
最大似然估計(like-hood)
給定一個概率分佈 ,假定其概率密度函式(連續分佈)或概率聚集函式(離散分佈)為
,假定其概率密度函式(連續分佈)或概率聚集函式(離散分佈)為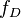 ,以及一個分佈引數
,以及一個分佈引數 ,我們可以從這個分佈中抽出一個具有
,我們可以從這個分佈中抽出一個具有 個值的取樣
個值的取樣 ,通過利用,我們就能計算出其概率:
,通過利用,我們就能計算出其概率:
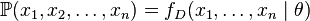
但是,我們可能不知道的值,儘管我們知道這些取樣資料來自於分佈。那麼我們如何才能估計出呢?一個自然的想法是從這個分佈中抽出一個具有個值的取樣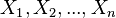 ,然後用這些取樣資料來估計.
,然後用這些取樣資料來估計.
一旦我們獲得,我們就能從中找到一個關於的估計。最大似然估計會尋找關於的最可能的值(即,在所有可能的取值中,尋找一個值使這個取樣的“可能性”最大化)。這種方法正好同一些其他的估計方法不同,如的非偏估計,非偏估計未必會輸出一個最可能的值,而是會輸出一個既不高估也不低估的
要在數學上實現最大似然估計法,我們首先要定義似然函式:
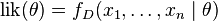
並且在的所有取值上,使這個函式最大化。這個使可能性最大的 值即被稱為的最大似然估計。
值即被稱為的最大似然估計。
注意
- 這裡的似然函式是指
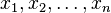 不變時,關於的一個函式。
不變時,關於的一個函式。 - 最大似然估計函式不一定是惟一的,甚至不一定存在。
例子
離散分佈,離散有限引數空間
考慮一個拋硬幣的例子。假設這個硬幣正面跟反面輕重不同。我們把這個硬幣拋80次(即,我們獲取一個取樣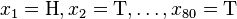 並把正面的次數記下來,正面記為H,反面記為T)。並把丟擲一個正面的概率記為
並把正面的次數記下來,正面記為H,反面記為T)。並把丟擲一個正面的概率記為 ,丟擲一個反面的概率記為
,丟擲一個反面的概率記為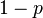 (因此,這裡的即相當於上邊的)。假設我們丟擲了49個正面,31個反面,即49次H,31次T。假設這個硬幣是我們從一個裝了三個硬幣的盒子裡頭取出的。這三個硬幣丟擲正面的概率分別為
(因此,這裡的即相當於上邊的)。假設我們丟擲了49個正面,31個反面,即49次H,31次T。假設這個硬幣是我們從一個裝了三個硬幣的盒子裡頭取出的。這三個硬幣丟擲正面的概率分別為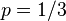
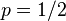 ,
, .這些硬幣沒有標記,所以我們無法知道哪個是哪個。使用最大似然估計,通過這些試驗資料(即取樣資料),我們可以計算出哪個硬幣的可能性最大。這個似然函式取以下三個值中的一個:
.這些硬幣沒有標記,所以我們無法知道哪個是哪個。使用最大似然估計,通過這些試驗資料(即取樣資料),我們可以計算出哪個硬幣的可能性最大。這個似然函式取以下三個值中的一個:
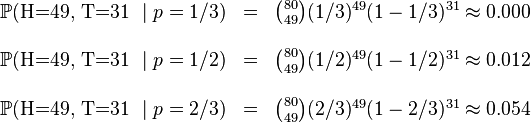
我們可以看到當 時,似然函式取得最大值。這就是的最大似然估計。
時,似然函式取得最大值。這就是的最大似然估計。
離散分佈,連續引數空間
現在假設例子1中的盒子中有無數個硬幣,對於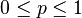 中的任何一個,
都有一個丟擲正面概率為的硬幣對應,我們來求其似然函式的最大值:
中的任何一個,
都有一個丟擲正面概率為的硬幣對應,我們來求其似然函式的最大值:
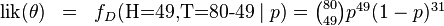
其中. 我們可以使用微分法來求最值。方程兩邊同時對取微分,並使其為零。
![\begin{matrix}0 & = & \frac{d}{dp} \left( \binom{80}{49} p^{49}(1-p)^{31} \right) \\ & & \\ & \propto & 49p^{48}(1-p)^{31} - 31p^{49}(1-p)^{30} \\ & & \\ & = & p^{48}(1-p)^{30}\left[ 49(1-p) - 31p \right] \\\end{matrix}](https://upload.wikimedia.org/math/f/4/3/f43c984e21445732edf403445fe32ea9.png)

其解為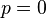 ,
,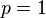 ,以及
,以及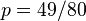
(因為和這兩個解會使可能性為零)。因此我們說最大似然估計值為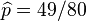 .
