
二分查詢、快速排序對比和詳解
這兩個都是用到分治的思想很容易搞混。而且即使binarySearch是用到分治也不一定意味著一定要用遞迴去實現,可以通過迴圈實現。二分查詢和快速排序屬於面試筆試的高頻問題有必要總結一下。
由於迴圈相比遞迴少了很多記憶體分配和壓棧的操作開銷會少很多,所以binarySearch最好的實現方式是通過迴圈實現。binarySearch有一個大前提是陣列是有序的,接下來沒什麼好解釋的直接程式碼:
int binarySearch(int *a,int l,int r,int number)
{
int mid = (l+r)/2;
while(l<=r){
if 快速排序主要思想也是分治,在升序(降序)排序的過程中:
兩個指標分別從陣列頭和尾部向中間遍歷,當尾部指標遇到比樞紐小(大)的值,頭部指標遇到比樞紐大(小),交換兩個指標所指向的值的位置。
這裡涉及到兩個比較關鍵容易混淆的問題:
1.樞紐的選取。
2.停止條件的設定。
3.當頭尾指標交叉後,樞紐和哪個指標進行交換。
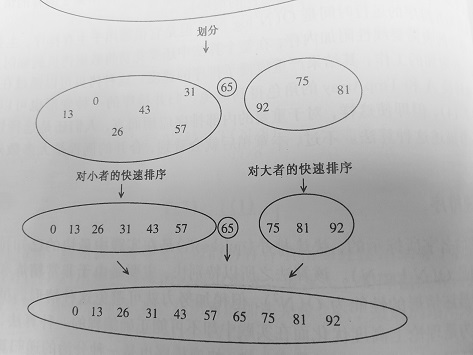
如圖所示當劃分完畢後,在樞紐左邊的應該是都比樞紐小(大);在樞紐右邊的應該都比樞紐大(小),總之他們相對於樞紐來說是相對有序的。所以最後樞紐所在的位置很關鍵。
樞紐的初始位置選擇有兩種最簡單的方法:選頭部和選尾部。
以下的解釋統一以升序為例子
樞紐的初始位置選擇有兩種最簡單的方法:選頭部和選尾部。
這時候劃分完畢之後交換的方案也有兩種主要根據樞紐的選擇位置來決定。
(1)如果樞紐選的是頭部,那麼劃分完畢後要和尾指標進行位置交換。因為要求交換完成後,樞紐左邊的都是小於樞紐的數,而此時在不越界的情況下尾指標所指位置是剛好小於樞紐
(2)如果樞紐選的是尾部的指標,則劃分完畢後要和頭指標進行交換。因為此時頭指標所指的位置恰好大於樞紐,因為在不越界的情況下樞紐元右側的均要大於樞紐元。
停止條件:
停止條件的設定不要在迴圈判斷體中設定,要在迴圈體內設定。理論上來講每一次比對的停止條件都是頭指標大於樞紐元素,尾指標指向小於樞紐元素。即使最後一次也不例外,因為要找分界點方便交換樞紐。
所以程式碼:
void myQuickSort(int *a,int left,int right)
{
if(left>=right)
return;
int l = left, r = right;
int pivot = left;//樞紐元選擇的是頭部
for(;;)
{
while(*(a+l) <= *(a+pivot)&& l<right)//防止越界
l++;
while(*(a+r) >= *(a+pivot)&& r>L)//防止越界
r--;
if(l<r)
myswap(a,l,r);
else
break;//如果屬於指標位置交叉的情況則停止
}
if(*(a+pivot)<*(a+r)) //如果此時尾指標指向的元素剛好大於樞紐元素
myswap(a,pivot,r);//樞紐和尾指標進行交換使得樞紐元右側的元素全部大於樞紐元,
myQuickSort(a,left,r-1);
myQuickSort(a,r+1,right);
}
選尾部作樞紐:
void myQuickSort(int *a,int left,int right)
{
if(left>=right)
return;
int l = left, r = right;
int pivot = right;//樞紐元選的尾部
for(;;)
{
while(*(a+l) <= *(a+pivot))
l++;
while(*(a+r) >= *(a+pivot))
r--;
if(l<r)
myswap(a,l,r);
else
break;
}
if(*(a+l) > *(a+pivot))
myswap(a,pivot,l);//和頭指標交換
myQuickSort(a,left,l-1);//不包含pivot
myQuickSort(a,l+1,right);//不包含pivot
}