
一堆Deep 生成模型:starGAN, UNIT, MUNIT,PWCT
下面要介紹的這幾種生成模型,主要集中在兩種任務當中。一種是風格轉換,另一種是跨域資料之間的轉換(Cross-Domain Image-to-image)。使用的網路結構主要是自動編碼器以及GAN。
StarGAN將一個數據集上面學習到的知識轉移到另一個數據集上面。如圖所示:

輸入單張影象,同時輸入你想要得到的表情類別。於是該演算法就給你生成這樣的圖片。值得注意的是在輸入資料的域(domain)當中不存在這些表情的資料,而這些表情完全是從另一個數據域當中學習到的。
這篇文章最大的特點是使用單個的生成器實現了多個數據域當中的轉換。並且生成的圖片的質量相當的高。具體來說明該網路的優勢。假設你有來至於4個不同的域的資料集,想要實現他們相互之間的轉換,那麼需要至少的訓練12個生成器。然後,這篇文章巧妙的將 域的標籤也作為輸入,於是只需要單個的生成器就可以實現不同資料之間的轉換:
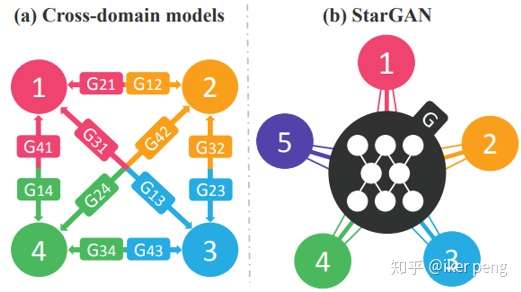
如圖所示,其中的G表示的生成器,其中的不同數字表示的是資料集的域的標號。圖的左邊是傳統的方法,需要12個生成器,而右邊表示的就是是StarGAN的演算法,這裡將域的編號也輸入要網路當中,實現各個資料集之間的轉換隻需要一個生成器。
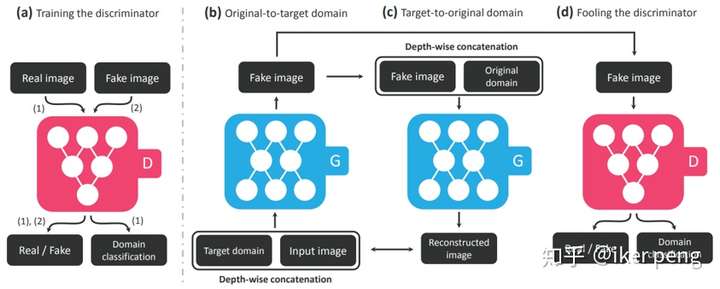
具體來看一下網路的結構。如上圖所示, StarGAN當中還是包括了一個判別器(G)和一個生成器(D)。如圖中的(b)所示,這個G的輸入是一張圖片和一個目標域的編號(實際訓練當中使用的是一個掩碼),由此生成一張圖片Fake image A。那麼圖片A可以從兩個方面來優化調整網路:一方面,把這張圖片加上輸入圖片的域(original domain)作為G的輸入,生成另一張圖片B,這個過程可以看作是一個重構的過程,那麼重構的誤差要最小;另一個方面,生成的騙倒判別器。也是兩個方面要騙倒才好:一方面是真偽,另一方面是域的標籤。這樣損失函式也就很清楚了。1. 對抗誤差L_adv,也就是一般性的GAN的損失函式;2. 重構誤差L_rec,只和G相關,為了增加重構影象的質量;3. 域的分類損失,L_cls。因此,我們可以得到如下的損失函式分別對分類器以及判別器進行訓練更新。
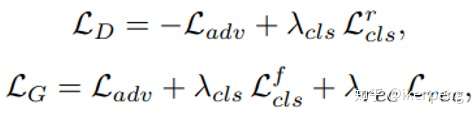
UNIT:無監督的 Image-to-image translation :mingyuliutw/UNIT
這篇文章解決的還是不同資料集之間的生成轉換的問題,作者將其定義為一個知道邊緣概率密度要學習聯合概率密度的問題。顯然這是一個有無限解得問題。那麼為了解決這個問題,作者給出了不同的資料空間共享同一個隱空間的假設,將問題轉化為求解一個隱含空間的問題。文章結合了變分自編碼器和GAN,構建了一個無監督的不同資料集之間的生成網路。得到的效果如圖所示:

該演算法可以實現不同場景的轉換,例如上圖的影象中,實現了從白天到夜晚的場景的轉換。此外類似於季節的變換,交通標誌的變換等等。可以看出該演算法可以對自動駕駛進行攻擊!
