
Python自然語言處理 8 分析句子結構
前面的章節重點關注詞:如何識別它們,分析它們的結構,給它們分配詞彙類別,以及獲得它們的含義。
目的是要回答下列問題:
(1)如何使用形式化語法來描述無限的句子集合的結構?
(2)如何使用句法樹來表示句子結構?
(3)解析器如何分析句子並自動構建語法樹?
一 一些語法困境
#語言資料和無限可能性
文法的目的是給出一個明確的語言描述。而我們思考文法的方式與我們認為什麼是一種語言緊密聯絡在一起。觀察到的言語和書面文字是否是一個大卻有限的集合呢?關於文法句子是否存在一些更抽象的東西,如有能力的說話者能理解的隱性知識?或者是兩者的某種組合?我們不會解決這個問題,而是將介紹主要的方法。
#普遍存在的歧義
重要的目的是自然語言understanding,當識別一個文字所包含的語言結構時,可以從中獲得多少文字的含義?一段程式在通讀了一個文字後,它能否足夠“理解”文字,並回答一些簡答的問題,如“發生了什麼事“或”誰對誰做了什麼“?還像以前一樣,我們將開發簡單的程式來處理已註釋的語料庫,並執行有用的任務。
二 文法的用途
#超越n-grams
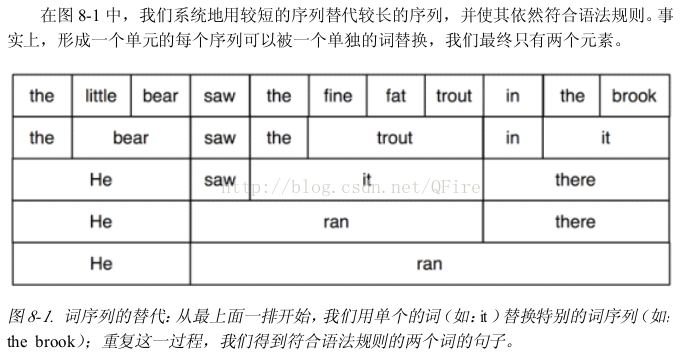
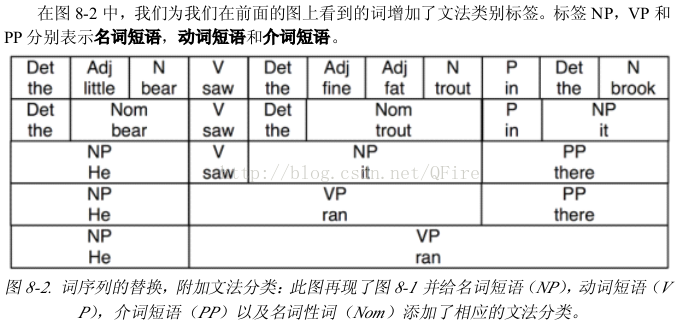
3 上下文無關文法
#一種簡單的文法
在NLTK中,上下文無關文法定義在nltk.grammar模組
如果使用上述文法分析句子The dog saw a man in the park,結果將得到兩棵樹,被稱為結構上有歧義import nltk from nltk import CFG //grammar1 = CFG.fromstring(""" grammar1 = nltk.parse_cfg(""" s -> NP VP VP -> V NP | V NP PP PP -> P NP V -> "saw" | "ate" | "walked" NP -> "John" | "Mary" | "Bob" | Det N | Det N PP Det -> "a" | "an" | "the" | "my" N -> "man" | "dog" | "cat" | "telescope" | "park" P -> "in" | "on" | "by" | "with" """) sent = "Mary saw Bob".split() rd_parser = nltk.RecursiveDescentParser(grammar1) for tree in rd_parser.nbest_parse(sent): print tree
#編寫你自己的文法
編寫mygrammar.cfg
grammar1 = nltk.data.load('file:mygrammar.cfg')#句法結構中的遞迴
產生式左側的文法型別也出現在右側,那麼這個文法被認為是遞迴的
四 上下文無關文法分析
解析器根據文法產生式處理輸入的句子,並建立一個或多個符合文法的組成結構。
例如問答系統對提交的問題首先進行文法分析
在本節中,我們將看到兩個簡單的分析演算法,一種自上而下的方法稱為下降遞迴分析,一種自下而上的方法稱為移進-歸約分析。
以及更復雜的演算法,一種稱為左角落分析的帶自下而上過濾的自上而下的方法:一種稱為圖表分析的動態規劃技術
#遞迴下降解析器
nltk.RecursiveDescentParser(grammar1)
#移進-歸約分析
nltk.ShiftReduceParser(grammar1)
#左角落解析器
帶自下而上過濾的自上而下的解析器
#符合語句規則的子串表
////////
五 依存關係和依存文法
短語結構文法是關於詞和詞序列如何結合形成句子成分的。
一種獨特且互補的方式,依存文法,集中關注的是詞與其他詞之間的關係。
依存關係是一箇中心詞與其從屬之間的二元非對稱關係。一個句子的中心詞通常是動詞,所有其他詞要麼依賴於中心詞,要麼通過依賴路徑與它相關聯。
與短語結構文法相比,依存文法可以作為一種依存關係用來直接表示語法功能。
#配價與詞彙
在表中的動詞被認為具有不同的配價。配價限制不僅適用於動詞,也適用於其他類的中心詞。

#擴大規模
文法是否可以擴大到能覆蓋自然語言中的大型語料庫
使用各種正規工具
六 文法開發
如何訪問樹庫,及開發覆蓋廣泛文法所具有的挑戰
#樹庫和文法
corpus模組定義了樹庫語料的閱讀器,其中包含了賓州樹庫語料10%的樣本
from nltk.corpus import treebank
