
深度學習--為什麼要深?
深度學習–為什麼要深?
一、深度與模組化
對於一個分類的問題的簡化,我們可以先訓練一個Basic classfier,然後將其共享給following classfier,通過多層的分類器進行特徵的提取,用較少的資料就可以訓練好網路。而在deep的模型當中,Basic classfier是由神經網路自己學到的,然後通過更多層的網路可以使得classfier逐漸學到更加深層次的特徵。這就是deep network能夠work的原因。
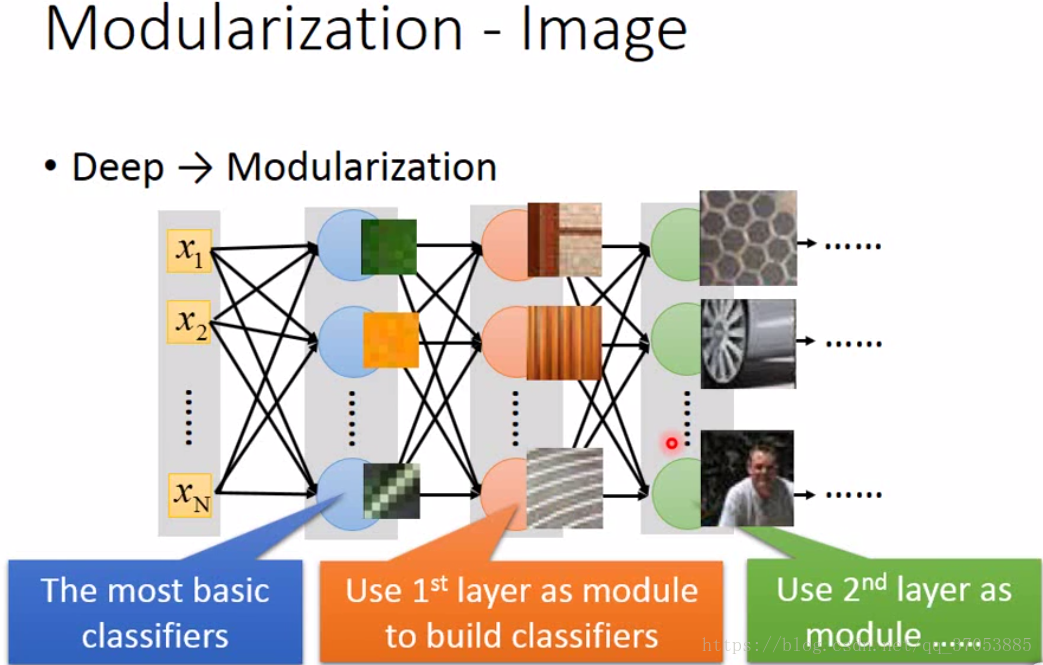
二、模組化與語音識別
語音識別的大致步驟:
①將聲音訊號的特徵轉化為狀態資訊(即對應標籤)。
②將狀態轉化成音素
③將音素轉化成為文字
④考慮同音異字的問題
傳統方法:
HMM-GMM,每一個音素都有自己獨立的分佈,找出所有音素的分佈,然後根據條件概率求出所給的資料屬於哪一個音素。
DNN:
所有的狀態都共用一個DNN。訓練時DNN會根據訓練資料來學習人所發出的聲音時的舌頭位置,然後根據不同的舌頭位置將發出聲音對映到不同的特徵空間從而達到分類的目的。