顯然很多的任務都可以歸結為一個image-to-image的問題。例如,超解析度的問題,給圖畫上色的問題,影象風格傳輸問題。根據是否存在影象對,這個任務又可以分為監督問題和無監督問題。監督問題相對簡單,就是在配對的情況下,用神經網路擬合出一個對映關係;無監督問題相對比較的困難,但是顯然存在更多的應用場景。而本文的演算法就是一個無監督的問題。

如圖所展示的是該演算法在人物的外貌方面的改變,包括頭髮的顏色,人物的表情,穿戴物品生理特徵等等的改變。人物和所使用的風格處於兩個不同的資料集,不存在配對的圖象對。但是本文的無監督的效果也非常的逼真。那麼來看一下演算法的原理。
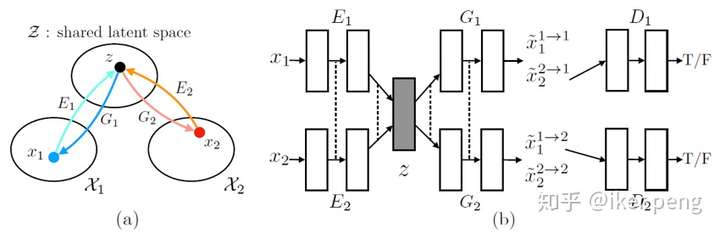
如圖所示,左邊的圖(a)是演算法的核心思想。作者認為來至於兩個不同的資料集的資料可以被對映到同一個隱含空間。於是作者設計了一個包含了VAE的GAN網路,如右邊的(b)所示,來自於不同資料域的資料,通過不同的自編碼網路將資料對映到一個隱含層空間,而從隱含層到不同資料域的重構採用的是兩個不同的對抗網路的生成器部分;對於兩種資料型別的網路,顯然輸出4種不同型別的網路。最後判別器對重構的結果進行判斷,判斷其真實的資料來源,由此來判斷生成的資料的質量,同時通過損失更新網路引數。
因此,整個網路結構由六個部分構成。其損失函式自然應該包括VAE 和GAN 應該有的損失函式,如下面的左邊四項;此外作者還加入了另外兩項,所謂的迴圈一致性(cycle consistency)。
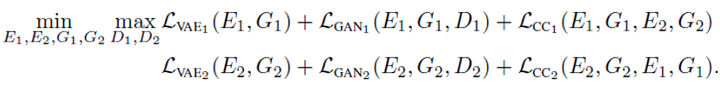
那麼我們重點看看這個迴圈一致性。為什麼要加入這兩項呢?因為如果把G生成的資料再一次作為輸入給到VAE,那麼再一次通過G得到的輸出應該和原圖(生成它的那個圖)保持一致,如其中的兩個負號項所表示的;實際上,這個過程便形成了一個環。當然生成的Z也應該在隱空間當中,如其中的KL散度所表示的。
當然個人覺得其中的第一項多餘~
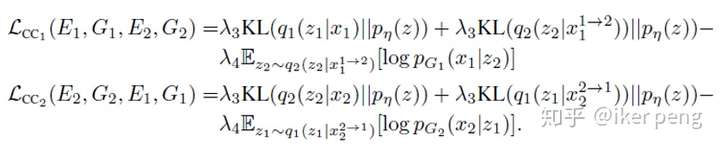
這篇文章實際上就是上一篇文章的擴充套件,這種擴充套件被稱作是多模態資料之間的轉換。UNIT認為不同的資料集可以共享同一個隱空間,而MUNIT更進一步,他認為他們能夠共享的這個空間叫做內容空間(content),而同時他們應該存在著一種彼此差異的空間,他將這個稱作風格空間(style)。如下圖所示:
