
《大資料網際網路大規模資料探勘與分散式處理》閱讀筆記(二)
轉載連線:http://blog.csdn.net/lovemianmian/article/details/9050617
首先來看看這一章講解的整體架構,分別介紹了分散式檔案系統、Map-Reduce、使用Map-Reduce的演算法,Map-Reduce擴充套件和叢集計算演算法的效率問題。
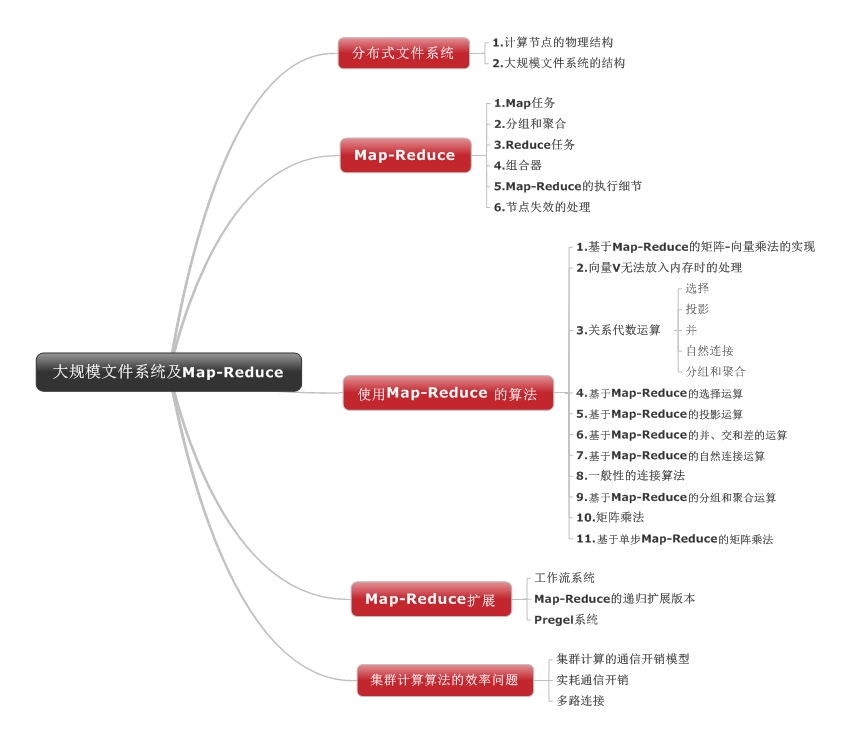
一、分散式檔案系統
1.1分散式檔案系統起因
大規模WEB服務流行在數千個計算節點完成大規模計算這些計算節點都是普通的硬體構成,為了發揮並行化的優勢,保證可靠性開發專用的檔案系統。
1.2分散式檔案系統特點
本書寫的特徵是:1)儲存單位比傳統作業系統中的磁碟快大
2
聯想:如果使用者同時對一個檔案進行寫操作,如何同步,是不是採取加鎖方案。
搜一搜:
如果檔案的訪問僅限於一個使用者,那麼分散式檔案系統就很容易實現。可惜的是,在許多網路環境中這種限制是不現實的,必須採取併發控制來實現檔案的多使用者訪問,表現為如下幾個形式:
只讀共享任何客戶機只能訪問檔案,而不能修改它,這實現起來很簡單。採取這種形式。
受控寫操作採用這種方法,可有多個使用者開啟一個檔案,但只有一個使用者進行寫修改。而該使用者所作的修改並不一定出現在其它已開啟此檔案的使用者的螢幕上。
併發寫操作這種方法允許多個使用者同時讀寫一個檔案。但這需要作業系統作大量的監控工作以防止檔案重寫,並保證使用者能夠看到最新資訊。這種方法即使實現得很好,許多環境中的處理要求和網路通訊量也可能使它變得不可接受。
1.3計算節點的物理結構
叢集計算:一種新的平行計算架構,其中計算節點位於機架,單節點之間網路互連,機架之間另一級網路或交換機互連。
主要故障模式:單節點故障;單機架故障
解決方案:文字需要多副本儲存;計算過程需要分成多個任務完成。
聯想:文字過多,資料冗餘過渡也是一種資源浪費,判定副本儲存數量的閾值如何確定?
聯想:計算過程中多工完成,其中某些任務突然因為外界原因宕機,怎麼切換到其他機子上執行?