.
這個結果很容易一般化。只需要用一個字母 代替49用以表達伯努利試驗中的被觀察資料(即樣本)的“成功”次數,用另一個字母代表伯努利試驗的次數即可。使用完全同樣的方法即可以得到最大似然估計值:
代替49用以表達伯努利試驗中的被觀察資料(即樣本)的“成功”次數,用另一個字母代表伯努利試驗的次數即可。使用完全同樣的方法即可以得到最大似然估計值:
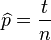
對於任何成功次數為,試驗總數為的伯努利試驗。
連續分佈,連續引數空間
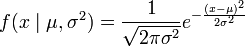
現在有個正態隨機變數的取樣點,要求的是一個這樣的正態分佈,這些取樣點分佈到這個正態分佈可能性最大(也就是概率密度積最大,每個點更靠近中心點),其個正態隨機變數的取樣的對應密度函式(假設其獨立並服從同一分佈)為:
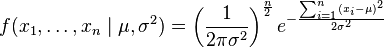
或:
 ,
,
這個分佈有兩個引數: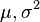 .有人可能會擔心兩個引數與上邊的討論的例子不同,上邊的例子都只是在一個引數上對可能性進行最大化。實際上,在兩個引數上的求最大值的方法也差不多:只需要分別把可能性
.有人可能會擔心兩個引數與上邊的討論的例子不同,上邊的例子都只是在一個引數上對可能性進行最大化。實際上,在兩個引數上的求最大值的方法也差不多:只需要分別把可能性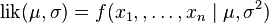 在兩個引數上最大化即可。當然這比一個引數麻煩一些,但是一點也不復雜。使用上邊例子同樣的符號,我們有
在兩個引數上最大化即可。當然這比一個引數麻煩一些,但是一點也不復雜。使用上邊例子同樣的符號,我們有 .
.
最大化一個似然函式同最大化它的自然對數是等價的。因為自然對數log是一個連續且在似然函式的值域內嚴格遞增的上凸函式。[注意:可能性函式(似然函式)的自然對數跟資訊熵以及Fisher資訊聯絡緊密。]求對數通常能夠一定程度上簡化運算,比如在這個例子中可以看到:
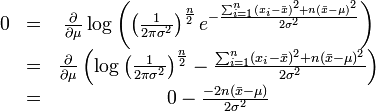
這個方程的解是 .這的確是這個函式的最大值,因為它是
.這的確是這個函式的最大值,因為它是 裡頭惟一的一階導數等於零的點並且二階導數嚴格小於零。
裡頭惟一的一階導數等於零的點並且二階導數嚴格小於零。
同理,我們對 求導,並使其為零。
求導,並使其為零。
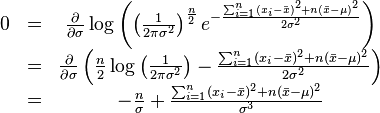
這個方程的解是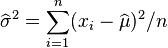 .
.
因此,其關於的最大似然估計為:
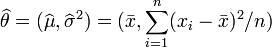 .
.
