七月演算法機器學習筆記6 -- 工作流程與模型優化
阿新 • • 發佈:2019-02-08
這套筆記是跟著七月演算法四月機器學習班的學習而記錄的,主要記一下我再學習機器學習的時候一些概念比較模糊的地方,具體課程參考七月演算法官網:http://www.julyedu.com/
特徵工程總結
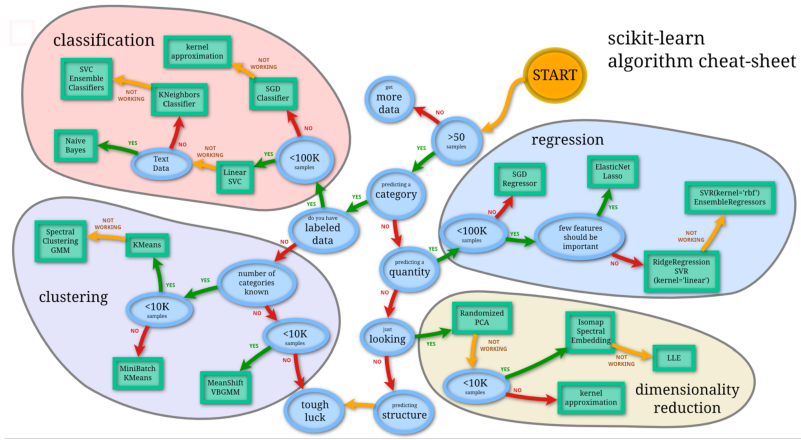
模型選擇
- 沒有那種模型是萬能的,在特定情況下選擇適合的模型
對這幅圖做如下解釋
從start開始,先看資料的訓練樣本
在資料樣本比較小的情況下,需要新增更多樣本或放棄機器學習,用人工規則處理。
當樣本足夠時:並且是連續值問題,採用迴歸方法解決。
果是離散樣本分類,則使用分類模型。當分類樣本數量不大,用線性SVM解決,如果是文字資料分類,使用樸素貝葉斯; 如果不是,使用LR或SVM等。如果樣本很大,用SVM就很難,它收斂時間非常長,這樣,使用隨機梯度下降或核估計方法。
如果是迴歸問題:
在樣本資料非常小的情況下,採用線性方法,如果樣本資料足夠,使用隨機梯度下降等方法
如果樣本維度很高,使用降維方法(無監督學習)
如果無標籤,使用聚類方法。
已知模型,選擇引數
