
linux核心學習之程序和執行緒
Linux程序、執行緒問題
2010年8月15日,今天研究的是Linux的程序管理,昨天是記憶體定址,感慨頗深啊,《深入理解Linux核心》這本書真是浪得虛名,根本沒有說到問題的本質,一些概念的由來、定義、區別以及聯絡,技術的原理,執行過程,整體結構,各部分銜接等等問題統統沒有說明白,甚至根本沒說,全書都是Linux的資料結構,及各種變數,介面函式,卻根本沒說是什麼,為什麼。對於新手來說簡直是災難,我看完之後發覺什麼都不知道,跟他媽沒看一樣,根本不理解,沒辦法去差別的資料或者網上搜索,在網上Baidu、Google了一天,終於搞明白了Linux的程序、執行緒到底是怎麼回事,現將網上的一些文章加以修改,加入我的理解。可能有些地方不準確,希望大家指正。其實以下基本都是摘自網上的文章,我只是負責整理,原作者不要告我侵權啊。
一.定義
關於程序、輕量級程序、執行緒、使用者執行緒、核心執行緒的定義,這個很容易找到,但是看完之後你可以說你懂了,但實際上你真的明白了麼?
在現代作業系統中,程序支援多執行緒。程序是資源管理的最小單元;而執行緒是程式執行的最小單元。一個程序的組成實體可以分為兩大部分:執行緒集合和資源集合。程序中的執行緒是動態的物件;代表了程序指令的執行。資源,包括地址空間、開啟的檔案、使用者資訊等等,由程序內的執行緒共享。執行緒有自己的私有資料:程式計數器,棧空間以及暫存器。
傳統程序的缺點
現實中有很多需要併發處理的任務,如資料庫的伺服器端、網路伺服器、大容量計算等。一個任務是一個程序,傳統的
a. fork一個子程序的消耗是很大的,fork是一個昂貴的系統呼叫,即使使用現代的寫時複製(copy-on-write)技術。
b. 各個程序擁有自己獨立的地址空間,程序間的協作需要複雜的IPC技術,如訊息傳遞和共享記憶體等。
多執行緒的優缺點
執行緒:其實可以先簡單理解成cpu的一個執行流,指令序列。多支援多執行緒的程式(程序)可以取得真正的並行(parallelism)
輕量級程序LWP
既然稱作輕量級程序,可見其本質仍然是程序,與普通程序相比,LWP與其它程序共享所有(或大部分)邏輯地址空間和系統資源,一個程序可以建立多個LWP,這樣它們共享大部分資源;LWP有它自己的程序識別符號,並和其他程序有著父子關係;這是和類Unix作業系統的系統呼叫vfork()生成的程序一樣的。LWP由核心管理並像普通程序一樣被排程。是支援LWP的典型例子。Linux核心在 2.0.x版本就已經實現了輕量程序,應用程式可以通過一個統一的clone()系統呼叫介面,用不同的引數指定建立輕量程序還是普通程序,通過引數決定子程序和父程序共享的資源種類和數量,這樣就有了輕重之分。在核心中, clone()呼叫經過引數傳遞和解釋後會呼叫do_fork(),這個核內函式同時也是fork()、vfork()系統呼叫的最終實現。
在大多數系統中,LWP與普通程序的區別也在於它只有一個最小的執行上下文和排程程式所需的統計資訊,而這也是它之所以被稱為輕量級的原因。
因為LWP之間共享它們的大部分資源,所以它在某些應用程式就不適用了;這個時候就要使用多個普通的程序了。例如,為了避免記憶體洩漏(a process can be replaced by another one)和實現特權分隔(processes can run under other credentials and have other permissions)。
使用者執行緒
這裡的使用者執行緒指的是完全建立在使用者空間的執行緒庫,使用者執行緒的建立,同步,銷燬,排程完全在使用者空間完成,不需要核心的幫助。因此這種執行緒的操作是極其快速的且低消耗的。
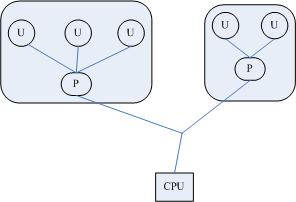
上圖是最初的一個使用者執行緒模型,從中可以看出,程序中包含執行緒,使用者執行緒在使用者空間中實現,核心並沒有直接對使用者執行緒程序排程,核心的排程物件和傳統程序一樣,還是程序本身,核心並不知道使用者執行緒的存在。使用者執行緒之間的排程由在使用者空間實現的執行緒庫實現。
這種模型對應著恐龍書中提到的多對一執行緒模型,其缺點是一個使用者執行緒如果阻塞在系統呼叫中,則整個程序都將會阻塞。
