
深度學習入門操作篇
轉自:https://blog.csdn.net/u014696921/article/details/57084223
人工神經元和神經網路
一個神經元的結構相對來說是比較簡單的,於是,科學家們就思考,我們的AI是否可以從中獲得借鑑?神經元接受激勵,輸出一個響應的方式,同計算機中的輸入輸出非常類似,看起來簡直就是量身定做的,剛好可以用一個函式來模擬。

通過借鑑和參考神經元的機制,科學家們模擬出了人工神經元和人工神經網路。當然,通過上述這個抽象的描述和圖,比較難讓大家理解它的機制和原理。我們以“房屋價格測算”作為例子,一起來看看:
一套房子的價格,會受到很多因素的影響,例如地段、朝向、房齡、面積、銀行利率等等,這些因素如果細分,可能會有幾十個。一般在深度學習模型裡,這些影響結果的因素我們稱之為特徵。我們先假設一種極端的場景,例如影響價格的特徵只有一種,就是房子面積。於是我們收集一批相關的資料,例如,50平米50萬、93平米95萬等一系列樣本資料,如果將這些樣本資料放到而為座標裡看,則如下圖:
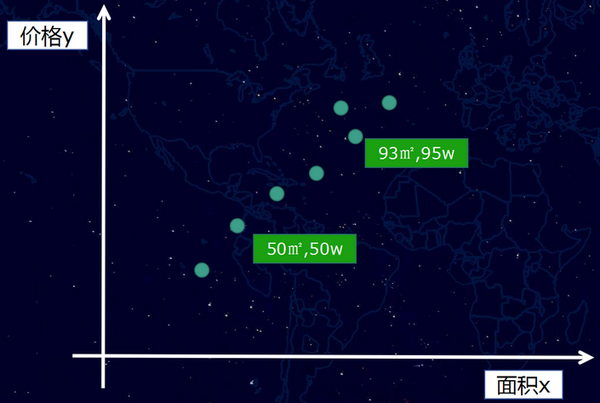
然後,正如我們前面所說的,我們嘗試用一個“函式”去擬合這個輸入(面積x)和輸出(價格y),簡而言之,我們就是要通過一條直線或者曲線將這些點“擬合”起來。
假設情況也比較極端,這些點剛好可以用一條“直線”擬合(真實情況通常不會是直線),如下圖:
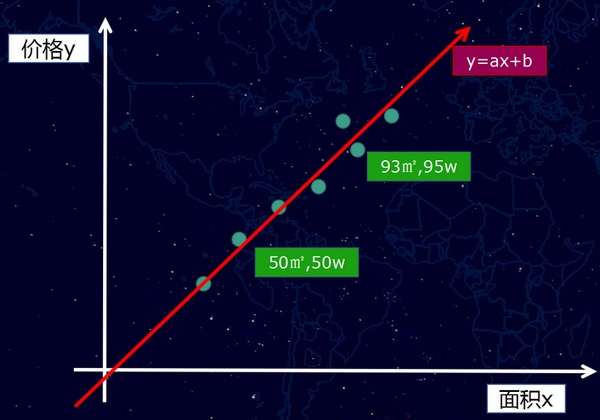
那麼我們的函式是一個一次元方程f(x) = ax +b,當然,如果是曲線的話,我們得到的將是多次元方程。我們獲得這個f(x) = ax +b的函式之後,接下來就可以做房價“預測”,例如,我們可以計算一個我們從未看見的面積案例81.5平方米,它究竟是多少錢?
