
kafka:python獲取kafka的值
需求:獲取通過python檢視kafka中的值
#!/user/local/python2.6.6/bin/python
# -*- coding: utf-8 -*-
# __project__ = src
# __author__ = [email protected]
# __date__ = 2016-09-21
# __time__ = 12:49
#kafka的節點
kafka_list = ["slave01:9092", "slave02:9092", "slave03:9092"]
from kafka import KafkaConsumer
from kafka import TopicPartition
import sys
import time 消費出來的日誌
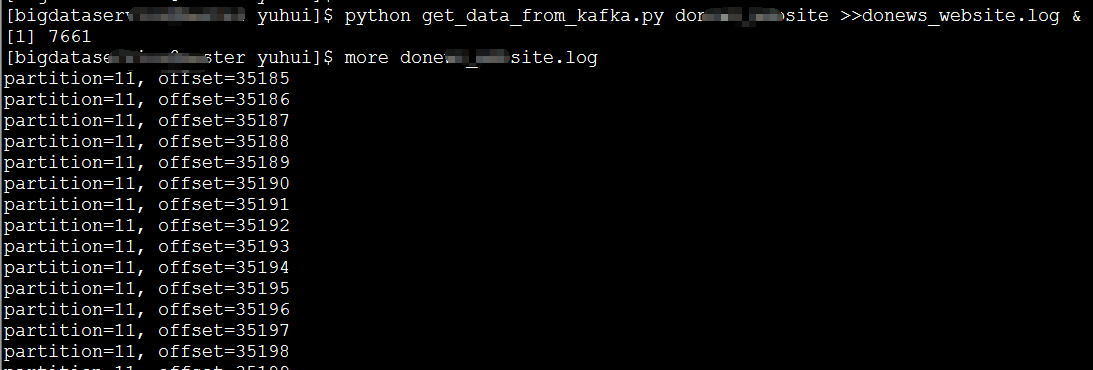
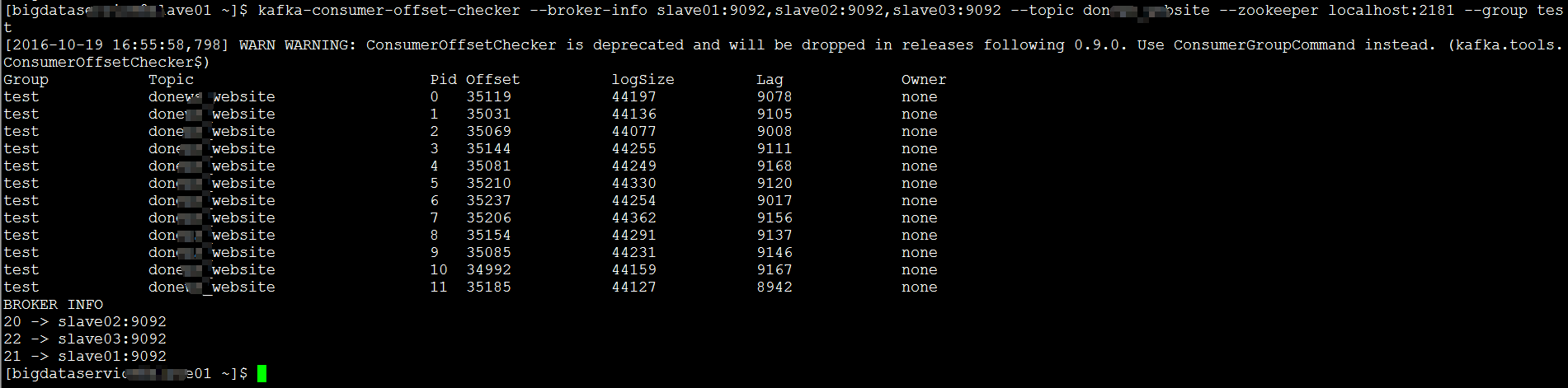
kafka中的topicName和partition
如果您喜歡我寫的博文,讀後覺得收穫很大,不妨小額贊助我一下,讓我有動力繼續寫出高質量的博文,感謝您的讚賞!微信

相關推薦
kafka:python獲取kafka的值
需求:獲取通過python檢視kafka中的值 #!/user/local/python2.6.6/bin/python # -*- coding: utf-8 -*- # __project__
wurstmeister/kafka:docker構建kafka遇到的問題
遇到 技術分享 解決方案 docker 描述 jvm -a png img 1. kafka 容器無法啟動 過程描述: docker ps -a 看到 Exited docker logs a87d9cd2a8ac 查看日誌:
python學習(六):python中賦值、淺拷貝、深拷貝的區別
存在賦值、淺拷貝、深拷貝問題的資料型別是對組合物件來說,所謂的組合物件就是包含了其它物件的物件,如列表,類例項。 其他的單個物件則不存在這個問題。 可變物件: list, dict. 不可變物件有: int, string, float, tuple.