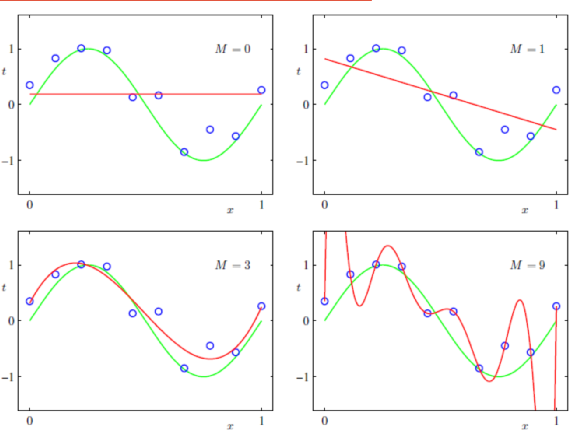
需要考慮引數和次數
- 引數選擇方法:
將資料劃分
70% 訓練集,用於建模
20% 交叉驗證, 引數選擇
10% 測試集, 效果的評估
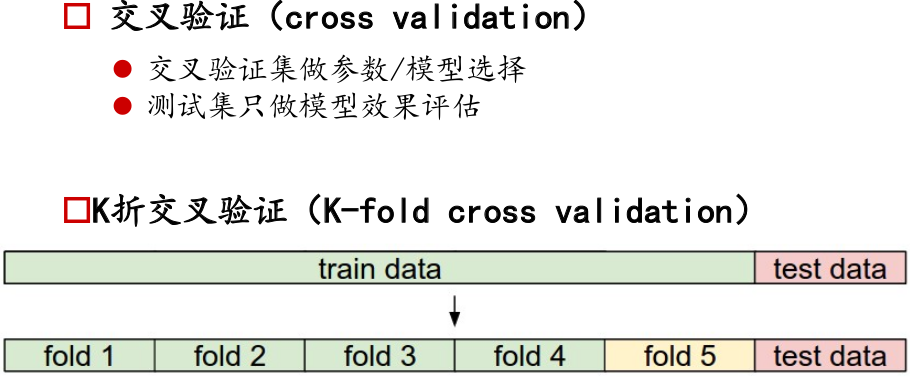
K折交叉驗證,
將訓練集分為k個部分,輪番用其中某一折作為驗證集,前面其他作為訓練集。每折用不同測模型,用驗證集驗證。
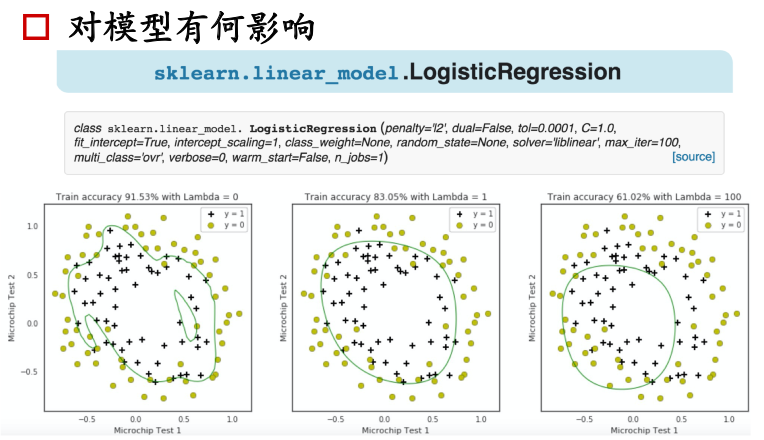
模型引數含義
超引數的選取
模型效果優化
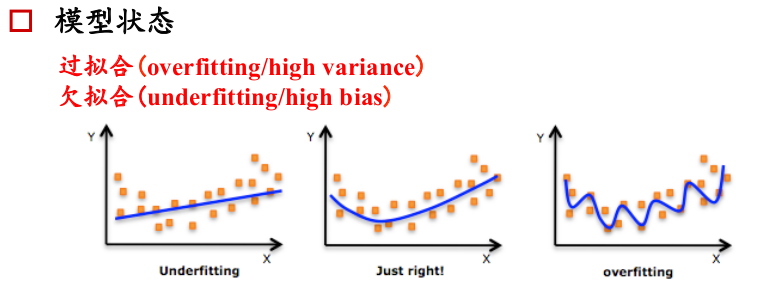
過擬合:高波動
欠擬合:高偏差
工程判定模型處於什麼狀態:學習曲線
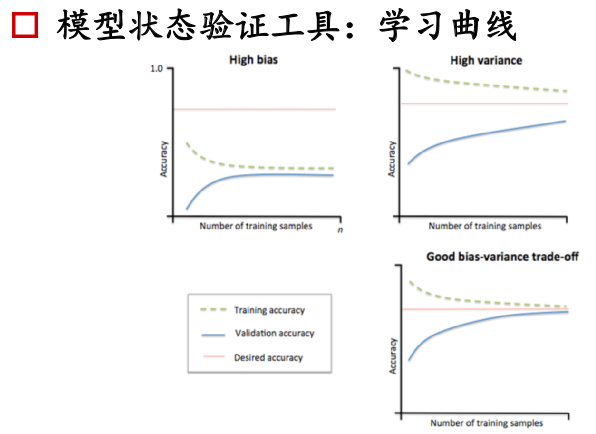
橫座標:不同量的訓練樣本
縱座標:準確度。
實線表示交叉驗證集的準確度,


對錯分樣本的處理

模型融合:比如,不同模型一起投票


bagging每次不用全部的資料集。用不同模型判別(比如n個模型給的結果取多數的判定結果)。減小波動


Adboost給分錯的樣本更高的權重,努力學習錯分樣本。