
Redis高階特性及應用場景
Redis高階特性及應用場景
redis中鍵的生存時間(expire)
redis中可以使用expire命令設定一個鍵的生存時間,到時間後redis會自動刪除它。
- 過期時間可以設定為秒或者毫秒精度。
- 過期時間解析度總是 1 毫秒。
- 過期資訊被複制和持久化到磁碟,當 Redis 停止時時間仍然在計算 (也就是說 Redis 儲存了過期時間)。
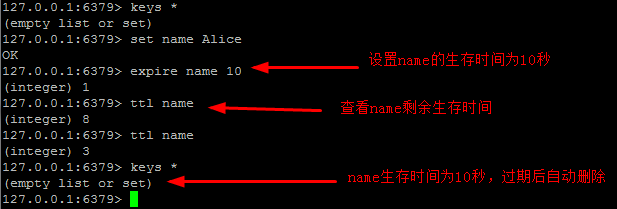
expire 設定生存時間(單位/秒)
expire key seconds(秒)ttl 檢視鍵的剩餘生存時間
ttl keypersist 取消生存時間
persist keyexpireat [key] unix時間戳1351858600
示例:
EXPIREAT cache 1355292000 # 這個 key 將在 2012.12.12 過期操作圖示:
應用場景:
- 限時的優惠活動資訊
- 網站資料快取(對於一些需要定時更新的資料,例如:積分排行榜)
- 手機驗證碼
- 限制網站訪客訪問頻率(例如:1分鐘最多訪問10次)
redis的事務(transaction)
redis中的事務是一組命令的集合。事務同命令一樣都是redis的最小執行單元。一組事務中的命令要麼都執行,要麼都不執行。(例如:轉賬)
原理:
先將屬於一個事務的命令傳送給redis進行快取,最後再讓redis依次執行這些命令。
應用場景:
- 一組命令必須同時都執行,或者都不執行。
- 我們想要保證一組命令在執行的過程之中不被其它命令插入。
命令:
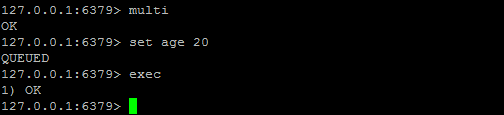
multi //事務開始
.....
exec //事務結束,開始執行事務中的命令
discard //放棄事務錯誤處理
1:語法錯誤:致命的錯誤,事務中的所有命令都不會執行
2:執行錯誤:不會影響事務中其他命令的執行
Redis 不支援回滾(roll back)
正因為redis不支援回滾功能,才使得redis在事務上可以保持簡潔和快速。
watch命令
作用:監控一個或者多個鍵,當被監控的鍵值被修改後阻止之後的一個事務的執行。
但是不能保證其它客戶端不修改這一鍵值,所以我們需要在事務執行失敗後重新執行事務中的命令。
注意:執行完事務的exec命令之後,watch就會取消對所有鍵值的監控
unwatch:取消監控
操作圖示:
redis中資料的排序(sort)
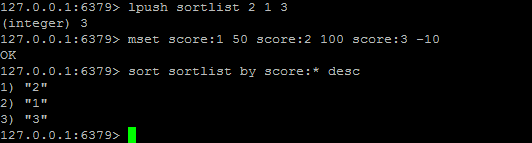
sort命令可以對列表型別,集合型別和有序集合型別進行排序。
sort key [desc] [limit offset count]by 參考鍵(參考鍵可以是字串型別或者是hash型別的某個欄位,hash型別的格式為:鍵名->欄位名)
- 如果參考鍵中不帶*號則不排序
- 如果某個元素的參考鍵不存在,則預設參考鍵的值為0
擴充套件 get引數
- get引數的規則和by引數的規則一樣
- get # (返回元素本身的值)
擴充套件 store引數
使用store 引數可以把sort的排序結果儲存到指定的列表中
效能優化
1:儘可能減少待排序鍵中元素的數量
2:使用limit引數只獲取需要的資料
3:如果要排序的資料數量很大,儘可能使用store引數將結果快取。
操作圖示:

“釋出/訂閱”模式
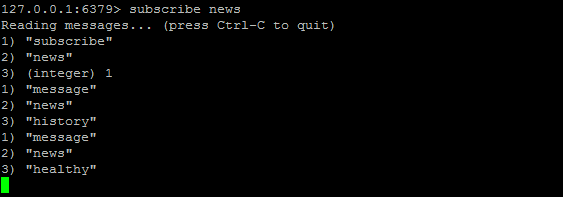
釋出:publish
publish channel message訂閱:subscribe
subscribe channel [.....]取消訂閱:unsubscribe
unsubscribe [channel]按照規則訂閱:psubscribe
psubscribe channel ?按照規則取消訂閱:punsubscribe
注意:使用punsubscribe命令只能退訂通過psubscribe 訂閱的頻道。
操作圖示:(訂閱頻道後,頻道每釋出一條訊息,都能動態顯示出來)
訂閱:
釋出:

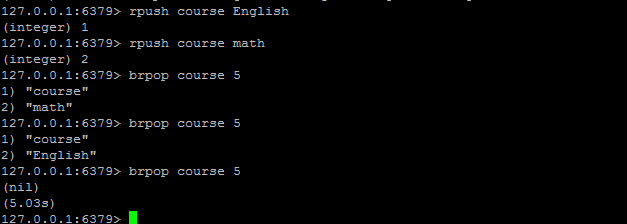
redis任務佇列
任務佇列:使用lpush和rpop(brpop)可以實現普通的任務佇列。
brpop是列表的阻塞式(blocking)彈出原語。
它是 RPOP命令的阻塞版本,當給定列表內沒有任何元素可供彈出的時候,連線將被 BRPOP命令阻塞,直到等待超時或發現可彈出元素為止。