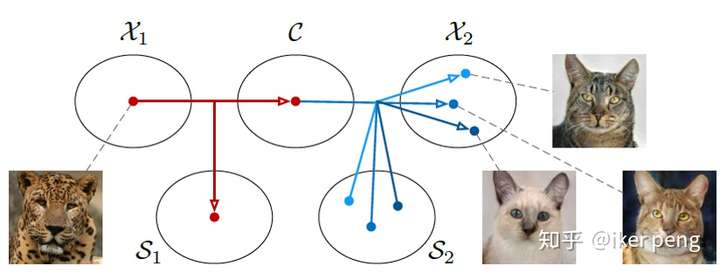
從第一個資料域當中採集到一個樣本為豹,它實際上可以被分解為兩個部分:內容部分以及風格部分。如果我比較完美的完成了上述的分解,那麼,從上述結果的內容空間當中取樣,同時從另一個數據空間構成的風格空間取樣,結合二者進行重構,我們是不是就能夠得生成另一個空間的資料呢?並且這也是一種無監督的演算法,具有更好的應用場景。我們來看一下生成的一些結果:

完成的任務的種類也非常地多實現得效果也非常的好。如上圖所示,MUNIT可以實現從輪廓到著色的過程;同時也可以實現風景影象的季節變換。這裡所生成的影象都是原來的資料庫當中不存在的影象。我們還是從演算法層面看一下是如何實現的。
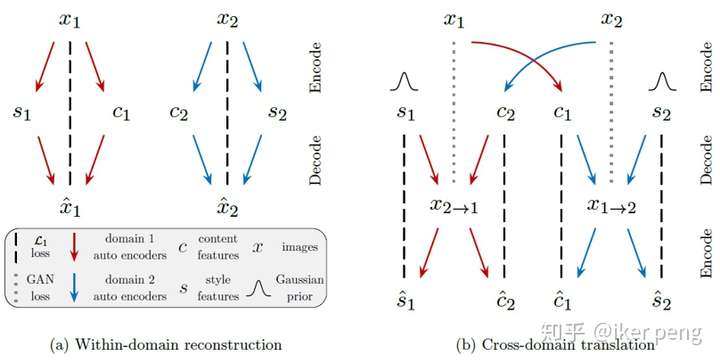
如圖所示,左邊是在同一個資料域當中的分解和重構。這裡同樣還是兩個自編碼器,但是不同以往的是,編碼的過程中通過兩部分網路對映到隱空間,因此隱空間中被分解為內容和風格兩個部分的特徵;因此,在解碼的時候便是從這兩個部分進行重構。再來看右邊的部分,它表示的是在不同的資料域之間的變換。1資料域當中的資料x1分解得到內容部分c1,那麼取樣2資料域當中的風格s2,二者結合重構出一個數據x1->2,那麼應該滿足的約束條件,也就是我們的損失函式是什麼呢?主要應該有兩點:1. 重構出來的資料x1->2 應該儘量的接近2資料域當中的分佈;2. 如果通過再對資料x1->2 進行編碼(也就是輸入到),得到的內容以及風格部分應該儘量的接近輸入。因此我們得到如下的損失函式,最大化函式來更新D網路引數,最小化函式來更新E和G網路。除了隱空間的分解之外,本質上和UNIT沒太大區別 。
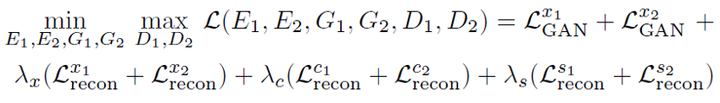
在模型的損失函式當中,除了GAN應該有的(上述表示式當中的前兩項) 對抗損失函式之外,還應該保證影象的重構也非常的準確(上述表示式當中的第三項)。另外,假設我從1資料域使用2的風格生成了一張影象,那麼把該影象再一次將這個圖片輸入到2的編碼器,輸出的內容應該和1資料當中的內容相似,輸出的風格應該和2資料當中的相似(上述表示式當中的最後兩項)。