性質
泛函不變性(Functional invariance)
如果是的一個最大似然估計,那麼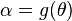 的最大似然估計是
的最大似然估計是 .函式g無需是一個一一對映。請參見George
Casella與Roger L. Berger所著的Statistical Inference定理Theorem 7.2.10的證明。(中國大陸出版的大部分教材上也可以找到這個證明。)
.函式g無需是一個一一對映。請參見George
Casella與Roger L. Berger所著的Statistical Inference定理Theorem 7.2.10的證明。(中國大陸出版的大部分教材上也可以找到這個證明。)
漸近線行為
最大似然估計函式在取樣樣本總數趨於無窮的時候達到最小方差(其證明可見於Cramer-Rao lower bound)。當最大似然估計非偏時,等價的,在極限的情況下我們可以稱其有最小的均方差。 對於獨立的觀察來說,最大似然估計函式經常趨於正態分佈。
偏差
最大似然估計的偏差是非常重要的。考慮這樣一個例子,標有1到n的n張票放在一個盒子中。從盒子中隨機抽取票。如果n是未知的話,那麼n的最大似然估計值就是抽出的票上標有的n,儘管其期望值的只有 .為了估計出最高的n值,我們能確定的只能是n值不小於抽出來的票上的值。
.為了估計出最高的n值,我們能確定的只能是n值不小於抽出來的票上的值。
注意:
最大似然估計是個概率學的問題,其作用物件是一次取樣的資料(包含了很多特徵資訊點,知道其滿足什麼分佈,如高斯分佈,但引數未知,從而轉換為一個引數估計的問題),最大似然估計的作用是,利用一次取樣的資料(不完整的資料,以拋硬幣的例子來說明最貼切),來估計完整資料的真實分佈,但該估計是最大可能的估計,而不是無偏估計。
1. 作用
在已知試驗結果(即是樣本)的情況下,用來估計滿足這些樣本分佈的引數,把可能性最大的那個引數![]() 作為真實
作為真實![]() 的引數估計。
的引數估計。
2. 離散型
設![]() 為離散型隨機變數,
為離散型隨機變數,![]() 為多維引數向量,如果隨機變數
為多維引數向量,如果隨機變數![]() 相互獨立且概率計算式為P{
相互獨立且概率計算式為P{![]() ,則可得概率函式為P{
,則可得概率函式為P{![]() }=
}=![]() ,在
,在![]() 固定時,上式表示
固定時,上式表示![]() 的概率;當
的概率;當![]() 已知的時候,它又變成
已知的時候,它又變成![]() 的函式,可以把它記為
的函式,可以把它記為![]() ,稱此函式為似然函式。似然函式值的大小意味著該樣本值出現的可能性的大小,既然已經得到了樣本值
,稱此函式為似然函式。似然函式值的大小意味著該樣本值出現的可能性的大小,既然已經得到了樣本值![]() ,那麼它出現的可能性應該是較大的,即似然函式的值也應該是比較大的,因而最大似然估計就是選擇使
,那麼它出現的可能性應該是較大的,即似然函式的值也應該是比較大的,因而最大似然估計就是選擇使![]() 達到最大值的那個
達到最大值的那個![]() 作為真實
作為真實![]() 的估計。
的估計。
3. 連續型
設![]() 為連續型隨機變數,其概率密度函式為
為連續型隨機變數,其概率密度函式為![]() ,
,![]() 為從該總體中抽出的樣本,同樣的如果
為從該總體中抽出的樣本,同樣的如果![]() 相互獨立且同分布,於是樣本的聯合概率密度為
相互獨立且同分布,於是樣本的聯合概率密度為![]() 。大致過程同離散型一樣。
