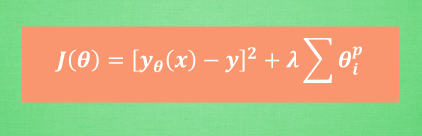18L1和L2正規化(正則化)
阿新 • • 發佈:2019-02-07
為了說明這個標準化的問題,我們以線性擬合數據舉例,當然其他機器學習演算法都可以類似的推廣。
在用線性一次方程擬合數據的時候,我們的訓練誤差可能很低,但是泛化能力比較好。但對於高次方程去擬合數據時,訓練誤差可能很小,但是泛化誤差可能很低。在高次方程中起重要作用的就是那些高次項和其係數,所以我們想要讓這些能力強的項變得不那麼牛,這時候我們加入了懲罰機制,對其引數進行懲罰,就是我們的正則化項啦。
當然正則化項的形式不同,求得的引數效果不一。
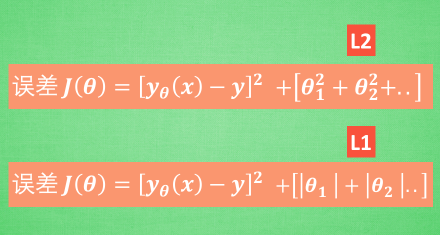
- L1正則化是指權值向量w中各個元素的絕對值之和,通常表示為||w||1
- L2正則化是指權值向量w中各個元素的平方和然後再求平方根(可以看到Ridge迴歸的L2正則化項有平方符號),通常表示為||w||2
一般都會在正則化項之前新增一個係數,Python中用α表示,一些文章也用λ表示。這個係數需要使用者指定。
那新增L1和L2正則化有什麼用?下面是L1正則化和L2正則化的作用,這些表述可以在很多文章中找到。
- L1正則化可以產生稀疏權值矩陣,即產生一個稀疏模型,可以用於特徵選擇
- L2正則化可以防止模型過擬合(overfitting);一定程度上,L1也可以防止過擬合
其實這裡的L1和L2指的是範數。可以統一化進行表示。