
基於神經網路的2D攝像頭的手勢識別系統實現(一)
一、手勢識別的分類
若按照攝像頭的種類(2D攝像頭、深度攝像頭)來分,可分為兩類,1)基於2D攝像頭的二維手勢識別 和 2)基於3D攝像頭(如微軟的kinnect)三維手勢識別。早期的手勢識別識別是基於二維彩色影象的識別技術,所謂的二維彩色影象是指通過普通攝像頭拍出場景後,得到二維的靜態影象,然後再通過計算機圖形演算法進行影象中內容的識別。二維的手型識別的只能識別出幾個靜態的手勢動作,而且這些動作必須要提前進行預設好。相比較二維手勢識別,三維手勢識別增加了一個Z軸的資訊,它可以識別各種手型、手勢和動作。三維手勢識別也是現在手勢識別發展的主要方向。不過這種包含一定深度資訊的手勢識別,需要特別的硬體來實現。常見的有通過感測器和光學攝像頭來完成。 手勢識別中最關鍵的包括對手勢動作的跟蹤以及後續的計算機資料處理。關於手勢動作捕捉主要是通過光學和感測器兩種方式來實現。手勢識別推測的演算法,包括模板匹配技術(二維手勢識別技術使用的)、通過統計樣本特徵以及深度學習神經網路技術。本文著重於2D攝像頭的手勢識別。
二、基於2D攝像頭的手勢識別
1. 2D攝像頭的手勢識別分類
2D攝像頭的手勢識別分類又分為:1)靜態手勢識別(手型識別)也稱靜態二維手勢識別,識別的是手勢中最簡單的一類。只能識別出幾個靜態的手勢動作,比如握拳或者五指張開,這種技術只能識別手勢的“狀態”,而不能感知手勢的“持續變化”。說到底是一種模式匹配技術,通過計算機視覺演算法分析影象,和預設的影象模式進行比對,從而理解這種手勢的含義。因此,二維手型識別技術只可以識別預設好的狀態,拓展性差,控制感很弱,使用者只能實現最基礎的人機互動功能。其代表公司是被Google收購的Flutter。使用他家的軟體之後,使用者可以用幾個手型來控制播放器。2)動態手勢識別,仍不含深度資訊,停留在二維的層面上。這種技術比起二維手型識別來說稍複雜一些,不僅可以識別手型,還可以識別一些簡單的二維手勢動作,比如對著攝像頭揮揮手。二維手勢識別擁有了動態的特徵,可以追蹤手勢的運動,進而識別將手勢和手部運動結合在一起的複雜動作。這種技術雖然在硬體要求上和二維手型識別並無區別,但是得益於更加先進的計算機視覺演算法,可以獲得更加豐富的人機互動內容。在使用體驗上也提高了一個檔次,從純粹的狀態控制,變成了比較豐富的平面控制。其代表公司是來自以色列的PointGrab,EyeSight和ExtremeReality。
2. 2D攝像頭的手勢識別的原理
手勢有三個主要特徵:手型,方向,運動軌跡,一個基於視覺手勢識別系統的構成應包括:影象的採集,預處理,特徵提取和選擇,分類器的設計,以及手勢識別。其流程大致如下:
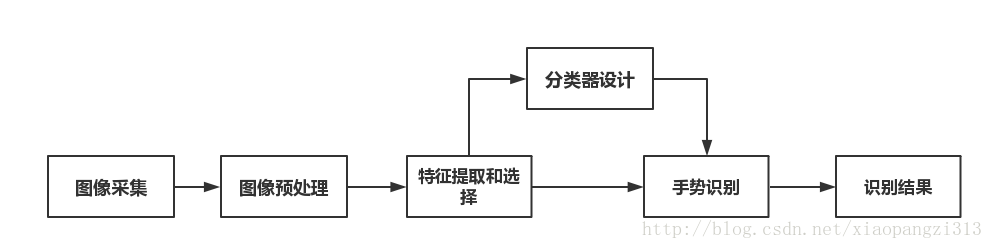
其中有三個步驟是識別系統的關鍵,分別是預處理時手勢的分割,特徵提取和選擇,手勢跟蹤,以及手勢識別演算法。不管是手勢檢測,或者手勢跟蹤,識別,特徵提取和選擇是關鍵:手勢本身具有豐富的形變,運動以及紋理特徵,選取合理的特徵對於手勢的識別至關重要。目前 常用的手勢特徵有:輪廓、邊緣、影象矩、影象特徵向量以及區域直方圖特徵等等。其中,手勢檢測(手勢分割),主要受複雜背景,遮擋,直接光源的亮度變化,外部反射等,常見手部檢測特徵選取有基於膚色
3.基於神經網路2D攝像頭靜態手勢識別實現
本文主要實現基於2D攝像頭的靜態手勢識別系統,由於是靜態所以不用考慮手勢追蹤,重點關注手勢分割、手勢識別兩部分。其中手勢分割採用區域性自適應閾值的影象二值化和高斯膚色模型演算法提取手掌輪廓;手勢識別採用CNN網路進行分類。