。大致過程同離散型一樣。
4. 關於概率密度(PDF)
我們來考慮個簡單的情況(m=k=1),即是引數和樣本都為1的情況。假設進行一個實驗,實驗次數定為10次,每次實驗成功率為0.2,那麼不成功的概率為0.8,用y來表示成功的次數。由於前後的實驗是相互獨立的,所以可以計算得到成功的次數的概率密度為:
![]() =
=![]() 其中y
其中y![]()
由於y的取值範圍已定,而且![]() 也為已知,所以圖1顯示了y取不同值時的概率分佈情況,而圖2顯示了當
也為已知,所以圖1顯示了y取不同值時的概率分佈情況,而圖2顯示了當![]() 時的y值概率情況。
時的y值概率情況。

圖1 ![]() 時概率分佈圖
時概率分佈圖

圖2 ![]() 時概率分佈圖
時概率分佈圖
那麼![]() 在[0,1]之間變化而形成的概率密度函式的集合就形成了一個模型。
在[0,1]之間變化而形成的概率密度函式的集合就形成了一個模型。
5. 最大似然估計的求法
由上面的介紹可以知道,對於圖1這種情況y=2是最有可能發生的事件。但是在現實中我們還會面臨另外一種情況:我們已經知道了一系列的觀察值和一個感興趣的模型,現在需要找出是哪個PDF(具體來說引數![]() 為多少時)產生出來的這些觀察值。要解決這個問題,就需要用到引數估計的方法,在最大似然估計法中,我們對調PDF中資料向量和引數向量的角色,於是可以得到似然函式的定義為:
為多少時)產生出來的這些觀察值。要解決這個問題,就需要用到引數估計的方法,在最大似然估計法中,我們對調PDF中資料向量和引數向量的角色,於是可以得到似然函式的定義為:
![]()
該函式可以理解為,在給定了樣本值的情況下,關於引數向量![]() 取值情況的函式。還是以上面的簡單實驗情況為例,若此時給定y為7,那麼可以得到關於
取值情況的函式。還是以上面的簡單實驗情況為例,若此時給定y為7,那麼可以得到關於![]() 的似然函式為:
的似然函式為:
![]()
繼續回顧前面所講,圖1,2是在給定![]() 的情況下,樣本向量y取值概率的分佈情況;而圖3是圖1,2橫縱座標軸相交換而成,它所描述的似然函式圖則指出在給定樣本向量y的情況下,符合該取值樣本分佈的各種引數向量
的情況下,樣本向量y取值概率的分佈情況;而圖3是圖1,2橫縱座標軸相交換而成,它所描述的似然函式圖則指出在給定樣本向量y的情況下,符合該取值樣本分佈的各種引數向量![]() 的可能性。若
的可能性。若![]() 相比於
相比於![]() ,使得y=7出現的可能性要高,那麼理所當然的
,使得y=7出現的可能性要高,那麼理所當然的![]() 要比
要比![]() 更加接近於真正的估計引數。所以求
更加接近於真正的估計引數。所以求![]() 的極大似然估計就歸結為求似然函式
的極大似然估計就歸結為求似然函式![]() 的最大值點。那麼
的最大值點。那麼![]() 取何值時似然函式
取何值時似然函式![]() 最大,這就需要用到高等數學中求導的概念,如果是多維引數向量那麼就是求偏導。
最大,這就需要用到高等數學中求導的概念,如果是多維引數向量那麼就是求偏導。

圖3 ![]() 的似然函式分佈圖
的似然函式分佈圖
主要注意的是多數情況下,直接對變數進行求導反而會使得計算式子更加的複雜,此時可以借用對數函式。由於對數函式是單調增函式,所以![]() 與
與![]() 具有相同的最大值點,而在許多情況下,求
具有相同的最大值點,而在許多情況下,求![]() 的最大值點比較簡單。於是,我們將求
的最大值點比較簡單。於是,我們將求![]() 的最大值點改為求
的最大值點改為求![]() 的最大值點。