當給定多個 key 引數時,按引數 key 的先後順序依次檢查各個列表,彈出第一個非空列表的尾部元素。
優先順序佇列:
brpop key1 key2 key3 timeout操作圖示:
redis管道(pipeline)
redis的pipeline(管道)功能在命令列中沒有,但是redis是支援管道的,在java的客戶端(jedis)中是可以使用的。
測試發現:
1:不使用管道方式,插入1000條資料耗時328毫秒
// 測試不使用管道
public static void testInsert() {
long currentTimeMillis = System.currentTimeMillis();
Jedis jedis = new Jedis("192.168.33.130", 6379);
for (int i = 0; i < 1000; i++) {
jedis.set("test" + i, "test" + i);
}
long endTimeMillis = System.currentTimeMillis();
System.out.println(endTimeMillis - currentTimeMillis);
}2:使用管道方式,插入1000條資料耗時37毫秒
// 測試管道
public static void testPip() {
long currentTimeMillis = System.currentTimeMillis();
Jedis jedis = new Jedis("192.168.33.130", 6379);
Pipeline pipelined = jedis.pipelined();
for (int i = 0; i < 1000; i++) {
pipelined.set("bb" + i, i + "bb");
}
pipelined.sync();
long endTimeMillis = System.currentTimeMillis();
System.out.println(endTimeMillis - currentTimeMillis);
}在插入更多資料的時候,管道的優勢更加明顯:測試10萬條資料的時候,不使用管道要40秒,實用管道378毫秒。
redis持久化(persistence)
redis支援兩種方式的持久化,可以單獨使用或者結合起來使用。
第一種:RDB方式(redis預設的持久化方式)
第二種:AOF方式
redis持久化之RDB
rdb方式的持久化是通過快照完成的,當符合一定條件時redis會自動將記憶體中的所有資料執行快照操作並存儲到硬碟上。預設儲存在dump.rdb檔案中。(檔名在配置檔案中dbfilename)
redis進行快照的時機(在配置檔案redis.conf中)
save 900 1 //表示900秒內至少一個鍵被更改則進行快照。
save 300 10 //表示300秒內10條被更改則快照
save 60 10000 //60秒內10000條Redis自動實現快照的過程
1、redis使用fork函式複製一份當前程序的副本(子程序)
2、父程序繼續接收並處理客戶端發來的命令,而子程序開始將記憶體中的資料寫入硬碟中的臨時檔案
3、當子程序寫入完所有資料後會用該臨時檔案替換舊的RDB檔案,至此,一次快照操作完成。
注意:redis在進行快照的過程中不會修改RDB檔案,只有快照結束後才會將舊的檔案替換成新的,也就是說任何時候RDB檔案都是完整的。
這就使得我們可以通過定時備份RDB檔案來實現redis資料庫的備份
RDB檔案是經過壓縮的二進位制檔案,佔用的空間會小於記憶體中的資料,更加利於傳輸。
手動執行save或者bgsave命令讓redis執行快照。
兩個命令的區別在於,save是由主程序進行快照操作,會阻塞其它請求。bgsave是由redis執行fork函式複製出一個子程序來進行快照操作。
檔案修復:
redis-check-dumprdb的優缺點
優點:由於儲存的有資料快照檔案,恢復資料很方便。
缺點:會丟失最後一次快照以後更改的所有資料。
redis持久化之AOF
aof方式的持久化是通過日誌檔案的方式。預設情況下redis沒有開啟aof,可以通過引數appendonly引數開啟。
appendonly yesaof檔案的儲存位置和rdb檔案的位置相同,都是dir引數設定的,預設的檔名是appendonly.aof,可以通過appendfilename引數修改
