
Java分散式爬蟲Nutch教程——匯入Nutch工程,執行完整爬取
在使用本教程之前,需要滿足條件:
- 1)有一臺Linux或Linux虛擬機器
- 2)安裝JDK(推薦1.7)
- 3)安裝Apache Ant
下載Nutch原始碼:
安裝IDE:
轉換:
Nutch原始碼是用ant進行構建的,需要轉換成eclipse工程才可以匯入IDE正確使用,Intellij和Netbeans都可以支援ecilpse工程。
解壓下載的apache-nutch-1.9-src.zip,得到資料夾apache-nutch-1.9。
在執行轉換之前,我們先修改一下ivy中的一個源,將它改為開源中國的映象,否則轉換的過程會非常緩慢。(ant原始碼中並沒有附帶依賴jar包,ivy負責從網上自動下載jar包)。
修改apache-nutch-1.9資料夾中的ivy/ivysettings.xml:
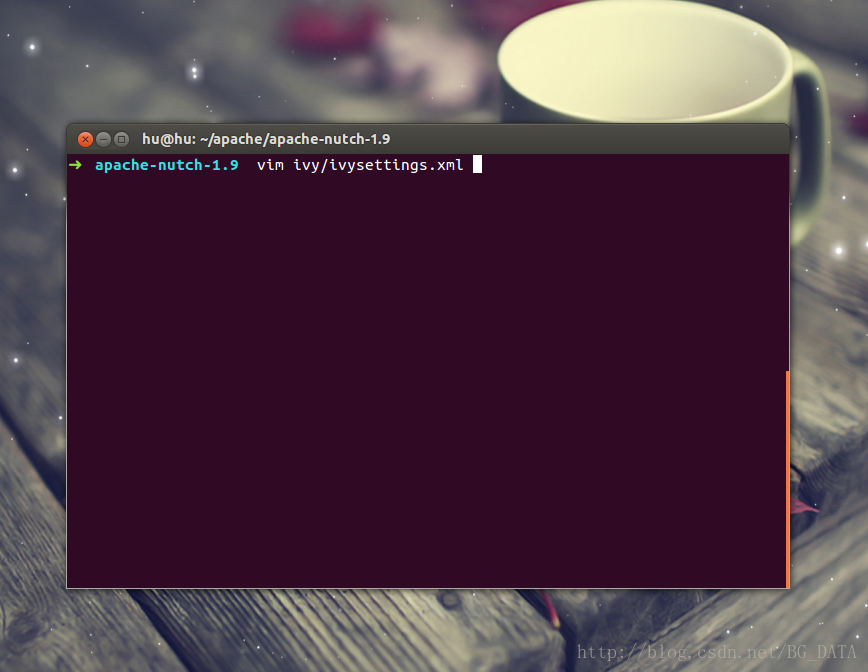
找到:
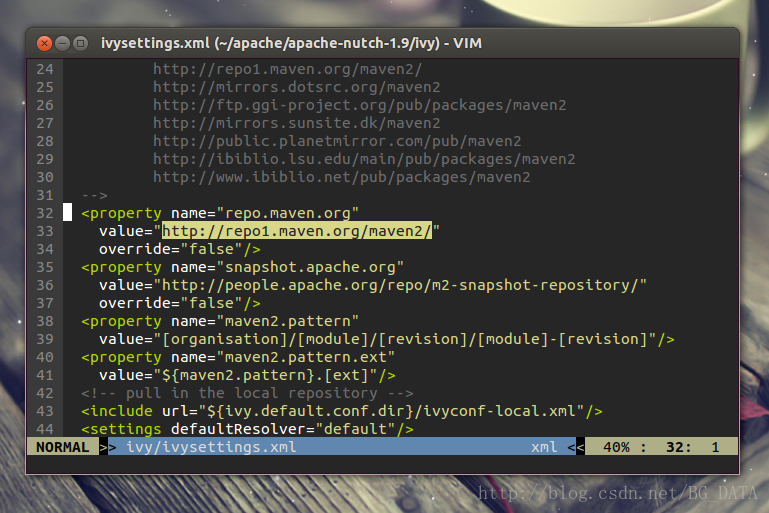
將value修改為http://maven.oschina.net/content/groups/public/ ,修改後:
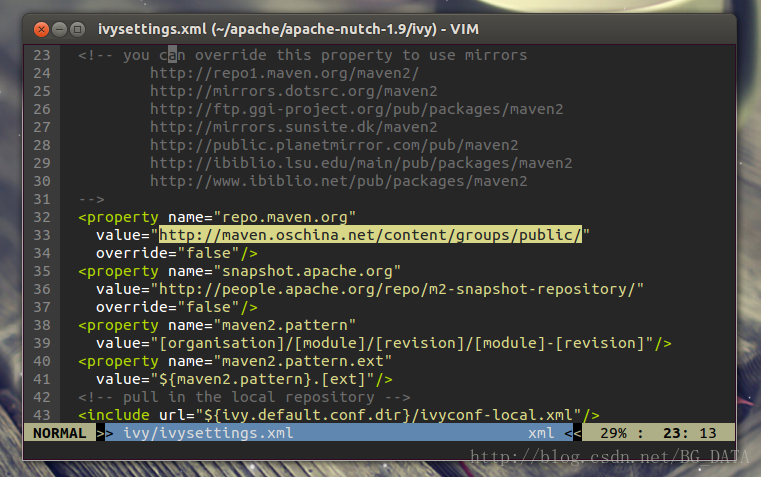
儲存並退出,保證當前目錄為apache-nutch-1.9,執行命令:
然後耐心等待,這個過程ant會根據ivy從中心倉庫下載各種依賴jar包,可能要十幾分鍾。