的最大值點。
![]()
若該似然函式的導數存在,那麼對![]() 關於引數向量的各個引數求導數(當前情況向量維數為1),並命其等於零,得到方程組:
關於引數向量的各個引數求導數(當前情況向量維數為1),並命其等於零,得到方程組:
![]()
可以求得![]() 時似然函式有極值,為了進一步判斷該點位最大值而不是最小值,可以繼續求二階導來判斷函式的凹凸性,如果
時似然函式有極值,為了進一步判斷該點位最大值而不是最小值,可以繼續求二階導來判斷函式的凹凸性,如果![]() 的二階導為負數那麼即是最大值,這裡再不細說。
的二階導為負數那麼即是最大值,這裡再不細說。
還要指出,若函式
最大似然估計的原理
給定一個概率分佈,假定其概率密度函式(連續分佈)或概率聚集函式(離散分佈)為,以及一個分佈引數,我們可以從這個分佈中抽出一個具有個值的取樣,通過利用,我們就能計算出其概率:
但是,我們可能不知道的值,儘管我們知道這些取樣資料來自於分佈。那麼我們如何才能估計出呢?一個自然的想法是從這個分佈
1 熵
熵其實是資訊量的期望值,它是一個隨機變數的確定性的度量。熵越大,變數的取值越不確定,越無序。
公式:
H(X)=E[I(x)]=−E[logP(x)]=-∑P(xi)logP(xi)
熵代表資訊量,基於P分佈自身的編碼長度,是最優的編碼長度。
2 ML 總結 ora 二次 判斷 天都 特性 以及 解釋 意思 【機器學習基本理論】詳解最大似然估計(MLE)、最大後驗概率估計(MAP),以及貝葉斯公式的理解
https://mp.csdn.net/postedit/81664644
最大似然估計(Maximum lik
轉載請註明出處,文章來源:https://blog.csdn.net/qq_36396104/article/details/78171600#commentsedit
之前看書上的一直不理解到底什麼是似然,最後還是查了好幾篇文章後才明白,現在我來總結一下吧,要想看懂最大似然估計,首 最大似然估計 (MLE) 最大後驗概率(MAP)
1) 最大似然估計 MLE
給定一堆資料,假如我們知道它是從某一種分佈中隨機取出來的,可是我們並不知道這個分佈具體的參,即“模型已定,引數未知”。例如,我們知道這個分佈是正態分佈,但是不知道均值和方差;或者是二項分佈,但是不知道均值。 最 1) 極/最大似然估計 MLE
給定一堆資料,假如我們知道它是從某一種分佈中隨機取出來的,可是我們並不知道這個分佈具體的參,即“模型已定,引數未知”。例如,我們知道這個分佈是正態分佈,但是不知道均值和方差;或者是二項分佈,但是不知道均值。 最大似然估計(MLE,Maximum Likelihood Esti
<svg xmlns="http://www.w3.org/2000/svg" style="display: none;"><path stroke-linecap="round" d="M5,0 0,2.5 5,5z" id=
前言
frequentist statistics:模型引數是未知的定值,觀測是隨機變數;思想是觀測數量趨近於無窮大+真實分佈屬於模型族中->引數的點估計趨近真實值;代表是極大似然估計MLE;不依賴先驗。
Bayesian statistics:模型引數是隨機變數,
joey 周琦
假設有引數
θ
\theta, 觀測
x
\mathbf{x}, 設
f(x|θ)
f(x|\theta)是變數
x
x的取樣分佈,
θ
\th
1. MLE的意義:樣本估計總體分佈引數
假定一個事件的觀測樣本服從如下分佈,我們如何確定總體資料的分佈模型?