學習筆記 --- Kafka Spark Streaming獲取Kafka資料 Receiver與Direct的區別
Receiver 使用Kafka的高層次Consumer API來實現 receiver從Kafka中獲取的資料都儲存在Spark Executor的記憶體中,然後Spark Streaming啟動的job會去處理那些資料 要啟用高可靠機制,讓資料零丟失,就必須啟用Spark
省市區縣純js三級聯動(改寫版:可獲取選擇值)
網上有許多js版本的三級聯動,但是都沒有完整的拿到值的文章,或是沒有拿全,在網上down了一個js,並對其進行修改,可獲取到省市區縣三項的值,具體方式如下: jsp頁面GBK編碼:(在webRoot下) 在頁面中新增地址隱藏域,一邊向後臺傳值,省市縣用“|”拼接出來,再到
【pykafka】爬蟲篇:python使用python連線kafka介紹(四)
本人菜雞,最近還更新python的爬蟲系列,有什麼錯誤,還望大家批評指出! 該系列暫時總共有4篇文章,連線如下: 【python】爬蟲篇:python連線postgresql(一):https://blog.csdn.net/lsr40/article/details/83311860
Kafka:無丟失提取kafka的值,詳解kafka的消費過程
目錄: 1、需求 2、程式碼步鄹 3、程式碼展現 4、pom.xml檔案 5、結果展現 ——————————————————————————————————– 1、需求 前提:將org.apache.spark.streaming.kafka.KafkaCluster這個類抽出來變成Kafka
Spark-Streaming獲取kafka資料的兩種方式:Receiver與Direct的方
簡單理解為:Receiver方式是通過zookeeper來連線kafka佇列,Direct方式是直接連線到kafka的節點上獲取資料 回到頂部 使用Kafka的高層次Consumer API來實現。receiver從Kafka中獲取的資料都儲存在Spark Exec
kfka學習筆記二:使用Python操作Kafka
1、準備工作 使用python操作kafka目前比較常用的庫是kafka-python庫,但是在安裝這個庫的時候需要依賴setuptools庫和six庫,下面就要分別來下載這幾個庫 1、下載setuptools 開啟這個網址會彈出類似下面的額下載視窗,選擇儲存檔案,點選確定
Kafka Consumer(Python threading)
art 1.10 rec ive sta print rt thread con err import threadingfrom kafka import KafkaConsumerthreads = []class MyThread(threading.Thread):
Kafka Producer(Python threading)
bootstra tar () imp bootstrap pla oot produce init import threadingimport timeimport randomfrom kafka import KafkaProducerproducer = Kafk
Apache Kafka:下一代分布式消息系統
嚴重 依賴 ring 簡介 mes 傳統 aid .com bit 簡介 Apache Kafka是分布式發布-訂閱消息系統。它最初由LinkedIn公司開發,之後成為Apache項目的一部分。Kafka是一種快速、可擴展的、設計內在就是分布式的,分區的和可復制的提交日誌
獲取kafka最新offset-scala
com ora each main 通過 最新 intval sim exist 無論是在spark streaming消費kafka,或是監控kafka的數據時,我們經常會需要知道offset最新情況 kafka數據的topic基於分區,並且通過每個partition的主
python執行系統命令後獲取返回值
這就是 () err div log system clas pri 命令 import os, subprocess# os.system(‘dir‘) #執行系統命令,沒有獲取返回值,windows下中文亂碼# result = os.popen(‘dir‘)
Kafka實戰:如何把Kafka消息時延秒降10倍
Kafka 消息服務 時延 背景 中軟獨家中標稅務核心征管系統,全國34個省國/地稅。電子稅務局15省格局。大數據×××局點,中國軟件電子稅務局技術路徑:核心征管 + 納稅服務 業務應用分布式上雲改造。 業務難題 如上圖所示是模擬客戶的業務網頁構建的一個並發訪問模型。用戶在頁面點擊從而產生一個HT
Java調用Python腳本並獲取返回值
enum 獲取 error code adt catch sys.argv AI oot 在Java程序中有時需要調用Python的程序,這時可以使用一般的PyFunction來調用python的函數並獲得返回值,但是采用這種方法有可能出現一些莫名其妙的錯誤,比如Impor
Kafka:ZK+Kafka+Spark Streaming集群環境搭建(三)安裝spark2.2.1
node word clas 執行 選擇 dir clust 用戶名 uil 如何配置centos虛擬機請參考《Kafka:ZK+Kafka+Spark Streaming集群環境搭建(一)VMW安裝四臺CentOS,並實現本機與它們能交互,虛擬機內部實現可以上網。》 如
Kafka:ZK+Kafka+Spark Streaming集群環境搭建(九)安裝kafka_2.11-1.1.0
itl CA blog tor line cat pre PE atan 如何搭建配置centos虛擬機請參考《Kafka:ZK+Kafka+Spark Streaming集群環境搭建(一)VMW安裝四臺CentOS,並實現本機與它們能交互,虛擬機內部實現可以上網。》 如
Kafka:ZK+Kafka+Spark Streaming集群環境搭建(二)VMW安裝四臺CentOS,並實現本機與它們能交互,虛擬機內部實現可以上網。
centos 失敗 sco pan html top n 而且 div href Centos7出現異常:Failed to start LSB: Bring up/down networking. 按照《Kafka:ZK+Kafka+Spark Streaming集群環
Kafka:ZK+Kafka+Spark Streaming集群環境搭建(十三)定義一個avro schema使用comsumer發送avro字符流,producer接受avro字符流並解析
finall ges records ring ack i++ 一個 lan cde 參考《在Kafka中使用Avro編碼消息:Consumer篇》、《在Kafka中使用Avro編碼消息:Producter篇》 pom.xml <depende