這個新的樣本案例,可以通過直線找到對應的點(黃色的點),如圖下:
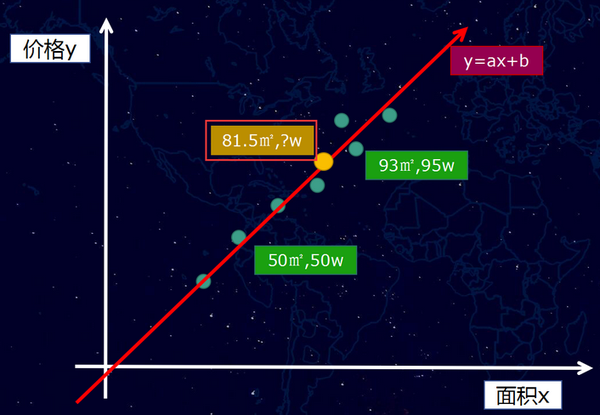
粗略的理解,上面就是AI的概括性的運作方式。這一切似乎顯得過於簡單了?當然不會,因為,我們前面提到,影響房價其實遠不止一個特徵,而是有幾十個,這樣問題就比較複雜了,接下來,這裡則要繼續介紹深度學習模型的訓練方式。這部分內容相對複雜一點,我儘量以業務工程師的視角來做一個粗略而簡單的闡述。
3. 深度學習模型的訓練方式
當有好幾十個特徵共同影響價格的時候,自然就會涉及權重分配的問題,例如有一些對房價是主要正權重的,例如地段、面積等,也有一些是負權重的,例如房齡等。
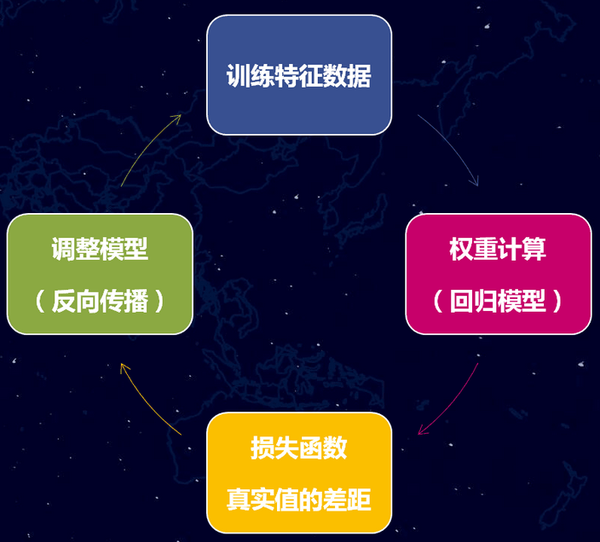
(1)初始化權重計算
那麼,第一個步其實是給這些特徵加一個權重值,但是,最開始我們根本不知道這些權重值是多少?怎麼辦呢?不管那麼多了,先給它們隨機賦值吧。隨機賦值,最終計算出來的估算房價肯定是不準確的,例如,它可能將價值100萬的房子,計算成了10萬。
(2)損失函式
因為現在模型的估值和實際估值差距比較大,於是,我們需要引入一個評估“不準確”程度的衡量角色,也就是損失(loss)函式,它是衡量模型估算值和真實值差距的標準,損失函式越小,則模型的估算值和真實值的察覺越小,而我們的根本目的,就是降低這個損失函式。讓剛剛的房子特徵的模型估算值,逼近100萬的估算結果。
(3)模型調整
通過梯度下降和反向傳播,計算出朝著降低損失函式的方向調整權重引數。舉一個不恰當的比喻,我們給面積增加一些權重,然後給房子朝向減少一些權重(實際計算方式,並非針對單個個例特徵的調整),然後損失函式就變小了。
(4)迴圈迭代
調整了模型的權重之後,就可以又重新取一批新的樣本資料,重複前面的步驟,經過幾十萬次甚至更多的訓練次數,最終估算模型的估算值逼近了真實值結果,這個模型的則是我們要的“函式”。
為了讓大家更容易理解和直觀,採用的例子比較粗略,並且講述深度學習模型的訓練過程,中間省略了比較多的細節。講完了原理,那麼我們就開始講講如何學習和搭建demo。
三、深度學習環境搭建
在2個月前(2016年11月),人工智慧對我來說,只是一個高大上的概念。但是,經過一個多月的業餘時間的認真學習,我發現還是能夠學到一些東西,並且跑一些demo和應用出來的。
1. 學習的提前準備
(1)部分數學內容的複習,高中數學、概率、線性代數等部分內容。(累計花費了10個小時,,挑了關鍵的點看了下,其實還是不太夠,只能讓自己看公式的時候,相對沒有那麼懵)
(2)Python基礎語法學習。(花費了3個小時左右,我以前從未寫過Python,因為後面Google的TensorFlow框架的使用是基於Python的)
(3)Google的TensorFlow深度學習開源框架。(花費了10多個小時去看)
數學基礎好或者前期先不關注原理的同學,數學部分不看也可以開始做,全憑個人選擇。
2. Google的TensorFlow開源深度學習框架
深度學習框架,我們可以粗略的理解為是一個“數學函式”集合和AI訓練學習的執行框架。通過它,我們能夠更好的將AI的模型執行和維護起來。
深度學習的框架有各種各樣的版本(Caffe、Torch、Theano等等),我只接觸了Google的TensorFlow,因此,後面的內容都是基於TensorFlow展開的,它的詳細介紹這裡不展開講述,建議直接進入官網檢視。非常令人慶幸的是TensorFlow比較早就有中文社群了,儘管裡面的內容有一點老,搭建環境方面有一些坑,但是已經屬於為數不多的中文文件了,大家且看且珍惜。