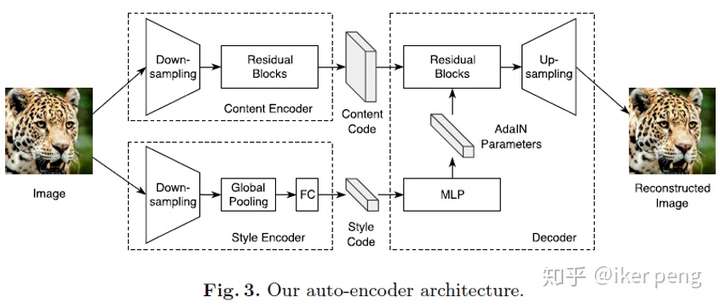
其中,編碼部分通過兩個編碼器對影象的內容和風格分別進行編碼,分別編成64D和8D的向量。而在解碼部分實際上你會發現影象的重構主要還是來自於內容部分,而風格部分通過一個全連線得到256D的向量,這個向量被用來‘指導’影象重構過程當中的上取樣。這個論文,尤其是這個自編碼器和風格傳輸的任務越來越接近了,而且界限也不是那麼清晰了。你可以想像將該圖片之輸入到內容網路部分,使用另一張圖片作為風格網路部分的輸入,這個重構會得到什麼樣的結果呢?如果增加風格網路的權重呢?
如果你早期關注影象的風格傳輸這個領域,那你對於下面的這個結果一定不陌生。圖中的
A表示的是輸入的原始影象,其餘影象的左下角表示的是想要學習到的風格,BCD當中的大圖表示的就是最終的效果。這就是兩三年前的效果,在當時還是引起了不小的轟動的。但是如果我們今天再來看這些結果感覺還是差的比較多的。

如果我們用作者甚至前面幾個任務當中的概念來解釋這個問題,那就是並沒有將內容和風格在隱空間當中分離開來,導致風格的傳輸不僅傳遞了風格,甚至將一些內容傳遞了過去。並且部分的掩蓋了原來的內容。上面的效果感覺就像是一幅模糊不清的油畫。當然,也不乏有很強的藝術氣息。而這篇文章當中的風格傳輸被稱作是:Photorealistic 的風格傳輸。也就是輸出的效果更加的逼真,接近於真實的相片。那我們來看一些生成的結果:

你被嚇倒了嗎? 我是真的被嚇到了。這裡的第一列表示的是想要得到的風格,第二列表示的是內容圖片。而最右邊的那一欄就是風格傳輸的結果。真是被驚豔到了。感慨風格傳輸居然到了這種程度了。那我們還是來看一下是怎麼實現的。
最開始的演算法採用的是Gram矩陣來代替風格的方式,這種方式顯然是比較粗暴的。而後來出現了一些通過匹配輸出和輸入的梯度來微調輸出的結果。而這一篇文章是這樣做的。
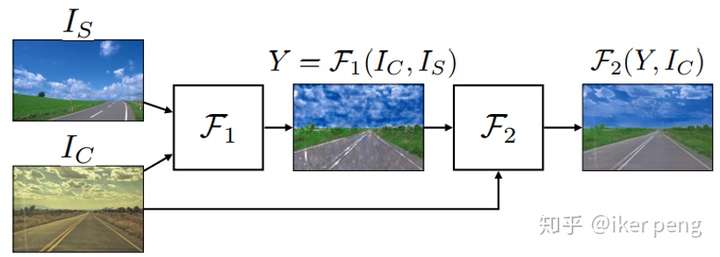
實際上本文就是從NIPS2017的文章WCT上面改進的。文章主要的思想是這樣的:採用一個自編碼器來完成這個風格轉換的任務;其中的編碼器E採用VGG-19並且固定網路引數,然後來訓練一個對稱的解碼器D。損失函式則是保證重構的影象接近於輸入內容Ic,同時對重構的影象提特徵風格要接近風格輸入Is。表示式當中的兩項分別對內容和風格進行約束。