首先應該想到是建立線性迴歸模型,然而由於該變數不是正態分佈的,而且是不對稱的,因此不符合線性迴歸的假設。
常用的方法是對變數進行對數、平方根、倒數等轉換,
概述編輯:
最大似然估計是一種統計方法,它用來求一個樣本集的相關概率密度函式的引數。這個方法最早是遺傳學家以及統計學家羅納德·費雪爵士在1912年至1922年間開始使用的。
“似然”是對likelihood 的一種較為貼近文言文的翻譯,“似然”用現代的中文來說即
最大似然估計 MLE
給定一堆資料,假如我們知道它是從某一種分佈中隨機取出來的,可是我們並不知道這個分佈具體的參,即“模型已定,引數未知”。
例如,對於線性迴歸,我們假定樣本是服從正態分佈,但是不知道均值和方差;或者對於邏輯迴歸,我們假定樣本是服從二項分佈,但是不知道 enc bsp 聯系 角度 tro span nbsp sdn .science 對於最小二乘法,當從模型總體隨機抽取n組樣本觀測值後,最合理的參數估計量應該使得模型能最好地擬合樣本數據,也就是估計值和觀測值之差的平方和最小。而對於最大似然法,當從模型總體隨機抽取n組樣本觀
舉個例子:偷盜的故事,三個村莊,五個人偷。
村子被不同小偷偷的概率:P(村子|小偷1)、P(村子|小偷2)、P(村子|小偷3)
小偷1的能力:P(偷盜能力)=P(村子1|小偷1)+P(村子2|小偷1)+P(村子3|小偷1)+P(村子4|小偷1)+P(村子5|小偷1)
小
估計即是近似地求某個引數的值,需要區別理解樣本、總體、量、值
大致的題型是已知某分佈(其實包含未知引數),從中取樣本並給出樣本值
我只是一個初學者,可能有的步驟比較繁瑣,請見諒~
1、矩估計法
最大似然估計(Maximum Likelihood Estimation),是一種統計方法,它用來求一個樣本集的相關概率密度函式的引數。最大似然估計中取樣需滿足一個很重要的假設,就是所有的取樣都是獨立同分布的。
一、最大似然估計法的基本思想
最大似然估計法的思想
寫的很通俗易懂…….
最大似然估計提供了一種給定觀察資料來評估模型引數的方法,即:“模型已定,引數未知”。簡單而言,假設我們要統計全國人口的身高,首先假設這個身高服從服從正態分佈,但是該分佈的均值與方差未知。我們沒有人力與物力去統計全國每個人的身高,但是可以通
一、最大似然估計的基本思想
最大似然估計的基本思想是:從樣本中隨機抽取n個樣本,而模型的引數估計量使得抽取的這n個樣本的觀測值的概率最大。最大似然估計是一個統計方法,它用來求一個樣本集的概率密度函式的引數。
二、似然估計
在講最小二乘法的時候,我們的例 基礎
頻率學派與貝葉斯學派
最大似然估計(Maximum likelihood estimation,MLE)
最大後驗估計(maximum a posteriori estimation,MAP)
貝葉斯估計(Bayesian parameter estimation,BPE)
經典引數估計方 content tar eight maximum spa width src www alt
參考資料
[1]
盛驟, 謝式千,
潘承毅.
概率論和數理統計[J]. 2001.
[2]
https://en.wikipedia.org/wiki ![]() 關於
關於
相關推薦
最大似然估計(like-hood)
熵、最大似然估計(相對熵)、KL散度、交叉熵相互關係及程式碼計算
【機器學習基本理論】詳解最大似然估計(MLE)、最大後驗概率估計(MAP),以及貝葉斯公式的理解
最大似然估計(轉載)
最大似然估計 最大似然估計 (MLE) 最大後驗概率(MAP)
【模式識別與機器學習】——最大似然估計 (MLE) 最大後驗概率(MAP)
詳解最大似然估計(MLE)、最大後驗概率估計(MAP),以及貝葉斯公式的理解
最大似然估計(MLE)、最大後驗概率估計(MAP)以及貝葉斯學派和頻率學派
機器學習概念:最大後驗概率估計與最大似然估計 (Maximum posterior probability and maximum likelihood estimation)
最大似然估計(MLE:樣本觀測總體引數)是如何工作的?
