1))) for i in range(numIt): bestStump,error,classEst = bulidStump(dataArr,classLabels,D) print("D:",D.T) #alpha公式:alpha=1/2*ln((1-error)/error) #max(error,1e-16)是為了確保在沒有錯誤時不會發生溢位 alpha = float(0.5*log((1.0-error)/max(error,1e-16))) bestStump['alpha'] = alpha weakClassArr.append(bestStump) print("classEst:",classEst.T) #更新D,D是一個概率分佈向量,因此,其所有元素之和為1 #D=(D*exp(-alpha*classLabels*classEst))/D.sum() #其中,classLabels是實際樣本標籤,classEst是分類器分類後得到的預測分類結果 #multiply是點積,其中,該例中,classLabels:1*m;classEst:m*1 expon = multiply(-1*alpha*mat(classLabels).T,classEst) D = multiply(D,exp(expon)) D = D/D.sum() #更新累計類別估計值 #aggClassEst記錄每個資料點的類別估計累計值 #最終分類函式H(x)=sign(aggClassEst),而aggClassEst += alpha*classEst aggClassEst += alpha*classEst print("aggClassEst:",aggClassEst.T) #計算錯誤率 aggErrors = multiply(sign(aggClassEst) != mat(classLabels).T,ones((m,1))) errorRate = aggErrors.sum()/m print("total error:",errorRate,"\n") #當總錯誤率為0時,直接終止迴圈 if errorRate == 0.0: break return weakClassArr,aggClassEst #AdaBoost分類函式 def adaClassify(datToClass,classifierArr): dataMatrix = mat(datToClass) m = shape(dataMatrix)[0] aggClassEst = mat(zeros((m,1))) for i in range(len(classifierArr)): classEst = stumpClassify(dataMatrix,classifierArr[i]['dim'],classifierArr[i]['thresh'],classifierArr[i]['ineq']) aggClassEst += classifierArr[i]['alpha']*classEst print("aggClassEst:",aggClassEst) return sign(aggClassEst) #繪製資料圖形 def plot(datMat,classLabels): xcord0=[];xcord1=[];ycord0=[];ycord1=[] for i in range(len(classLabels)): if classLabels[i] == 1: xcord1.append(datMat[i,0]) ycord1.append(datMat[i,1]) else: xcord0.append(datMat[i,0]) ycord0.append(datMat[i,1]) fig = plt.figure() ax = fig.add_subplot(111) ax.scatter(xcord0,ycord0, marker='s', s=50) ax.scatter(xcord1,ycord1, marker='o', s=50, c='red') #繪製ROC曲線及AUC的計算 def plotROC(predStrengths, classLabels): cur = (1.0,1.0) ySum = 0.0 #numPosClass是真實結果中的所有正例 numPosClass = sum(np.array(classLabels) == 1.0) yStep = 1/float(numPosClass) xStep = 1/float(len(classLabels)-numPosClass) #獲得排好序的索引 sortedIndicies = np.argsort(predStrengths) fig = plt.figure() ax = fig.add_subplot(111) for index in sortedIndicies.tolist()[0]: if classLabels[index] == 1.0: delX = 0;delY = yStep; else: delX = xStep;delY = 0; ySum += cur[1] ax.plot([cur[0],cur[0]-delX],[cur[1],cur[1]-delY],c='b') cur = (cur[0]-delX,cur[1]-delY) ax.plot([0,1],[0,1],'b--') plt.xlabel("Flase Positive Rate") plt.ylabel("True Positive Rate") plt.title("ROC curve for AdaBoost Horse Colic Detection System") ax.axis([0,1,0,1]) plt.show() print("the Area Under the Curve is:",ySum*xStep) #測試 if __name__ =="__main__": """ dataMat,labels = loadSimpData() classifierArr = adaBoostTrainDS(dataMat,labels,30) result0 = adaClassify([0,0],classifierArr) print(result0) result1 = adaClassify([[5,5],[0,0]],classifierArr) print(result1) D = mat(ones((5,1))/5) weakClassArr = adaBoostTrainDS(dataMat,labels,9) print(weakClassArr) bestStump, minError, bestClasEst = bulidStump(dataMat,labels,D) print(bestStump,minError,bestClasEst) """ datArr,labelArr = loadDataSet('horseColicTraining2.txt') classifierArray,aggClassEst = adaBoostTrainDS(datArr,labelArr,10) testArr,testLabelArr = loadDataSet('horseColicTest2.txt') #分類器分類結果 prediction10 = adaClassify(testArr,classifierArray) print("預測結果:",prediction10.T) #計算錯誤率 errorArr = mat(ones((67,1))) errorRate = (errorArr[prediction10 !=mat(testLabelArr).T].sum())/67 print("錯誤率:",errorRate) plotROC(aggClassEst.T,labelArr)
3.3 部分結果顯示