appendfilename appendonly.aofredis寫命令同步的時機
appendfsync always 每次都會執行
appendfsync everysec 預設 每秒執行一次同步操作(推薦,預設)
appendfsync no不主動進行同步,由作業系統來做,30秒一次aof日誌檔案重寫
auto-aof-rewrite-percentage 100(當目前aof檔案大小超過上一次重寫時的aof檔案大小的百分之多少時會再次進行重寫,如果之前沒有重寫,則以啟動時的aof檔案大小為依據)
auto-aof-rewrite-min-size 64mb手動執行bgrewriteaof進行重寫
重寫的過程只和記憶體中的資料有關,和之前的aof檔案無關。
所謂的“重寫”其實是一個有歧義的詞語, 實際上, AOF 重寫並不需要對原有的 AOF 檔案進行任何寫入和讀取, 它針對的是資料庫中鍵的當前值。
檔案修復:
redis-check-aof動態切換redis持久方式,從 RDB 切換到 AOF(支援Redis 2.2及以上)
CONFIG SET appendonly yes
CONFIG SET save ""(可選)注意:
1、當redis啟動時,如果rdb持久化和aof持久化都打開了,那麼程式會優先使用aof方式來恢復資料集,因為aof方式所儲存的資料通常是最完整的。如果aof檔案丟失了,則啟動之後資料庫內容為空。
2、如果想把正在執行的redis資料庫,從RDB切換到AOF,建議先使用動態切換方式,再修改配置檔案,重啟資料庫。(不能自己修改配置檔案,重啟資料庫,否則資料庫中資料就為空了。)
redis中的config命令
使用config set可以動態設定引數資訊,伺服器重啟之後就失效了。
config set appendonly yes
config set save "90 1 30 10 60 100"使用config get可以檢視所有可以使用config set命令設定的引數
config get *使用config rewrite命令對啟動 Redis 伺服器時所指定的 redis.conf 檔案進行改寫(Redis 2.8 及以上版本才可以使用),主要是把使用config set動態指定的命令儲存到配置檔案中。
config rewrite注意:config rewrite命令對 redis.conf 檔案的重寫是原子性的, 並且是一致的: 如果重寫出錯或重寫期間伺服器崩潰, 那麼重寫失敗, 原有 redis.conf 檔案不會被修改。 如果重寫成功, 那麼 redis.conf 檔案為重寫後的新檔案。
redis的安全策略
設定資料庫密碼
修改配置
requirepass password驗證密碼
auth passwordbind引數(可以讓資料庫只能在指定IP下訪問)
bind 127.0.0.1命令重新命名
修改命令的名稱
rename-command flushall cleanall禁用命令
rename-command flushall ""redis工具
redis-cli 命令列
info/monitor(除錯命令)Redisclient(redis資料庫視覺化工具,不怎麼實用)
http://www.oschina.net/news/53391/redisclient-1-0
redis info命令
以一種易於解釋(parse)且易於閱讀的格式,返回關於 Redis 伺服器的各種資訊和統計數值。
通過給定可選的引數 section ,可以讓命令只返回某一部分的資訊:
內容過多,詳細參考
redis記憶體佔用情況
測試情況:
100萬個鍵值對(鍵是0到999999值是字串“hello world”)在32位作業系統的筆記本上 用了100MB
使用64位的作業系統的話,相對來說佔用的記憶體會多一點,這是因為64位的系統裡指標佔用了8個位元組,但是64位系統也能支援更大的記憶體,所以執行大型的redis服務還是建議使用64位伺服器
Redis例項最多存keys數
理論上Redis可以處理多達2的32次方的keys,並且在實際中進行了測試,每個例項至少存放了2億5千萬的keys
也可以說Redis的儲存極限是系統中的可用記憶體值。
redis優化1
精簡鍵名和鍵值
鍵名:儘量精簡,但是也不能單純為了節約空間而使用不易理解的鍵名。