最大似然估計(MLE)
最大似然估計 (MLE)與 最大後驗概率(MAP)在機器學習中的應用
最小二乘法和最大似然估計的聯系和區別(轉)
最大似然估計和最大後驗概率估計(貝葉斯引數估計)
點估計(矩估計法和最大似然估計法)
最大似然估計法(MLE)
最大似然估計演算法(極大似然估計演算法)
機器學習筆記(四)——最大似然估計
【轉載】引數估計(Parameter Estimation):頻率學派(最大似然估計MLE、最大後驗估計MAP)與貝葉斯學派(貝葉斯估計BPE)
最大似然預計(Maximum Likelihood Estimation)
![相關推薦 最大似然估計(like-hood) 最大似然估計的原理 給定一個概率分佈,假定其概率密度函式(連續分佈)或概率聚集函式(離散分佈)為,以及一個分佈引數,我們可以從這個分佈中抽出一個具有個值的取樣,通過利用,我們就能計算出其概率: 但是,我們可能不知道的值,儘管我們知道這些取樣資料來自於分佈。那麼我們如何才能估計出呢?一個自然的想法是從這個分佈 熵、最大似然估計(相對熵)、KL散度、交叉熵相互關係及程式碼計算 1 熵 熵其實是資訊量的期望值,它是一個隨機變數的確定性的度量。熵越大,變數的取值越不確定,越無序。 公式: H(X)=E[I(x)]=−E[logP(x)]=-∑P(xi)logP(xi) 熵代表資訊量,基於P分佈自身的編碼長度,是最優的編碼長度。 2 ML 【機器學習基本理論】詳解最大似然估計(MLE)、最大後驗概率估計(MAP),以及貝葉斯公式的理解 總結 ora 二次 判斷 天都 特性 以及 解釋 意思 【機器學習基本理論】詳解最大似然估計(MLE)、最大後驗概率估計(MAP),以及貝葉斯公式的理解 https://mp.csdn.net/postedit/81664644 最大似然估計(Maximum lik 最大似然估計(轉載) 轉載請註明出處,文章來源:https://blog.csdn.net/qq_36396104/article/details/78171600#commentsedit 之前看書上的一直不理解到底什麼是似然,最後還是查了好幾篇文章後才明白,現在我來總結一下吧,要想看懂最大似然估計,首 最大似然估計 最大似然估計 (MLE) 最大後驗概率(MAP) 最大似然估計 (MLE) 最大後驗概率(MAP) 1) 最大似然估計 MLE 給定一堆資料,假如我們知道它是從某一種分佈中隨機取出來的,可是我們並不知道這個分佈具體的參,即“模型已定,引數未知”。例如,我們知道這個分佈是正態分佈,但是不知道均值和方差;或者是二項分佈,但是不知道均值。 最 【模式識別與機器學習】——最大似然估計 (MLE) 最大後驗概率(MAP) 1) 極/最大似然估計 MLE 給定一堆資料,假如我們知道它是從某一種分佈中隨機取出來的,可是我們並不知道這個分佈具體的參,即“模型已定,引數未知”。例如,我們知道這個分佈是正態分佈,但是不知道均值和方差;或者是二項分佈,但是不知道均值。 最大似然估計(MLE,Maximum Likelihood Esti 詳解最大似然估計(MLE)、最大後驗概率估計(MAP),以及貝葉斯公式的理解 <svg xmlns="http://www.w3.org/2000/svg" style="display: none;"><path stroke-linecap="round" d="M5,0 0,2.5 5,5z" id= 最大似然估計(MLE)、最大後驗概率估計(MAP)以及貝葉斯學派和頻率學派 前言 frequentist statistics:模型引數是未知的定值,觀測是隨機變數;思想是觀測數量趨近於無窮大+真實分佈屬於模型族中->引數的點估計趨近真實值;代表是極大似然估計MLE;不依賴先驗。 Bayesian statistics:模型引數是隨機變數, 機器學習概念:最大後驗概率估計與最大似然估計 (Maximum posterior probability and maximum likelihood estimation) joey 周琦 假設有引數 θ \theta, 觀測 x \mathbf{x}, 設 f(x|θ) f(x|\theta)是變數 x x的取樣分佈, θ \th 最大似然估計(MLE:樣本觀測總體引數)是如何工作的? 