
Spark二次排序
阿新 • • 發佈:2019-02-08
Spark當中做二次排序非常簡單,因為有大量的現成函式已經實現了,只需要進行組合運用就好
在這裡進行一下二次排序的總結
如果對兩列或多列同時進行升序或降序排序的話比較容易實現
初始資料

1.兩次升序或降序
val dataset = //your dataset
//1
dataset.map(x => (x._1, x._2)).sortBy(x => x, false).collect.foreach(println)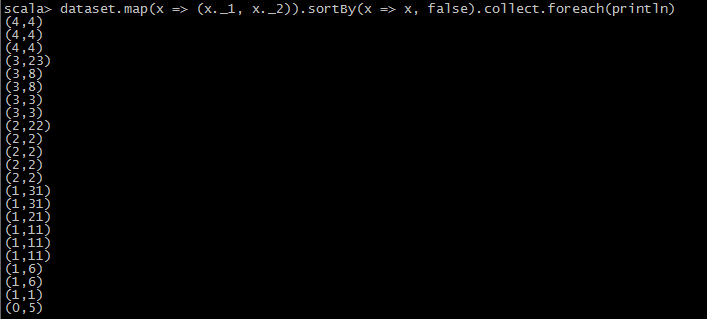 2.一次升序一次降序
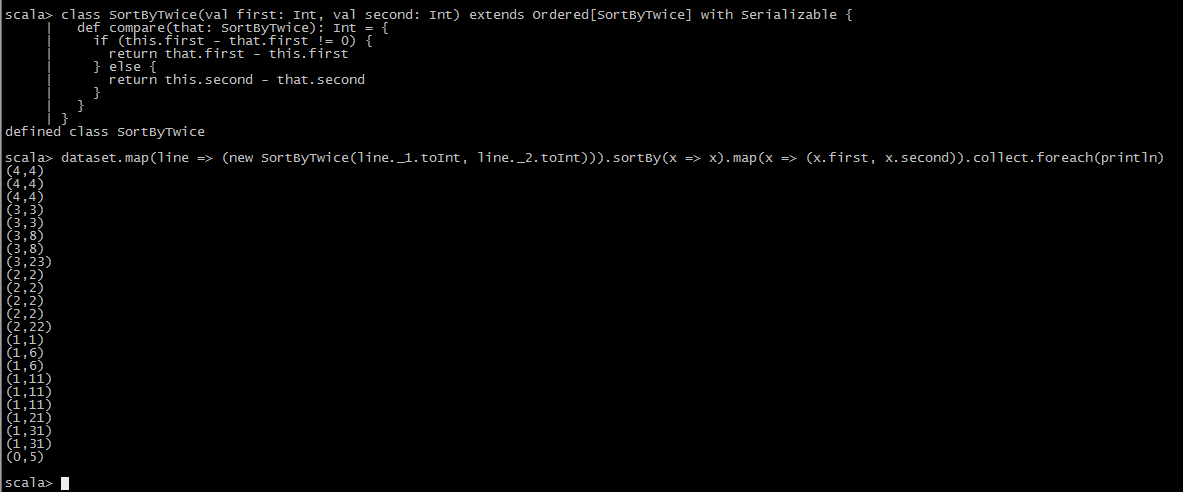
2.一次升序一次降序
class SortByTwice(val first: Int, val second: Int) extends Ordered[SortByTwice] with Serializable { def compare(that: SortByTwice): Int = { if (this.first - that.first != 0) { return that.first - this.first } else { return this.second - that.second } } } val dataset = //your dataset dataset.map(line => (new SortByTwice(line._1.toInt, line._2.toInt))).sortBy(x => x).map(x => (x.first, x.second)).collect.foreach(println)
3.通過groupBy進行二次排序 也有一種情況是需要將Key進行groupBy的Key,Value二次排序
val dataset = //your dataset
dataset.groupByKey.map(x => (x._1, x._2.toList.sortWith(_ > _))).collect.foreach(println)