3.1 手勢分割演算法實現
區域性自適應閾值的影象二值化
def binaryMask(self, frame, x0, y0, width, height):
# print('use binaryMask model ...')
minValue = 70
# 建立矩形框
cv2.rectangle(frame, (x0, y0), (x0 + width, y0 + height), (0, 255, 0), 1)
roi = frame[y0:y0 + height, x0:x0 + width]
# 獲取灰度影象
gray = cv2.cvtColor(roi, cv2.COLOR_BGR2GRAY)
# 高斯模糊:高斯濾波器中畫素的權重與其距中心畫素的距離成比例
blur = cv2.GaussianBlur(gray, (5, 5), 2)
# 影象的二值化提取目標,動態自適應的調整屬於自己畫素點的閾值,而不是整幅影象都用一個閾值
th3 = cv2.adaptiveThreshold(blur, 255, cv2.ADAPTIVE_THRESH_GAUSSIAN_C, cv2.THRESH_BINARY_INV, 11, 2)
ret, res = cv2.threshold(th3, minValue, 255, cv2.THRESH_BINARY_INV + cv2.THRESH_OTSU)
return res高斯膚色模型
def skinMask(self, frame, x0, y0, width, height):
print('use skin model ...')
# HSV values
low_range = np.array([0, 50, 80])
upper_range = np.array([30, 200, 255])
cv2.rectangle(frame, (x0, y0), (x0 + width, y0 + height), (0, 255, 0), 1)
roi = frame[y0:y0 + height, x0:x0 + width]
hsv = cv2.cvtColor(roi, cv2.COLOR_BGR2HSV)
# 設閾值,去除背景部分,低於這個lower_red的值,影象值變為0,高於這個upper_red的值,影象值變為0
mask = cv2.inRange(hsv, low_range, upper_range)
#腐蝕操作,減少整幅影象的白色區域
mask = cv2.erode(mask, skinkernel, iterations=1)
#膨脹操作,增加影象中的白色區域
mask = cv2.dilate(mask, skinkernel, iterations=1)
# 用高斯分佈權值矩陣與原始影象矩陣做卷積運算
mask = cv2.GaussianBlur(mask, (15, 15), 1)
# cv2.imshow("Blur", mask)
# 影象與運算
res = cv2.bitwise_and(roi, roi, mask=mask)
# color to grayscale
res = cv2.cvtColor(res, cv2.COLOR_BGR2GRAY)
return res3.2 手勢識別CNN神經網路實現
