
Linux 設定core dump
最近本人負責專案中的流媒體轉發模組,查了很多資料後選擇了EasyDarwin作為轉發伺服器。編譯原始碼之後伺服器穩定運行了半個月,但是今天突然不能正常轉發了。由於本人Linux新手,所以沒有在Linux下除錯程式碼的經驗,在群主的指導下知道可以設定core檔案來除錯程式碼,於是幾經周折完成了core檔案的設定,特將過程記錄下來。
什麼是coredump
當程式執行的過程中異常終止或崩潰,作業系統會將程式當時的記憶體狀態記錄下來,儲存在一個檔案中,這種行為就叫做Core Dump(中文有的翻譯成“核心轉儲”)。我們可以認為 core dump 是“記憶體快照”,但實際上,除了記憶體資訊之外,還有些關鍵的程式執行狀態也會同時 dump 下來,例如暫存器資訊(包括程式指標、棧指標等)、記憶體管理資訊、其他處理器和作業系統狀態和資訊。core dump 對於程式設計人員診斷和除錯程式是非常有幫助的,因為對於有些程式錯誤是很難重現的,例如指標異常,而 core dump 檔案可以再現程式出錯時的情景。
Linux下開啟coredump
本人使用的Linux發行版是Ubantu 14.04,設定生成coredump檔案的方法如下:
- 開啟core dump功能
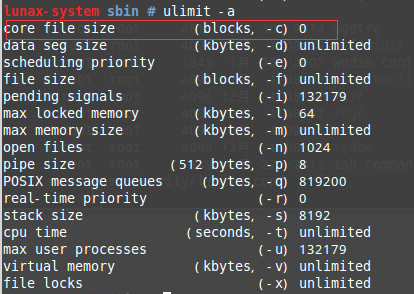
在終端中輸入命令ulimit -c(也可以通過ulimit -a檢視) 輸出的結果為 0,說明預設是關閉 core dump 的,即當程式異常終止時,也不會生成 core dump 檔案。
我們可以使用命令ulimit -c unlimited來開啟 core dump 功能,並且不限制 core dump 檔案的大小; 如果需要限制檔案的大小,將 unlimited 改成你想生成 core 檔案最大的大小,注意單位為 blocks(KB)。
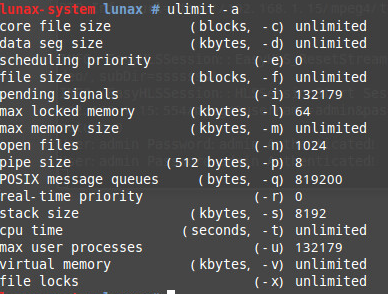
用上面命令只會對當前的終端環境有效,如果想需要永久生效,可以修改檔案/etc/bash.bashrc檔案,新增一行ulimit -c unlimited,然後執行命令source /etc/bash.bashrc生效。此時通過ulimit -a檢視:
(有網友的資料是直接修改/etc/security/limits.conf檔案,但是我測試了沒有效果。) 設定core檔案儲存路徑
預設生成的 core 檔案儲存在可執行檔案所在的目錄下,檔名就為 core,修改此檔名方法有兩種:
1、通過修改/proc/sys/kernel/core_uses_pid檔案可以讓生成 core 檔名是否自動加上 pid 號。命令如下:echo 1 > /proc/sys/kernel/core_uses_pid生成的 core 檔名將會變成 core.pid,其中 pid 表示該程序的 PID。2、還可以通過修改
/proc/sys/kernel/core_pattern來控制生成 core 檔案儲存的位置以及檔名格式。命令可以用echo "/EasyDarwin/corefile-%e-%p-%t" > /proc/sys/kernel/core_pattern設定生成的 core 檔案儲存在/EasyDarwin/目錄下,檔名格式為 “core-命令名-pid-時間戳”。其中:
其中:- %c 轉儲檔案的大小上限
- %e 所dump的檔名
- %g 所dump的程序的實際組ID
- %h 主機名
- %p 所dump的程序PID
- %s 導致本次coredump的訊號
- %t 轉儲時刻(由1970年1月1日起計的秒數)
- %u 所dump程序的實際使用者ID
gdb除錯core檔案
產生了 core 檔案,我們該如何使用該 Core 檔案進行除錯呢?Linux 中可以使用 GDB 來除錯 core 檔案,步驟如下:
- 首先,寫段錯誤程式碼,這個對程式猿來說很簡單,使用 gcc 編譯原始檔,加上 -g 以增加除錯資訊;
#include<stdio.h>
int main()
{
int *p = NULL;
*p = 2;
printf("%d",*p);
return 0;
}編譯:
gcc -g -o test test.c- 執行程式,以使程式異常終止時能生成 core 檔案;
./test- 當core dump 之後,使用命令 gdb program core 來檢視 core 檔案,其中 program為可執行程式名,core 為生成的 core 檔名。
gdb test core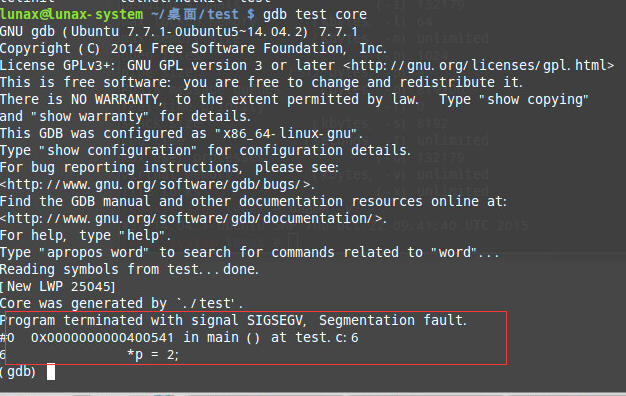
可以看到gdb直接定位到了程式中出錯的具體行。至於具體gdb的使用方法本人也還在摸索之中。需要說明的是,要是EasyDarwin能在錯誤時產生core檔案,需要使用./Built debug命令來編譯源程式。最後感謝EasyDarwin群主的熱心幫助。