
深度學習-多層感知器
多層感知器
多層感知器(Multilayer Perceptron,縮寫MLP)是一種前向結構的人工神經網路,對映一組輸入向量到一組輸出向量。MLP可以被看作是一個有向圖,由多個的節點層所組成,每一層都全連線到下一層。除了輸入節點,每個節點都是一個帶有非線性啟用函式的神經元(或稱處理單元)。一種被稱為反向傳播演算法的監督學習方法常被用來訓練MLP。 MLP是感知器的推廣,克服了感知器不能對線性不可分資料進行識別的弱點。
摘自:維基百科
https://zh.wikipedia.org/wiki/%E5%A4%9A%E5%B1%82%E6%84%9F%E7%9F%A5%E5%99%A8
前言
本博文主要介紹一下多層感知器的結構,並且用程式碼實現網路結構的初始化。隨筆而已,寫的比較粗躁。
模型結構
在之前的博文中說過一個感知器。其可以看作是一個單個的神經元。這次的多層感知器其實是對其的一個衍生和發展。
首先一個最簡單的MPL
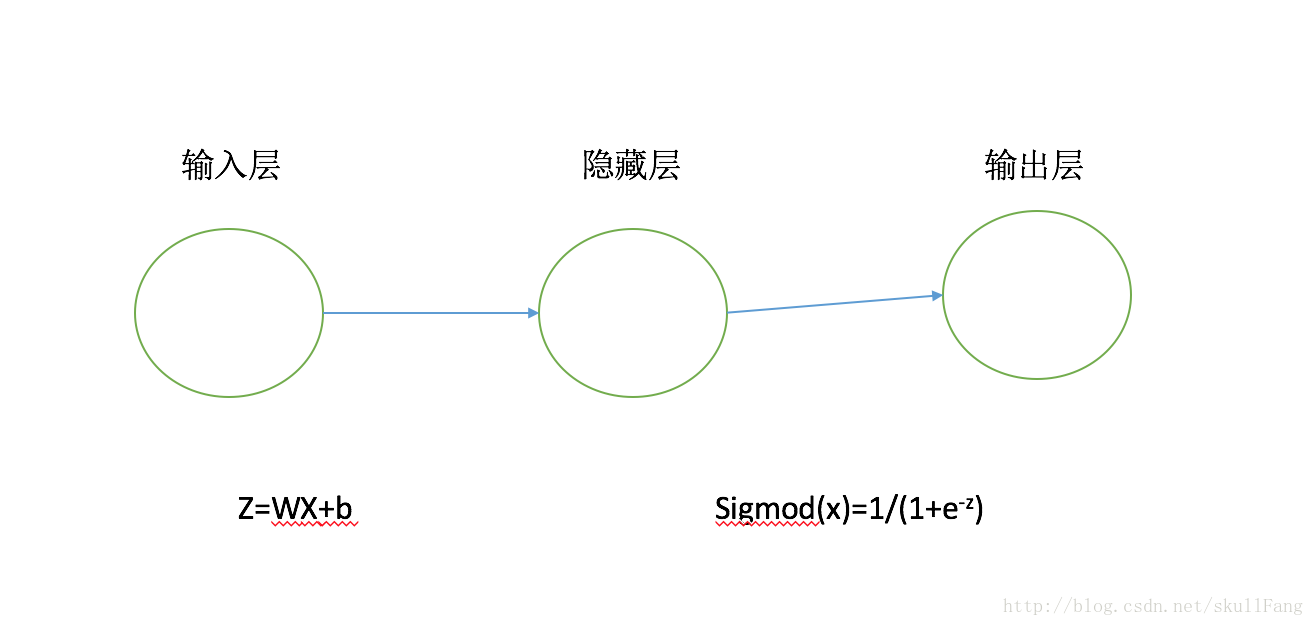
其中輸入向量為x。產生的刺激為z=wx+b
w為權重向量
b就是偏置(網上把偏置說的很懸其實就是這玩意)
啟用函式使用最簡單的sigmod函式(其實可以為很多)
這是函式影象

很簡單吧,模型圖上的每一根線就是一個z=wx+b 所以圖上需要兩個w向量,兩個b向量。(數數問題)
稍微複雜一點
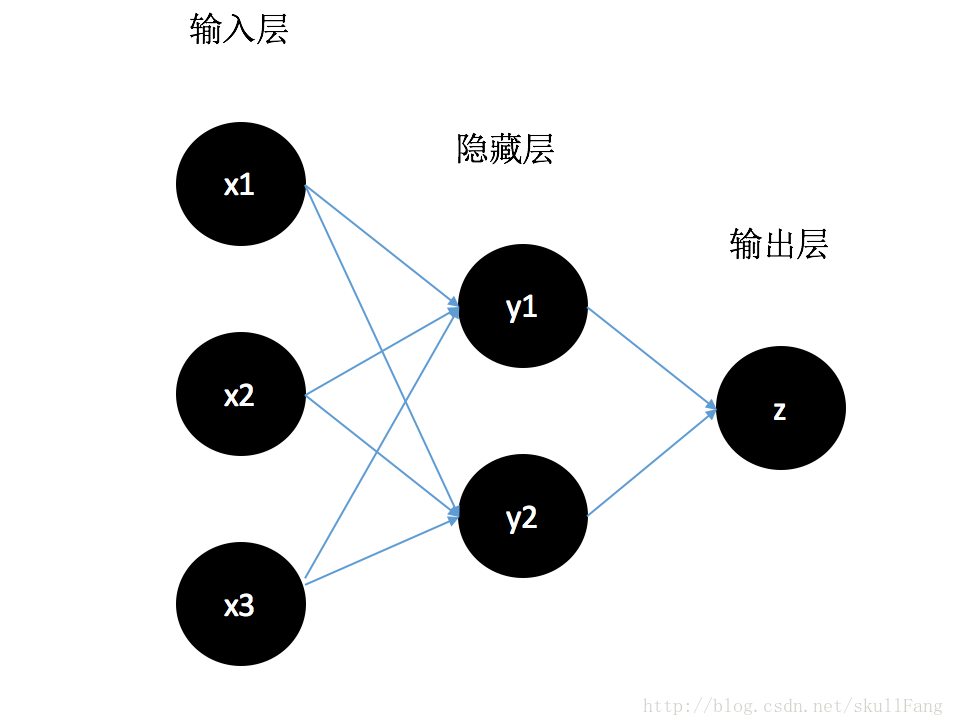
注意:一般神經網路中的輸入層是不算的。再就是一個神經元輸出只有一個實數。所以我們可以把輸入層看成是一個 X 向量。(不是一個神經元能產生一個X向量,一個神經元只能產生一個x1)
如圖:輸入層為三個我們可以看作x1,x2,x3 組成X向量。
產生的“刺激”:w1X+b1。經過刺激函式轉換成y1 (輸入層—>隱藏層).
同樣產生“刺激” w2X+b1。經過刺激函式轉換為y2
所以我們可以得到下面結論:
w1、w2是一個3*1的矩陣。
b1是一個2*1的矩陣。
同理:
“刺激“ w3Y+b2 得到最後結果Z(隱藏層->輸出層)
w3是一個2*1的矩陣
b2是一個1*1的矩陣
綜上所述
初始化我們需要3個W向量,兩個b向量。
初始化程式碼
# -*- coding: utf-8 -*-
# @Time : 2017/11/22 下午9:17
# @Author : SkullFang
# @Email : [email protected]
# @File : OneDemo.py
# @Software: PyCharm
import numpy as np
class Network(object):
def 相關推薦
深度學習-多層感知器
多層感知器 多層感知器(Multilayer Perceptron,縮寫MLP)是一種前向結構的人工神經網路,對映一組輸入向量到一組輸出向量。MLP可以被看作是一個有向圖,由多個的節點層所組成,每一層都全連線到下一層。除了輸入節點,每個節點都是一個帶有非線性啟
【深度學習】多層感知器解決異或問題
利用Python 建立兩層感知器,利用W-H學習規則訓練網路權值: #!/usr/bin/env python # -*- coding:utf-8 -*- import random import numpy as np import matplotl