相比於傳統的語音識別方法,DNN可以利用同一組的檢測器來識別不同的語音,做到了模組化,使得引數的使用更加有效率。
Universality Theorem指出:對於所有的函式
三、端到端的學習
通過一個較為複雜的function將多個simple function組合在一起,端到端的網路可以自動地學習到每一個simple function應該完成的任務。
在傳統的語音識別
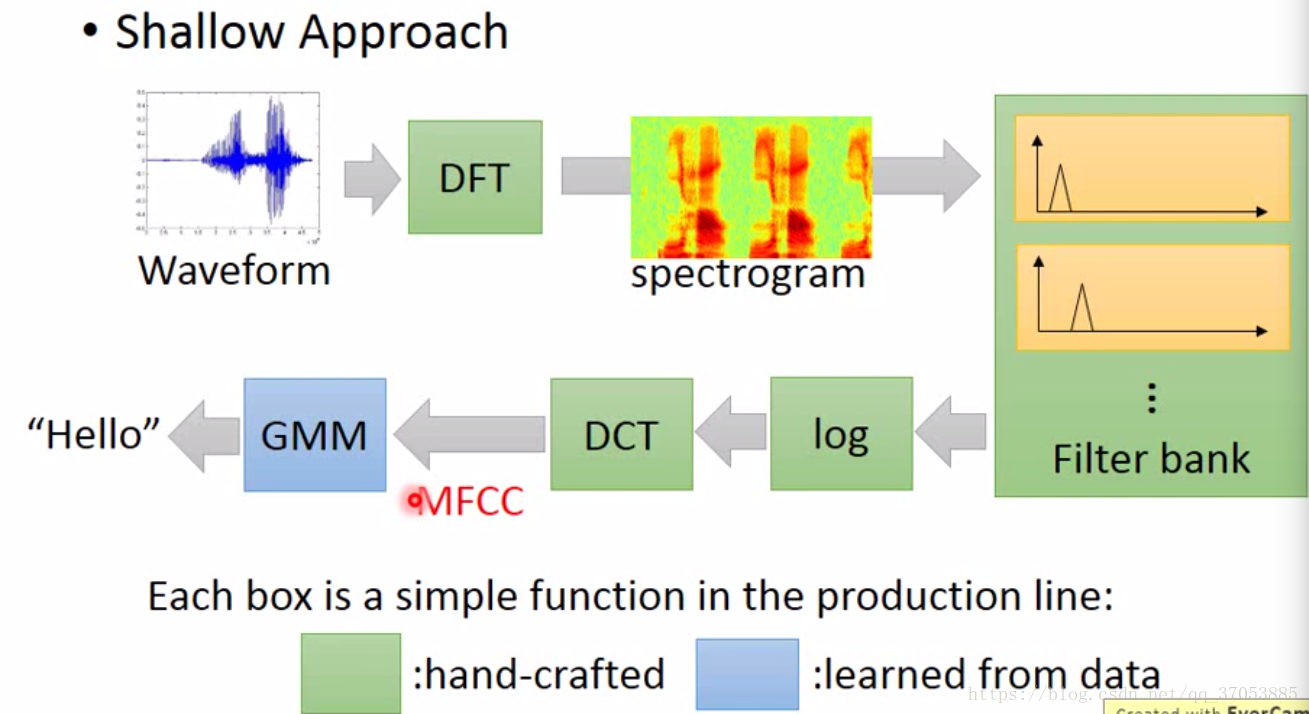
圖片中只有GMM是需要通過訓練資料進行訓練的,其餘均為根據先驗的經驗來進行設計。
而在深度學習中的語音識別的架構如下圖所示:
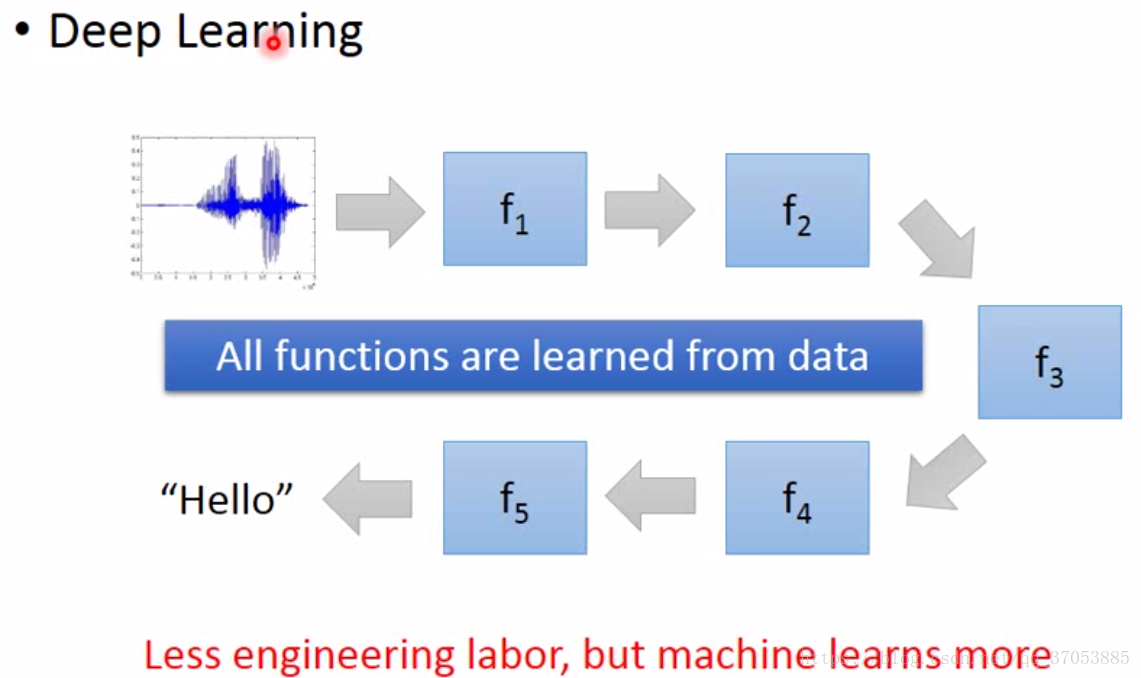
每個函式都可以通過資料來進行訓練,學習到函式中的引數。在影象識別中,端到端相對於傳統方法的優勢與語音識別類似。
四、深度可以完成複雜的任務
①處理相似的輸入,但不同的輸出問題

②處理不同的輸入,但相似的輸出問題

深度學習可以通過多個layer的轉換學習更高維度的特徵來解決更加複雜的任務。