鍵值:對於鍵值的數量固定的話可以使用0和1這樣的數字來表示,(例如:male/female、right/wrong)
當業務場景不需要資料持久化時,關閉所有的持久化方式可以獲得最佳的效能
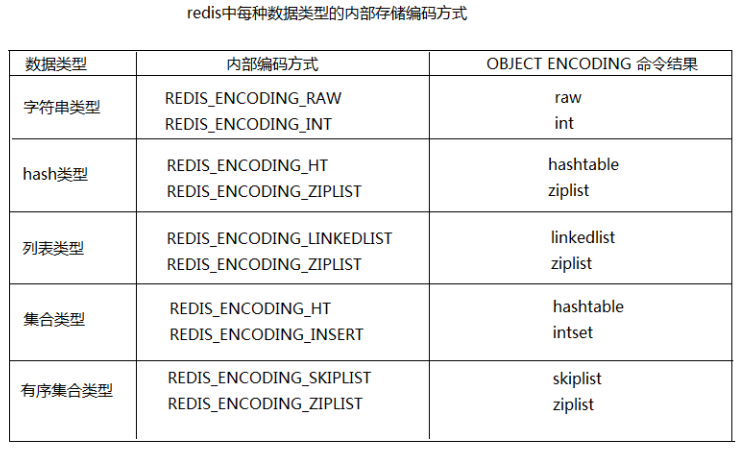
內部編碼優化(大家可以自己瞭解)
redis為每種資料型別都提供了兩種內部編碼方式,在不同的情況下redis會自動調整合適的編碼方式。(如圖所示)
SLOWLOG [get/reset/len]
slowlog-log-slower-than //它決定要對執行時間大於多少微秒(microsecond,1秒 = 1,000,000 微秒)的命令進行記錄
slowlog-max-len //它決定 slowlog 最多能儲存多少條日誌當發現redis效能下降的時候可以檢視下是哪些命令導致的
redis優化2
修改linux核心記憶體分配策略
原因:
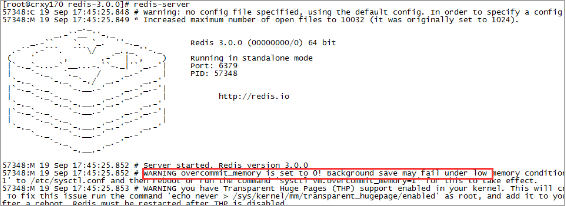
redis在執行過程中可能會出現下面問題
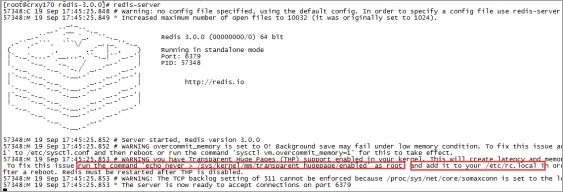
錯誤日誌:
WARNING overcommit_memory is set to 0! Background save may fail under low memory condition. To fix this issue add 'vm.overcommit_memory = 1' to /etc/sysctl.conf and then reboot or run the command 'sysctl vm.overcommit_memory=1'redis在備份資料的時候,會fork出一個子程序,理論上child程序所佔用的記憶體和parent是一樣的,比如parent佔用的記憶體為8G,這個時候也要同樣分配8G的記憶體給child,如果記憶體無法負擔,往往會造成redis伺服器的down機或者IO負載過高,效率下降。所以記憶體分配策略應該設定為 1(表示核心允許分配所有的實體記憶體,而不管當前的記憶體狀態如何)。
記憶體分配策略有三種
可選值:0、1、2。
0, 表示核心將檢查是否有足夠的可用記憶體供應用程序使用;如果有足夠的可用記憶體,記憶體申請允許;否則,記憶體申請失敗,並把錯誤返回給應用程序。
1, 不管需要多少記憶體,都允許申請。
2, 只允許分配實體記憶體和交換記憶體的大小。(交換記憶體一般是實體記憶體的一半)
向/etc/sysctl.conf新增
vm.overcommit_memory = 1 //然後重啟伺服器或者執行
sysctl vm.overcommit_memory=1 //立即生效問題圖示:
redis優化3
關閉Transparent Huge Pages(THP)
THP會造成記憶體鎖影響redis效能,建議關閉
Transparent HugePages :用來提高記憶體管理的效能
Transparent Huge Pages在32位的RHEL 6中是不支援的使用root使用者執行下面命令
echo never > /sys/kernel/mm/transparent_hugepage/enabled把這條命令新增到這個檔案中/etc/rc.local
redis優化4
修改linux中TCP 監聽的最大容納數量
在高併發環境下你需要一個高backlog值來避免慢客戶端連線問題。注意Linux核心默默地將這個值減小到/proc/sys/net/core/somaxconn的值,所以需要確認增大somaxconn和tcp_max_syn_backlog兩個值來達到想要的效果。
echo 511 > /proc/sys/net/core/somaxconn注意:這個引數並不是限制redis的最大連結數。如果想限制redis的最大連線數需要修改maxclients,預設最大連線數為10000。

redis優化5
限制redis的記憶體大小
通過redis的info命令檢視記憶體使用情況
如果不設定maxmemory或者設定為0,64位系統不限制記憶體,32位系統最多使用3GB記憶體。
修改配置檔案中的maxmemory和maxmemory-policy
maxmemory:最大記憶體
maxmemory-policy:記憶體不足時,資料清除策略如果可以確定資料總量不大,並且記憶體足夠的情況下不需要限制redis使用的記憶體大小。如果資料量不可預估,並且記憶體也有限的話,儘量限制下redis使用的記憶體大小,這樣可以避免redis使用swap分割槽或者出現OOM錯誤。