t = treebank.parsed_sents('wsj_0001.mrg')[0]
print t
(S
(NP-SBJ
(NP (NNP Pierre) (NNP Vinken))
(, ,)
(ADJP (NP (CD 61) (NNS years)) (JJ old))
(, ,))
(VP
(MD will)
(VP
(VB join)
(NP (DT the) (NN board))
(PP-CLR (IN as) (NP (DT a) (JJ nonexecutive) (NN director)))
(NP-TMP (NNP Nov.) (CD 29))))
(. .))def filter(tree): #搜尋樹庫找出句子的補語
child_nodes = [child.label for child in tree if isinstance(child, nltk.Tree)]
#print tree.label
#print [t for t in tree if tree.label == 'NP']
return (tree.label == 'VP') and ('S' in child_nodes)
from nltk.corpus import treebank
[subtree for tree in treebank.parsed_sents()
for subtree in tree.subtrees(filter)]entries = nltk.corpus.ppattach.attachments('training')
table = nltk.defaultdict(lambda: nltk.defaultdict(set))
for entry in entries:
key = entry.noun1 + '-' + entry.prep + '-' + entry.noun2
table[key][entry.attachment].add(entry.verb)
for key in sorted(table):
if len(table[key]) > 1:
print key, 'N:', sorted(table[key]['N']), 'V:', sorted(table[key]['V'])nltk.corpus.sinica_treebank.parsed_sents()[3450].draw() #中央研究院樹庫語料#有害的歧義
歧義文法
#加權文法
處理歧義是開發覆蓋廣泛的解析器的主要任務。圖表解析器提高了計算同一個句子的多個分析的效率,但它們仍然會因可能的分析數量過多而不堪重負。加權文法和概率分析演算法為這些問題提供了有效的解決方案
def give(t):
return t.label == 'VP' and len(t) > 2 and t[1].label == 'NP' \
and (t[2].label == 'PP-DTV' or t[2].label == 'NP') \
and ('give' in t[0].leaves() or 'gave' in t[0].leaves())
def sent(t):
return ' '.join(token for token in t.leaves() if token[0] not in '*-0')
def print_node(t, width):
output = "%s %s: %s / %s: %s" %\
(sent(t[0]), t[1].label, sent(t[1]), t[2].label, sent(t[2]))
if len(output) > width:
output = output[:width] + "..."
print output
for tree in nltk.corpus.treebank.parsed_sents():
for t in tree.subtrees(give):
print_node(t, 72)#概率上下文無關文法(PCFG)
grammar = nltk.parse_pcfg("""
S -> NP VP [1.0]
VP -> TV NP [0.4]
VP -> IV [0.3]
VP -> DatV NP NP [0.3]
TV -> 'saw' [1.0]
IV -> 'ate' [1.0]
DatV -> 'gave' [1.0]
NP -> 'telescopes' [0.8]
NP -> 'Jack' [0.2]
""")