深度學習筆記(三)用Torch實現多層感知器
上一次我們使用了輸出節點和輸入節點直接相連的網路。網路裡只有兩個可變引數。這種網路只能表示一條直線,不能適應複雜的曲線。我們將把它改造為一個多層網路。一個輸入節點,然後是兩個隱藏層,每個隱藏層有3個節點,每個隱藏節點後面都跟一個非線性的Sigmoid函式。如圖所示,這次
模式識別(Pattern Recognition)學習筆記(十九)--多層感知器模型(MLP)
早前已經學習了感知器學習演算法,主要通過對那些錯分類的樣本進行求和來表示對錯分樣本的懲罰,但明顯的它是一個線性的判別函式;而且上節學到了感知器神經元(閾值邏輯單元),對於單個的感知器神經元來說,儘管它能夠實現線性可分資料的分類問題(如與、或問題),但是卻無法解
tensorflow學習筆記——自編碼器及多層感知器
1,自編碼器簡介 傳統機器學習任務很大程度上依賴於好的特徵工程,比如對數值型,日期時間型,種類型等特徵的提取。特徵工程往往是非常耗時耗力的,在影象,語音和視訊中提取到有效的特徵就更難了,工程師必須在這些領域有非常深入的理解,並且使用專業演算法提取這些資料的特徵。深度學習則可以解決人工難以提取有效特徵的問題
多層感知器識別手寫數字算法程序
itl cti val shape erb ase 鏈接 n) frame 1 #coding=utf-8 2 #1.數據預處理 3 import numpy as np #導入模塊,numpy是擴展鏈接庫 4 import pan
Keras多層感知器:印第安糖尿病人診斷
例項中使用的是Pima Indians Diabetes資料集,資料集有八項屬性和對應輸出: (1)懷孕次數 (2)2小時口服葡萄糖耐量實驗中血漿葡萄糖濃度 (3)舒張壓 (4)三頭肌皮褶皺厚度 (5)2小時血清胰島素 (6)身體質量指數 (7)糖尿病譜系功能 (8)
國際旅行人數預測——使用多層感知器
這個例子是使用多層感知器來處理時間序列問題,例子來源於魏貞原老師的書。 資料集使用的是國際旅行旅客人數資料集(international-airline-passengers) 資料集下載:國際旅行旅客人數資料集(international-airline-passengers) 利用m
theano 多層感知器模型
本節要用Theano實現的結構是一個隱層的多層感知器模型(MLP)。MLP可以看成一種對數迴歸器,其中輸入通過非線性轉移矩陣ΦΦ做一個變換處理,以便於把輸入資料投影到一個線性可分的空間上。MLP的中間層一般稱為隱層。單一的隱層便可以確保MLP全域性近似。然而,我們稍後還會
keras多層感知器識別手寫數字
2.Keras建立多層感知器模型(接上一篇) 2.1簡單介紹多層感知器模型 注:以下模型及其說明來自於《TensorFlow+Keras深度學習人工智慧實踐應用》林大貴 著 以矩陣方式模擬多層感知器模型的工作方式(如下圖所示) 建立輸入與隱藏層的公式: h1=
MLP(多層感知器)神經網路
由前面介紹看到,單個感知器能夠完成線性可分資料的分類問題,是一種最簡單的可以“學習”的機器。但他無法解決非線性問題。比如下圖中的XOR問題:即(1,1)(-1,-1)屬於同一類,而(1,-1)(-1,1)屬於第二類的問題,不能由單個感知器正確分類。 即在Minsky和Papert的專著《感知器》所分
