
python簡單爬蟲程式碼,python入門
阿新 • • 發佈:2019-02-08
python爬取慕課網首頁課程標題與內容介紹
效果圖:
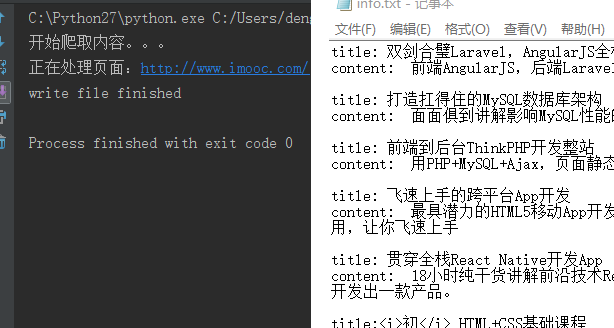
思路:
獲取頁面內容存入html –>
利用正則表示式獲取所有課程塊的div盒子存入everydiv –>
在每個課程塊中抓取標題與介紹存入列表classinfo –>
將列表存入info.txt檔案中 –>
最後檢查抓取到的內容
知識點:
1. re 模組(Regular Expression 正則表示式)提供各種正則表示式的匹配操作,適合文字解析、複雜字串分析和資訊提取時使用
2. Requests ,基於 urllib,但比 urllib 更加方便。 自動的把返回資訊有Unicode解碼,且自動儲存返回內容,所以你可以讀取多次
3. sys模組包括了一組非常實用的服務,內含很多函式方法和變數,用來處理Python執行時配置以及資源,從而可以與前當程式之外的系統環境互動
python原始碼 即粘即用
#-*_coding:utf8-*-
import requests
import re
import sys
reload(sys)
sys.setdefaultencoding("utf-8")
class func(object):
def __init__(self):
print u'開始爬取內容。。。'
#getsource獲取網頁原始碼
def getsource(self,url):
html = requests.get(url)
#print str(html.text) 可以在此列印,來檢查是否抓到內容 如果您有什麼意見或建議,歡迎留言……^.^