注意:如果不限制記憶體,當實體記憶體使用完之後,會使用swap分割槽,這樣效能較低,如果限制了記憶體,當到達指定記憶體之後就不能新增資料了,否則會報OOM錯誤。可以設定maxmemory-policy,記憶體不足時刪除資料。
拓展
used_memory是Redis使用的記憶體總量,它包含了實際快取佔用的記憶體和Redis自身執行所佔用的記憶體(以位元組(byte)為單位,其中used_memory_human上的資料和used_memory是一樣的值,它以M為單位顯示,僅為了方便閱讀)。
如果一個Redis例項的記憶體使用率超過可用最大記憶體(used_memory >可用最大記憶體),那麼作業系統開始進行記憶體與swap空間交換,把記憶體中舊的或不再使用的內容寫入硬碟上(硬碟上的這塊空間叫Swap分割槽),以便騰出新的實體記憶體給新頁或活動頁(page)使用。
在硬碟上進行讀寫操作要比在記憶體上進行讀寫操作,時間上慢了近5個數量級,記憶體是0.1us(微秒)、而硬碟是10ms(毫秒)。如果Redis程序上發生記憶體交換,那麼Redis和依賴Redis上資料的應用會受到嚴重的效能影響。 通過檢視used_memory指標可知道Redis正在使用的記憶體情況,如果used_memory>可用最大記憶體,那就說明Redis例項正在進行記憶體交換或者已經記憶體交換完畢。管理員根據這個情況,執行相對應的應急措施。
排查方案:
若是在使用Redis期間沒有開啟rdb快照或aof持久化策略,那麼快取資料在Redis崩潰時就有丟失的危險。因為當Redis記憶體使用率超過可用記憶體的95%時,部分資料開始在記憶體與swap空間來回交換,這時就可能有丟失資料的危險。
當開啟並觸發快照功能時,Redis會fork一個子程序把當前記憶體中的資料完全複製一份寫入到硬碟上。因此若是當前使用記憶體超過可用記憶體的45%時觸發快照功能,那麼此時進行的記憶體交換會變的非常危險(可能會丟失資料)。 倘若在這個時候例項上有大量頻繁的更新操作,問題會變得更加嚴重。
通過減少Redis的記憶體佔用率,來避免這樣的問題,或者使用下面的技巧來避免記憶體交換髮生:
1、儘可能的使用Hash資料結構。因為Redis在儲存小於100個欄位的Hash結構上,其儲存效率是非常高的。所以在不需要集合(set)操作或list的push/pop操作的時候,儘可能的使用Hash結構。比如,在一個web應用程式中,需要儲存一個物件表示使用者資訊,使用單個key表示一個使用者,其每個屬性儲存在Hash的欄位裡,這樣要比給每個屬性單獨設定一個key-value要高效的多。 通常情況下倘若有資料使用string結構,用多個key儲存時,那麼應該轉換成單key多欄位的Hash結構。 如上述例子中介紹的Hash結構應包含,單個物件的屬性或者單個使用者各種各樣的資料。Hash結構的操作命令是HSET(key, fields, value)和HGET(key, field),使用它可以儲存或從Hash中取出指定的欄位。
2、設定key的過期時間。一個減少記憶體使用率的簡單方法就是,每當儲存物件時確保設定key的過期時間。倘若key在明確的時間週期內使用或者舊key不大可能被使用時,就可以用Redis過期時間命令(expire,expireat, pexpire, pexpireat)去設定過期時間,這樣Redis會在key過期時自動刪除key。 假如你知道每秒鐘有多少個新key-value被建立,那可以調整key的存活時間,並指定閥值去限制Redis使用的最大記憶體。
3、回收key。在Redis配置檔案中(一般叫Redis.conf),通過設定“maxmemory”屬性的值可以限制Redis最大使用的記憶體,修改後重啟例項生效。也可以使用客戶端命令config set maxmemory 去修改值,這個命令是立即生效的,但會在重啟後會失效,需要使用config rewrite命令去重新整理配置檔案。 若是啟用了Redis快照功能,應該設定“maxmemory”值為系統可使用記憶體的45%,因為快照時需要一倍的記憶體來複制整個資料集,也就是說如果當前已使用45%,在快照期間會變成95%(45%+45%+5%),其中5%是預留給其他的開銷。 如果沒開啟快照功能,maxmemory最高能設定為系統可用記憶體的95%。