將上面影象分割出來的手勢影象進行CNN訓練,得到比較穩定的網路,然後輸入新的影象進行分類輸出即可。基於keras的CNN網路模型搭建如訓練流程如下:
網路搭建實現
def createCNNModel(self):
self.model = Sequential()
self.model.add(Conv2D(nb_filters, (nb_conv, nb_conv),
padding='valid',
# input_shape=( img_rows, img_cols,img_channels)))
input_shape=(img_channels, img_rows, img_cols))) # theano
convout1 = Activation('relu')
self.model.add(convout1)
self.model.add(Conv2D(nb_filters, (nb_conv, nb_conv)))
convout2 = Activation('relu')
self.model.add(convout2)
self.model.add(MaxPooling2D(pool_size=(nb_pool, nb_pool)))
self.model.add(Dropout(0.5))
self.model.add(Flatten())
self.model.add(Dense(128))
self.model.add(Activation('relu'))
self.model.add(Dropout(0.5))
#11個手勢輸出,1,2,3,4,5,6,7,8,9,10
self.model.add(Dense(nb_classes))
self.model.add(Activation('softmax'))
# sgd = SGD(lr=0.01, decay=1e-6, momentum=0.9, nesterov=True)
self.model.compile(loss='categorical_crossentropy', optimizer='adadelta', metrics=['accuracy'])
# Model summary
self.model.summary()
# Model conig details
self.model.get_config()
from keras.utils import plot_model
plot_model(self.model, to_file='my_model.png', show_shapes=True)
return self.model訓練流程實現
def trainModel(self, train_set_path, weight_name):
self.model = self.createCNNModel()
imlist = []
self.getImgListPath(train_set_path, imlist)
image1 = np.array(Image.open(imlist[0]))
m, n = image1.shape[0:2]
total_images = len(imlist)
img_ndarry_list = []
label_list = np.ones((total_images,), dtype=int)
for index, img_file in enumerate(imlist):