1. MLE的意義:樣本估計總體分佈引數 假定一個事件的觀測樣本服從如下分佈,我們如何確定總體資料的分佈模型? 首先應該想到是建立線性迴歸模型,然而由於該變數不是正態分佈的,而且是不對稱的,因此不符合線性迴歸的假設。 常用的方法是對變數進行對數、平方根、倒數等轉換, 最大似然估計(MLE) 概述編輯: 最大似然估計是一種統計方法,它用來求一個樣本集的相關概率密度函式的引數。這個方法最早是遺傳學家以及統計學家羅納德·費雪爵士在1912年至1922年間開始使用的。 “似然”是對likelihood 的一種較為貼近文言文的翻譯,“似然”用現代的中文來說即 最大似然估計 (MLE)與 最大後驗概率(MAP)在機器學習中的應用 最大似然估計 MLE 給定一堆資料,假如我們知道它是從某一種分佈中隨機取出來的,可是我們並不知道這個分佈具體的參,即“模型已定,引數未知”。 例如,對於線性迴歸,我們假定樣本是服從正態分佈,但是不知道均值和方差;或者對於邏輯迴歸,我們假定樣本是服從二項分佈,但是不知道 最小二乘法和最大似然估計的聯系和區別(轉) enc bsp 聯系 角度 tro span nbsp sdn .science 對於最小二乘法,當從模型總體隨機抽取n組樣本觀測值後,最合理的參數估計量應該使得模型能最好地擬合樣本數據,也就是估計值和觀測值之差的平方和最小。而對於最大似然法,當從模型總體隨機抽取n組樣本觀 最大似然估計和最大後驗概率估計(貝葉斯引數估計) 舉個例子:偷盜的故事,三個村莊,五個人偷。 村子被不同小偷偷的概率:P(村子|小偷1)、P(村子|小偷2)、P(村子|小偷3) 小偷1的能力:P(偷盜能力)=P(村子1|小偷1)+P(村子2|小偷1)+P(村子3|小偷1)+P(村子4|小偷1)+P(村子5|小偷1) 小 點估計(矩估計法和最大似然估計法) 估計即是近似地求某個引數的值,需要區別理解樣本、總體、量、值 大致的題型是已知某分佈(其實包含未知引數),從中取樣本並給出樣本值 我只是一個初學者,可能有的步驟比較繁瑣,請見諒~ 1、矩估計法 最大似然估計法(MLE) 最大似然估計(Maximum Likelihood Estimation),是一種統計方法,它用來求一個樣本集的相關概率密度函式的引數。最大似然估計中取樣需滿足一個很重要的假設,就是所有的取樣都是獨立同分布的。 一、最大似然估計法的基本思想 最大似然估計法的思想 最大似然估計演算法(極大似然估計演算法) 寫的很通俗易懂……. 最大似然估計提供了一種給定觀察資料來評估模型引數的方法,即:“模型已定,引數未知”。簡單而言,假設我們要統計全國人口的身高,首先假設這個身高服從服從正態分佈,但是該分佈的均值與方差未知。我們沒有人力與物力去統計全國每個人的身高,但是可以通 機器學習筆記(四)——最大似然估計 一、最大似然估計的基本思想 最大似然估計的基本思想是:從樣本中隨機抽取n個樣本,而模型的引數估計量使得抽取的這n個樣本的觀測值的概率最大。最大似然估計是一個統計方法,它用來求一個樣本集的概率密度函式的引數。 二、似然估計 在講最小二乘法的時候,我們的例 【轉載】引數估計(Parameter Estimation):頻率學派(最大似然估計MLE、最大後驗估計MAP)與貝葉斯學派(貝葉斯估計BPE) 基礎 頻率學派與貝葉斯學派 最大似然估計(Maximum likelihood estimation,MLE) 最大後驗估計(maximum a posteriori estimation,MAP) 貝葉斯估計(Bayesian parameter estimation,BPE) 經典引數估計方 最大似然預計(Maximum Likelihood Estimation) content tar eight maximum spa width src www alt 參考資料 [1] 盛驟, 謝式千, 潘承毅. 概率論和數理統計[J]. 2001. [2] https://en.wikipedia.org/wiki](http://hi.csdn.net/attachment/201101/9/0_12945811782bMB.gif){kind=link}