當記憶體使用達到設定的最大閥值時,需要選擇一種key的回收策略,可在Redis.conf配置檔案中修改“maxmemory-policy”屬性值。 若是Redis資料集中的key都設定了過期時間,那麼“volatile-ttl”策略是比較好的選擇。但如果key在達到最大記憶體限制時沒能夠迅速過期,或者根本沒有設定過期時間。那麼設定為“allkeys-lru”值比較合適,它允許Redis從整個資料集中挑選最近最少使用的key進行刪除(LRU淘汰演算法)。Redis還提供了一些其他淘汰策略,如下:
volatile-lru: 使用LRU演算法從已設定過期時間的資料集合中淘汰資料。
volatile-ttl:從已設定過期時間的資料集合中挑選即將過期的資料淘汰。
volatile-random:從已設定過期時間的資料集合中隨機挑選資料淘汰。
allkeys-lru:使用LRU演算法從所有資料集合中淘汰資料。
allkeys-random:從資料集合中任意選擇資料淘汰
no-enviction:禁止淘汰資料。通過設定maxmemory為系統可用記憶體的45%或95%(取決於持久化策略)和設定“maxmemory-policy”為“volatile-ttl”或“allkeys-lru”(取決於過期設定),可以比較準確的限制Redis最大記憶體使用率,在絕大多數場景下使用這2種方式可確保Redis不會進行記憶體交換。倘若你擔心由於限制了記憶體使用率導致丟失資料的話,可以設定noneviction值禁止淘汰資料。
redis優化6
Redis是個單執行緒模型,客戶端過來的命令是按照順序執行的,所以想要一次新增多條資料的時候可以使用管道,或者使用一次可以新增多條資料的命令,例如:
Redis應用場景
釋出與訂閱
在更新中保持使用者對資料的對映是系統中的一個普遍任務。Redis的pub/sub功能使用了SUBSCRIBE、UNSUBSCRIBE和PUBLISH命令,讓這個變得更加容易。
程式碼示例:
// 訂閱頻道資料
public static void testSubscribe() {
//連線Redis資料庫
Jedis jedis = new Jedis("192.168.33.130", 6379);
JedisPubSub jedisPubSub = new JedisPubSub() {
// 當向監聽的頻道傳送資料時,這個方法會被觸發
@Override
public void onMessage(String channel, String message) {
System.out.println("收到訊息" + message);
//當收到 "unsubscribe" 訊息時,呼叫取消訂閱方法
if ("unsubscribe".equals(message)) {
this.unsubscribe();
}
}
// 當取消訂閱指定頻道的時候,這個方法會被觸發
@Override
public void onUnsubscribe(String channel, int subscribedChannels) {
System.out.println("取消訂閱頻道" + channel);
}
};
// 訂閱之後,當前程序一致處於監聽狀態,當被取消訂閱之後,當前程序會結束
jedis.subscribe(jedisPubSub, "ch1");
}
// 釋出頻道資料
public static void testPubSub() throws Exception {
//連結Redis資料庫
Jedis jedis = new Jedis("192.168.33.130", 6379);
//釋出頻道 "ch1" 和訊息 "hello redis"
jedis.publish("ch1", "hello redis");
//關閉連線
jedis.close();
}列印結果:

限制網站訪客訪問頻率
進行各種資料統計的用途是非常廣泛的,比如想知道什麼時候封鎖一個IP地址。INCRBY命令讓這些變得很容易,通過原子遞增保持計數;GETSET用來重置計數器;過期屬性expire用來確認一個關鍵字什麼時候應該刪除。
程式碼示例:
//指定Redis資料庫連線的IP和埠
String host = "192.168.33.130";
int port = 6379;
Jedis jedis = new Jedis(host, port);
/**
* 限制網站訪客訪問頻率 一分鐘之內最多訪問10次
*
* @throws Exception
*/