single_img_label =label_dict[os.path.basename(img_file).split('_')[0]]
single_img_array = np.array(Image.open(img_file).convert('L')).flatten()
img_ndarry_list.insert(index, single_img_array)
label_list[index] = single_img_label
img_matrix = np.array(img_ndarry_list, dtype='f')
data, label = shuffle(img_matrix, label_list, random_state=2)
train_data = [data, label]
(X, y) = (train_data[0], train_data[1])
# Split X and y into training and testing sets
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=4)
X_train = X_train.reshape(X_train.shape[0], img_channels, img_rows, img_cols)
X_test = X_test.reshape(X_test.shape[0], img_channels, img_rows, img_cols)
X_train = X_train.astype('float32')
X_test = X_test.astype('float32')
# normalize
X_train /= 255
X_test /= 255
# convert integers to dummy variables (one hot encoding)
Y_train = np_utils.to_categorical(y_train, nb_classes)
Y_test = np_utils.to_categorical(y_test, nb_classes)
# print ( X_train, X_test, Y_train, Y_test)
# print (img_matrix)
hist = self.model.fit(X_train, Y_train, batch_size=batch_size, epochs=nb_epoch,
verbose=1, validation_split=0.2)
# 儲存模型的權重
self.model.save(weight_name)
print('train model success!')4.效果展示
為了方便演示,添加了pyqt4的UI介面,能夠方便實現效能和測試和調優,整體效果入下:
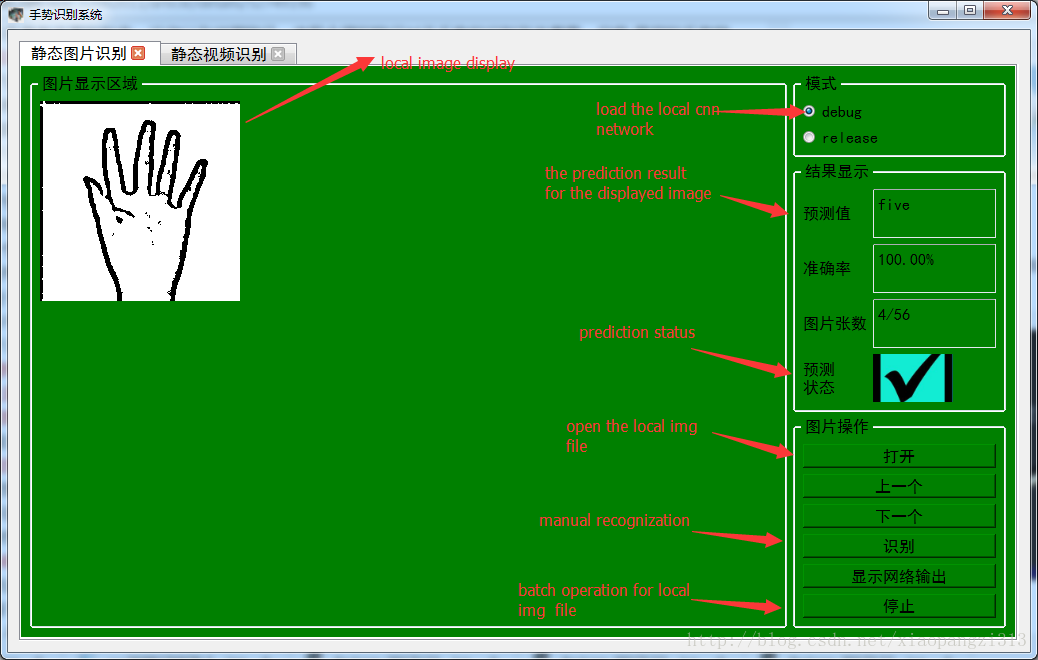
上面這個部分可以用來測試本地資料集的識別率,以下這個部分實現對視訊手勢的實時識別,效果如下:
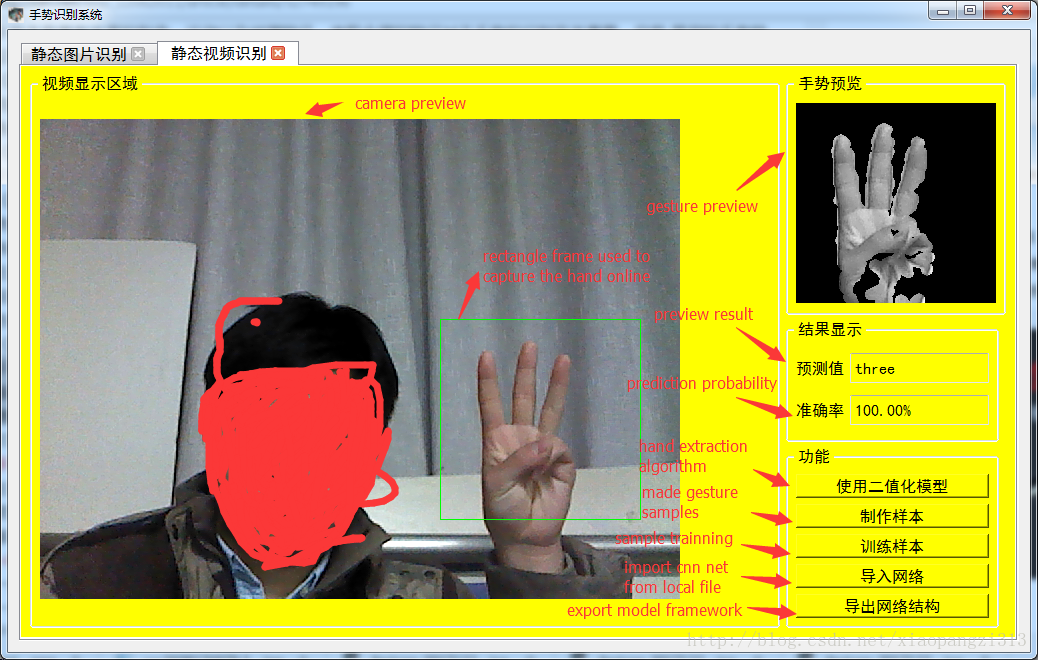
這個UI介面可以實現本地資料集的錄製,手掌分割方法選擇,樣本的訓練,還有直接匯入訓練好的本地網路等功能。
1.程式碼路徑的連結
2.本地訓練好的網路連結
參考文獻:
1.Gesture recognition via CNN neural network implemented in Keras + Tensorflow + OpenCV