-verbose引數加上之後可以看到ant過程的詳細資訊。
10分鐘左右,轉換成功:

開啟Intellij, File -> Import Project ->選擇apache-nutch-1.9資料夾,確定後選擇Import project from external model(Eclipse)
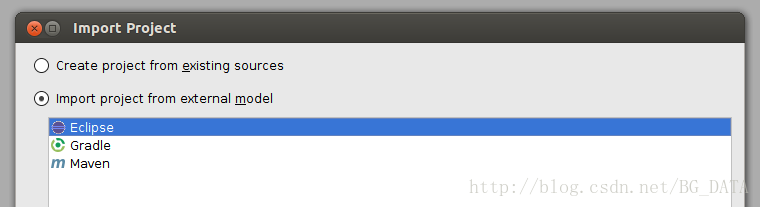
一直點選next到結束。成功將專案匯入Intellij:

原始碼匯入工程後,並不能執行完整的爬取。Nutch將爬取的流程切分成很多階段,每個階段分別封裝在一個類的main函式中。在外面通過Linux Shell呼叫這些main函式,來完整爬取的流程。我們在後續教程中會對流程排程做一個詳細的說明。
下面我們來執行Nutch中最簡單的流程:Inject。我們知道爬蟲在初始階段,是需要人工給出一個或多個url,作為起始點(廣度遍歷樹的樹根)。Inject的作用,就是把使用者寫在檔案裡的種子(一行一個url,是TextInputFormat),插入到爬蟲的URL管理檔案(crawldb,是SequenceFile)中。
從src資料夾中找到org.apache.nutch.crawl.Injector類:

在閱讀Nutch原始碼的過程中,最重要的就是找到每個類的main函式:
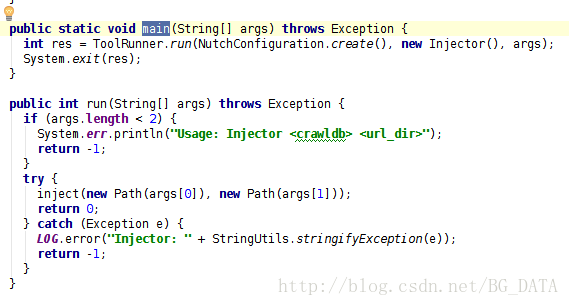
可以看到,main函式其實是利用ToolRunner,執行了run(String[] args)。這裡ToolRunner.run會從第二個引數(new Injector())這個物件中,找到run(String[] args)這個方法執行。
從run方法中可以看出來,String[] args需要有2個引數,第一個引數表示爬蟲的URL管理資料夾(輸出),第二個引數表示種子資料夾(輸入)。對hadoop中的map reduce程式來說,輸入資料夾是必須存在的,輸出資料夾應該不存在。我們建立一個資料夾 /tmp/urls,來存放種子檔案(作為輸入)。

在seed.txt中加入一個種子URL
指定一個資料夾/tmp/crawldb來作為URL管理資料夾(輸出)
有一種簡單的方法來指定args,直接在main函式下加一行:

執行這個類,我們會發現報錯了(下面只給了錯誤的一部分):