3. TensorFlow環境搭建
環境搭建本身並不複雜,主要解決相關的依賴。但是,基礎庫的依賴可以帶來很多問題,因此,建議儘量一步到位,會簡單很多。
(1)作業系統
我搭建環境使用的機器是騰訊雲上的機器,軟體環境如下:
作業系統:CentOS 7.2 64位(GCC 4.8.5)
因為這個框架依賴於python2.7和glibc 2.17。比較舊的版本的CentOS一般都是python2.6以及版本比較低的glibc,會產生比較的多基礎庫依賴問題。而且,glibc作為Linux的底層庫,牽一髮動全身,直接對它升級是比較複雜,很可能會帶來更多的環境異常問題。
(2)軟體環境
我目前安裝的Python版本是python-2.7.5,建議可以採用yum install python的方式安裝相關的原來軟體。然後,再安裝 python內的元件包管理器pip,安裝好pip之後,接下來的其他軟體的安裝就相對比較簡單了。
例如安裝TensorFlow,可通過如下一句命令完成(它會自動幫忙解決一些庫依賴問題):
pip install -U tensorflow
這裡需要特別注意的是,不要按照TensorFlow的中文社群的指引去安裝,因為它會安裝一個非常老的版本(0.5.0),用這個版本跑很多demo都會遇到問題的。而實際上,目前通過上述提供的命令安裝,是tensorflow (1.0.0)的版本了。

Python(2.7.5)下的其他需要安裝的關鍵元件:
tensorflow (0.12.1),深度學習的核心框架
image (1.5.5),影象處理相關,部分例子會用到
PIL (1.1.7),影象處理相關,部分例子會用到
除此之後,當然還有另外的一些依賴元件,通過pip list命令可以檢視我們安裝的python元件:
appdirs (1.4.0)
backports.ssl-match-hostname (3.4.0.2)
chardet (2.2.1)
configobj (4.7.2)
decorator (3.4.0)
Django (1.10.4)
funcsigs (1.0.2)
image (1.5.5)
iniparse (0.4)
kitchen (1.1.1)
langtable (0.0.31)
mock (2.0.0)
numpy (1.12.0)
packaging (16.8)
pbr (1.10.0)
perf (0.1)
PIL (1.1.7)
Pillow (3.4.2)
pip (9.0.1)
protobuf (3.2.0)
pycurl (7.19.0)
pygobject (3.14.0)
pygpgme (0.3)
pyliblzma (0.5.3)
pyparsing (2.1.10)
python-augeas (0.5.0)
python-dmidecode (3.10.13)
pyudev (0.15)
pyxattr (0.5.1)
setuptools (34.2.0)
six (1.10.0)
slip (0.4.0)
slip.dbus (0.4.0)
tensorflow (1.0.0)
urlgrabber (3.10)
wheel (0.29.0)
yum-langpacks (0.4.2)
yum-metadata-parser (1.1.4)
按照上述提供的來搭建系統,可以規避不少的環境問題。
搭建環境的過程中,我遇到不少問題。例如:在跑官方的例子時的某個報,AttributeError: 'module' object has no attribute 'gfile',就是因為安裝的TensorFlow的版本比較老,缺少gfile模組導致的。而且,還有各種各樣的。