核心執行緒
使用者態執行緒和核心態執行緒;主要的區分就是“誰來管理”執行緒,使用者態是使用者管理,核心態是核心管理(但肯定要提供一些API,例如建立)。
簡單對比兩者優劣勢:
1)可移植性:因為ULT完全在使用者態實現執行緒,因此也就和具體的核心沒有什麼關係,可移植性方面ULT略勝一籌;
2)可擴充套件性:ULT是由使用者控制的,因此擴充套件也就容易;相反,KLT擴充套件就很不容易,基本上只能受制於具體的作業系統核心;
3)效能:由於ULT的執行緒是在使用者態,對應的核心部分還是一個程序,因此ULT就沒有辦法利用多處理器的優勢,而KLT就可以通過排程將執行緒分佈在多個處理上執行,這樣KLT的效能高得多;另外,一個ULT的執行緒阻塞,所有的執行緒都阻塞,而KLT一個執行緒阻塞不會影響其它執行緒。
4)程式設計複雜度:ULT的所有管理工作都要由使用者來完成,而KLT僅僅需要呼叫API介面,因此ULT要比KLT複雜的多。
小結
其實最初根本沒有執行緒的概念,只有程序,一個任務一個程序一個執行流,多工處理機就是多程序。後來提出執行緒的概念,但是要如何去實現,這裡就有很多種實現方法了,文章看到這裡,可以想到兩種實現方法,一種就是上面所說的使用者執行緒的方法,其優缺點上文以簡述;再有就是用輕量級程序去模擬,即我們可以把LWP看成是一個執行緒。就應為這個使得執行緒和程序的概念混淆了,至少我覺得很多人其實根本就不知道,至少我以前不知道,有人說系統排程單位是程序,又有人說是執行緒,其實系統排程的單位一直就沒有改變,只是後來部分執行緒和程序的界限模糊了,至少上文中的使用者執行緒絕對不是排程物件,LWP模擬的執行緒卻是排程物件。
二.Linux執行緒發展
這個對於理解Linux多執行緒很有幫助,可惜《深入理解Linux核心》這本書隻字未提,根本沒講Linux多執行緒的機理,至少我沒看懂。
一直以來, linux核心並沒有執行緒的概念. 每一個執行實體都是一個task_struct結構, 通常稱之為程序. Linux核心在 2.0.x版本就已經實現了輕量程序,應用程式可以通過一個統一的clone()系統呼叫介面,用不同的引數指定建立輕量程序還是普通程序。在核心中, clone()呼叫經過引數傳遞和解釋後會呼叫do_fork(),這個核內函式同時也是fork()、vfork()系統呼叫的最終實現。後來為了引入多執行緒,Linux2.0~2.4實現的是俗稱LinuxThreads的多執行緒方式,到了2.6,基本上都是NPTL的方式了。下面我們分別介紹。
LinuxThreads
注:以下內容主要參考“楊沙洲 (mailto:[email protected]net?subject=Linux 執行緒實現機制分析&[email protected])國防科技大學計算機學院”的“Linux 執行緒實現機制分析”。
linux 2.6以前, pthread執行緒庫對應的實現是一個名叫linuxthreads的lib.這種實現本質上是一種LWP的實現方式,即通過輕量級程序來模擬執行緒,核心並不知道有執行緒這個概念,在核心看來,都是程序。
Linux採用的“一對一”的執行緒模型,即一個LWP對應一個執行緒。這個模型最大的好處是執行緒排程由核心完成了,而其他執行緒操作(同步、取消)等都是核外的執行緒庫函式完成的。
linux上的執行緒就是基於輕量級程序, 由使用者態的pthread庫實現的.使用pthread以後, 在使用者看來, 每一個task_struct就對應一個執行緒, 而一組執行緒以及它們所共同引用的一組資源就是一個程序.但是, 一組執行緒並不僅僅是引用同一組資源就夠了, 它們還必須被視為一個整體.
對此, POSIX標準提出瞭如下要求:
1, 檢視程序列表的時候, 相關的一組task_struct應當被展現為列表中的一個節點;
2, 傳送給這個"程序"的訊號(對應kill系統呼叫), 將被對應的這一組task_struct所共享, 並且被其中的任意一個"執行緒"處理;
3, 傳送給某個"執行緒"的訊號(對應pthread_kill), 將只被對應的一個task_struct接收, 並且由它自己來處理;
4, 當"程序"被停止或繼續時