@Test
public void test3() throws Exception {
// 模擬使用者的頻繁請求
for (int i = 0; i < 20; i++) {
boolean result = testLogin("192.168.1.100");
if (result) {
System.out.println("正常訪問");
} else {
System.err.println("訪問受限");
}
}
}
/**
* 判斷使用者是否可以訪問網站
*
* @param ip
* @return
*/
public boolean testLogin(String ip) {
String value = jedis.get(ip);
if (value == null) {
//初始化時設定IP訪問次數為1
jedis.set(ip, "1");
//設定IP的生存時間為60秒,60秒內IP的訪問次數由程式控制
jedis.expire(ip, 60);
} else {
int parseInt = Integer.parseInt(value);
//如果60秒內IP的訪問次數超過10,返回false,實現了超過10次禁止分的功能
if (parseInt > 10) {
return false;
} else {
//如果沒有10次,可以自增
jedis.incr(ip);
}
}
return true;
}列印結果:

監控變數在事務執行時是否被修改
程式碼示例:
// 指定Redis資料庫連線的IP和埠
String host = "192.168.33.130";
int port = 6379;
Jedis jedis = new Jedis(host, port);
/**
* 監控變數a在一段時間內是否被修改,若沒有,則執行事務,若被修改,則事務不執行
*
* @throws Exception
*/
@Test
public void test4() throws Exception {
//監控變數a,在事務執行後watch功能也結束
jedis.watch("a");
//需要資料庫中先有a,並且a的值為字串數字
String value = jedis.get("a");
int parseInt = Integer.parseInt(value);
parseInt++;
System.out.println("執行緒開始休息。。。");
Thread.sleep(5000);
//開啟事務
Transaction transaction = jedis.multi();
transaction.set("a", parseInt + "");
//執行事務
List<Object> exec = transaction.exec();
if (exec == null) {
System.out.println("事務沒有執行.....");
} else {
System.out.println("正常執行......");
}
}列印結果:
變數a沒有被修改時:

變數a被修改時:

各種計數
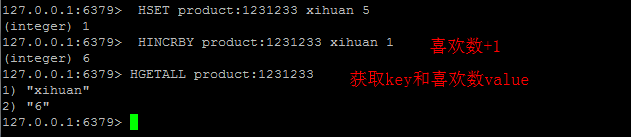
商品維度計數(喜歡數,評論數,鑑定數,瀏覽數,etc)
採用Redis 的型別: Hash. 如果你對redis資料型別不太熟悉,可以參考 http://redis.io/topics/data-types-intro
為product定義個key product:,為每種數值定義hashkey, 譬如喜歡數xihuan
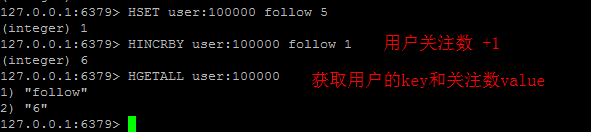
使用者維度計數(動態數、關注數、粉絲數、喜歡商品數、發帖數 等)
使用者維度計數同商品維度計數都採用 Hash. 為User定義個key user:,為每種數值定義hashkey, 譬如關注數follow
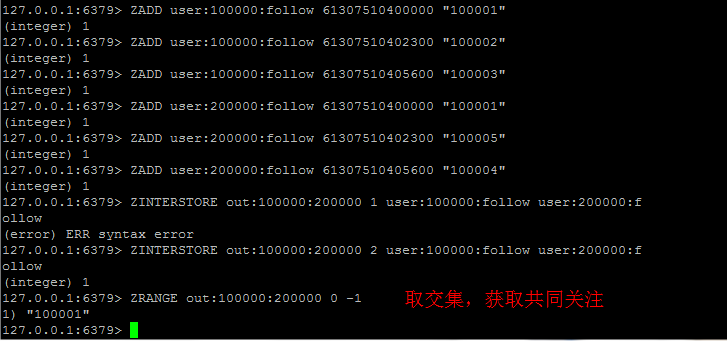
儲存社交關係
譬如將使用者的好友/粉絲/關注,可以存在一個sorted set中,score可以是timestamp,這樣求兩個人的共同好友的操作,可能就只需要用求交集命令即可。
用作快取代替memcached
快取內容示例:(商品列表,評論列表,@提示列表,etc)
相對memcached 簡單的key-value儲存來說,redis眾多的資料結構(list,set,sorted set,hash, etc)可以更方便cache各種業務資料,效能也不亞於memcached。