更詳細的安裝說明:
(3)TensorFlow環境測試執行
測試是否安裝成功,可以採用官方的提供的一個短小的例子,demo生成了一些三維資料, 然後用一個平面擬合它們(官網的例子採用的初始化變數的函式是initialize_all_variables,該函式在新版本里已經被廢棄了):
#!/usr/bin/python
#coding=utf-8
import tensorflow as tf
import numpy as np
# 使用 NumPy 生成假資料(phony data), 總共 100 個點.
x_data = np.float32(np.random.rand(2, 100)) # 隨機輸入
y_data = np.dot([0.100, 0.200], x_data) + 0.300
# 構造一個線性模型
#
b = tf.Variable(tf.zeros([1]))
W = tf.Variable(tf.random_uniform([1, 2], -1.0, 1.0))
y = tf.matmul(W, x_data) + b
# 最小化方差
loss = tf.reduce_mean(tf.square(y - y_data))
optimizer = tf.train.GradientDescentOptimizer(0.5)
train = optimizer.minimize(loss)
# 初始化變數,舊函式(initialize_all_variables)已經被廢棄,替換為新函式
init = tf.global_variables_initializer()
# 啟動圖 (graph)
sess = tf.Session()
sess.run(init)
# 擬合平面
for step in xrange(0, 201):
sess.run(train)
if step % 20 == 0:
print step, sess.run(W), sess.run(b)
# 得到最佳擬合結果 W: [[0.100 0.200]], b: [0.300]
執行的結果類似如下:

經過200次的訓練,模型的引數逐漸逼近最佳擬合的結果(W: [[0.100 0.200]], b: [0.300]),另外,我們也可以從程式碼的“風格”中,瞭解到框架樣本訓練的基本執行方式。雖然,官方的教程後續會涉及越來越多更復雜的例子,但從整體上看,也是類似的模式。

步驟劃分:
- 準備資料:獲得有標籤的樣本資料(帶標籤的訓練資料稱為有監督學習);
- 設定模型:先構建好需要使用的訓練模型,可供選擇的機器學習方法其實也挺多的,換而言之就是一堆數學函式的集合;
- 損失函式和優化方式:衡量模型計算結果和真實標籤值的差距;
- 真實訓練運算:訓練之前構造好的模型,讓程式通過迴圈訓練和學習,獲得最終我們需要的結果“引數”;
- 驗證結果:採用之前模型沒有訓練過的測試集資料,去驗證模型的準確率。
其中,TensorFlow為了基於python實現高效的數學計算,通常會使用到一些基礎的函式庫,例如Numpy(採用外部底層語言實現),但是,從外部計算切回到python也是存在開銷的,尤其是在幾萬幾十萬次的訓練過程。因此,Tensorflow不單獨地執行單一的函式計算,而是先用圖描述一系列可互動的計算操作流程,然後全部一次性提交到外部執行(在其他機器學習的庫裡,也是類似的實現)。所以,上述流程圖中,藍色部分都只是設定了“計算操作流程”,而綠色部分開始才是真正的提交資料給到底層庫進行實際運算,而且,每次訓練一般是批量執行一批資料的。