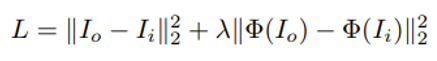
內容部分的約束項不難理解,但是WCT演算法採用什麼來衡量風格呢?該演算法在特徵空間對輸入求解協方差矩陣,實際上仍然類似於Gram矩陣的做法。而本文只有稍微的不同:作者使用unpooling層代替了D當中的上取樣層,此外在對應的層還加入了一個pooling的掩碼。這個掩碼記錄了原來的獲得最大值的位置。並且為了消除原來的人工痕跡,作者還做了後續的平滑網路。
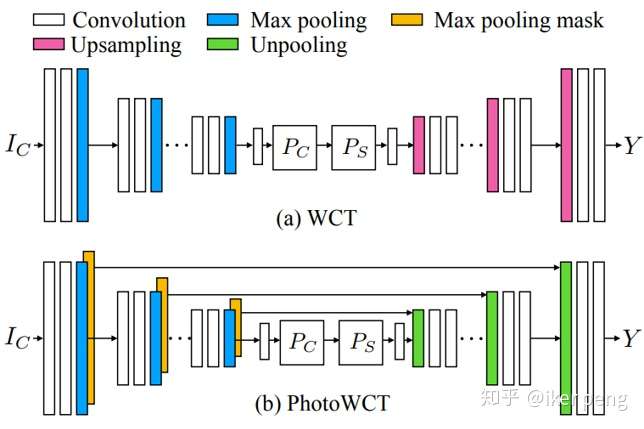
還是先看WCT是怎麼做的:先後輸入風格圖片Is以及內容圖片Ic,通過編碼器E得到對應的特徵Hs和Hc。然後對於內容和風格的特徵圖都求解協方差矩陣,然後構成兩個分別和內容以及風格相關的矩陣Ps 和Pc,然後對內容進行轉換。轉換後的結果Hcs,通過解碼器D進行重構,得到的結果通過上述的損失函式對解碼器D進行更新。具體的其中的各個量表示為:
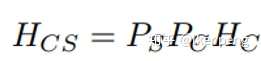
其中:
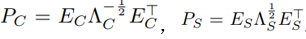
注意其中協方差矩陣的指數的符號。其中的E 表示的就是分別通過
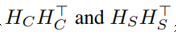
得到的特徵向量構成的矩陣。本質上和最開始的nerual style transfer 當中的Gram矩陣還是一個東西。因此,在損失函式當中,除了要加入重構的影象保持和原圖的相似約束之外,還需要加入對風格的約束。也就是這個類似於Gram矩陣的項:
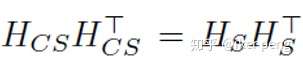
在繼承了WCT的演算法的基礎上,本文還對風格的轉換過程進行了平滑。平滑的目的主要是以下的兩個方面:1. 保證領域內具有相同內容的畫素點保持同樣的風格;2. 平滑後的結果也不能和以上風格轉化的步驟相差太大。平滑的部分主要是為了保證最終的平滑結果和上個階段的輸出風格結果接近,同時也保證相鄰的畫素點的顏色也能夠接近。
以上~