例如:
RPUSH pagewviews.user: EXPIRE pagewviews.user: 60 //注意要update timeout反spam系統
例如:(評論,釋出商品,論壇發貼,etc)
作為一個電商網站被各種spam攻擊是少不免(垃圾評論、釋出垃圾商品、廣告、刷自家商品排名等),針對這些spam制定一系列anti-spam規則,其中有些規則可以利用redis做實時分析,譬如:1分鐘評論不得超過2次、5分鐘評論少於5次等(更多機制/規則需要結合drools )。 採用sorted set將最近一天使用者操作記錄起來(為什麼不全部記錄?節省memory,全部操作會記錄到log,後續利用hadoop進行更全面分析統計),通過
redis> RANGEBYSCORE user:200000:operation:comment 61307510405600 +inf //獲得1分鐘內的操作記錄
redis> ZADD user:200000:operation:comment 61307510402300 "這是一條評論" //score 為timestamp (integer) 1
redis> ZRANGEBYSCORE user:200000:operation:comment 61307510405600 +inf //獲得1分鐘內的操作記錄列印結果:
1) "這是一條評論"使用者Timeline/Feeds
在逛有個類似微博的欄目我關注,裡面包括關注的人、主題、品牌的動態。redis在這邊主要當作cache使用。
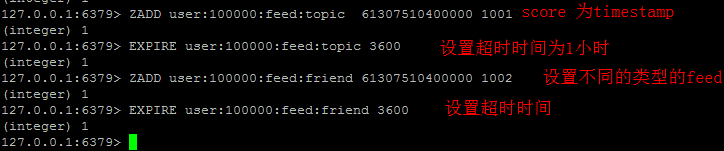
最新列表&排行榜
這裡採用Redis的List資料結構或sorted set 結構, 方便實現最新列表or排行榜 等業務場景。
訊息通知
其實這業務場景也可以算在計數上,也是採用Hash。如下:
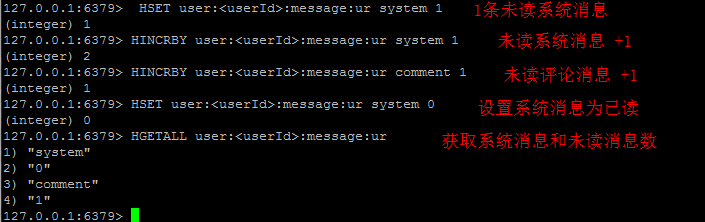
訊息佇列
當在叢集環境時候,java ConcurrentLinkedQueue 就無法滿足我們需求,此時可以採用Redis的List資料結構實現分散式的訊息佇列。
顯示最新的專案列表
Redis使用的是常駐記憶體的快取,速度非常快。LPUSH用來插入一個內容ID,作為關鍵字儲存在列表頭部。LTRIM用來限制列表中的專案數最多為5000。如果使用者需要的檢索的資料量超越這個快取容量,這時才需要把請求傳送到資料庫。
刪除和過濾。
如果一篇文章被刪除,可以使用LREM從快取中徹底清除掉。
排行榜及相關問題
排行榜(leader board)按照得分進行排序。ZADD命令可以直接實現這個功能,而ZREVRANGE命令可以用來按照得分來獲取前100名的使用者,ZRANK可以用來獲取使用者排名,非常直接而且操作容易。
按照使用者投票和時間排序
這就像Reddit的排行榜,得分會隨著時間變化。LPUSH和LTRIM命令結合運用,把文章新增到一個列表中。一項後臺任務用來獲取列表,並重新計算列表的排序,ZADD命令用來按照新的順序填充生成列表。列表可以實現非常快速的檢索,即使是負載很重的站點。
過期專案處理
使用unix時間作為關鍵字,用來保持列表能夠按時間排序。對current_time和time_to_live進行檢索,完成查詢過期專案的艱鉅任務。另一項後臺任務使用ZRANGE...WITHSCORES進行查詢,刪除過期的條目。
特定時間內的特定專案
這是特定訪問者的問題,可以通過給每次頁面瀏覽使用SADD命令來解決。SADD不會將已經存在的成員新增到一個集合。
實時分析
使用Redis原語命令,更容易實施垃圾郵件過濾系統或其他實時跟蹤系統。
佇列
在當前的程式設計中佇列隨處可見。除了push和pop型別的命令之外,Redis還有阻塞佇列的命令,能夠讓一個程式在執行時被另一個程式新增到佇列。你也可以做些更有趣的事情,比如一個旋轉更新的RSS feed佇列。
快取
Redis快取使用的方式與memcache相同。
網路應用不能無休止地進行模型的戰爭,看看這些Redis的原語命令,儘管簡單但功能強大,把它們加以組合,所能完成的就更無法想象。當然,你可以專門編寫程式碼來完成所有這些操作,但Redis實現起來顯然更為輕鬆。
手機驗證碼
使用expire設定驗證碼失效時間
redis既可以作為資料庫來用,也可以作為快取系統來用