Keras多層感知器例項:印第安人糖尿病診斷
本例項使用Keras在python中建立一個神經網路模型,這是一個簡單的貫序模型,也是神經網路最常見的模型。本例項按照以下步驟建立: 1. 匯入資料。 2.定義模型 3.編譯模型 4.訓練模型 5.評估模型 6.彙總程式碼 Pima Indians糖尿病發病情況
scikit-learn中的多層感知器呼叫模型輸出資料型別為float出現Unknown label type: 'unknown'
受下面截圖的啟發,說的意思好像是輸出型別必須是絕對的(categorical),train_y後加上astype(‘int’)即可,fit(train_x,train_y.astype(‘int’)),但是不能試astype('float'),用這個還是會報錯,具體原因我不清楚,解決方法就是把輸出資
sknn多層感知器定義——sknn.mlp.MultiLayerPerceptron
sknn.mlp.MultiLayerPerceptron class sknn.mlp.MultiLayerPerceptron(layers, warning=None, parameters=N
人工智慧深度學習TensorFlow通過感知器實現鳶尾花資料集分類
一.iris資料集簡介 iris資料集的中文名是安德森鳶尾花卉資料集,英文全稱是Anderson’s Iris data set。iris包含150個樣本,對應資料集的每行資料。每行資料包含每個樣本的四個特徵和樣本的類別資訊,所以iris資料集是一個150行5列的二維表。 通俗地說,iris
資料探勘——多層感知器手寫體識別的Python實現
# coding=utf-8 from sklearn.datasets import load_digits from sklearn.cross_validation import train_test_split, cross_val_score fro
邏輯斯第迴歸、softmax分類與多層感知器
本專欄將推出一系列深度學習與影象處理相關的教程文章。注重原理精講和程式碼實現。實現框架將重點選擇Tensorflow或Pytorch。本講從邏輯斯第迴歸入手,然後講解softmax分類器,最後講解多層感知器。文末提供註釋詳盡的Tensorflow程式碼實現。
資料探勘——多層感知器演算法簡介
XOR(抑或)是一種非線性函式,不能被線性可分 人工神經網路簡介 人工神經網路由三部分組成: - 架構:描述神經元的層次與連線神經元的結構 - 激勵函式 - 找出最優權重值的學習演算法 人工神經網路主要型別: 1. 前饋神經網路:最常用
構建多層感知器神經網路對數字圖片進行文字識別
在Keras環境下構建多層感知器模型,對數字影象進行精確識別。 模型不消耗大量計算資源,使用了cpu版本的keras,以Tensorflow 作為backended,在ipython互動環境jupyter notebook中進行編寫。 1.資料來源 此資料庫包含四部分:訓練資
Python實現多層感知器MLP(基於雙月資料集)
1、載入必要的庫,生成資料集 import math import random import matplotlib.pyplot as plt import numpy as np class moon_data_class(object): def