搜一搜:
l 例如在HADOOP的HDFS檔案系統中,預設的副本個數是3,兩個存放在一個機架,另一個放在其他機架上。在副本機制中,副本的數量值意味著對資料的儲存空間的需求是原始資料的數倍,對於非重要的資料而言就是空間浪費,因此需要考慮如何基於資料的重要性來設定文字的副本數,搜到了一篇碩士論文講述的是基於歷史統計記錄的動態副本策略,連結如下:
l 在HADOOP的HDFS中有一種心跳機制,可以掌握叢集的工作狀況。DataNode通過週期性地傳送信條資訊與NameNode聯絡,Namenode通過獲取的心跳資訊得知DataNode的存在,及其上的磁碟容量、已用空間、總負載等資訊,可以參考這片博文講解的比較詳細:http://blog.csdn.net/fly542/article/details/6797139
l 通過一些負載管理工具進行分散式檔案的管理,還可以通過快照定期儲存某個時刻的資料複製,當資料損壞的時候,可以回滾到一個過去已知的正確的時間點。
二、Map-Reduce
2.1 Map任務
Map-reduce的思想就是“分而治之”, Mapper負責“分”,即把複雜的任務分解為若干個“簡單的任務”執行.“簡單的任務”有幾個含義:
l 資料或計算規模相對於原任務要大大縮小;
l 就近計算,即會被分配到存放了所需資料的節點進行計算;
l 這些小任務可以平行計算,彼此間幾乎沒有依賴關係。
Map 任務的輸入檔案由多個元素組成,元素可以是任意型別。所有Map任務的輸入和Reduce任務的輸出都是鍵-值對的形式。此時的“鍵”不要求它們的唯一性,一個Map任務可以生產多個具有相同鍵的鍵-值對。
2.2 分組和聚合
分組:主控程序通常選擇一個雜湊函式作用於鍵併產生一個0到r-1(r為reduce任務的數目)的桶編號。Map任務輸出的每個鍵都被雜湊函式作用,根據雜湊結果其鍵-值將被放到r個本地檔案中的一個。每個檔案都會被指派一個Reduce任務。
合併:主控程序將每個Map任務輸出的面向某個特定Reduce任務的檔案合併,還是以鍵-值對序列傳給程序。
2.3 Reduce任務
對map階段的結果進行彙總,Reducer的數目由mapred-site.xml配置檔案裡的專案mapred.reduce.tasks決定。預設值為3,使用者可以覆蓋之。
Reduce任務的輸出是鍵-值對序列,鍵Key是Reduce任務接收到的輸入鍵,值value是其接收到與key關聯的值的組合結果。
所有的Reduce任務的輸出結果會合併成一個檔案。
2.4 組合器
Reduce函式滿足交換律和結合律,即組合值可以按照任何次序組合,其結果不變。
2.4 Map-Reduce的執行細節
一般而言,每個工作程序要麼處理Map任務,要麼處理Reduce任務。
主控程序要負責建立一定數目的Map和Reduce任務。一般情況下對於輸入檔案的每個檔案都會建立一個Map任務,但是要限制Reduce任務的數量,因為每個Map任務都必須給每個Reduce任務建立中間檔案,Reduce任務太多,會導致中間檔案數目暴增。
主控程序要負責記錄每個Map和Reduce的執行狀態,分配新任務或對宕機的節點上的任務進行處理等。
2.4 節點失效的處理
兩種情況,主控程序的計算節點崩潰和Reduce任務的計算節點失效,前者整個Map-Reduce作業都需要重啟,後者則是需要將失效節點上執行的Reduce任務的狀態置為“空閒”,並安排另外的工作節點重新執行。
聯想:主控程序的計算節點崩潰就需要重啟整個作業,這勢必會造成巨大的損失,有沒其他方法。
搜一搜:
事實上,設計者對Namenode的單點故障還是有所考慮的,比如在hadoop會設定一個Secondary NameNode,即輔助名稱節點,輔助名稱節點是在名稱節點發生故障時替換名稱節點的。SecondNamenode是對主Namenode的一個補充,它會週期的執行對HDFS元資料的檢查點。當前的設計僅僅允許每個HDFS只有單個SecondNamenode結點。SecondNamenode是有一個後臺的程序,會定期的被喚醒(喚醒的週期依賴相關配置)執行檢查點任務,然後繼續休眠。它使用ClientProtocol協議與主Namenode通訊。
http://blog.csdn.NET/shatelang/article/details/7595373?reload
實踐一下:
有一個文字檔案,裡面每一行是一個單詞,統計這個檔案裡總共有哪些不同的單詞(相當於去重問題),設計Map-Reduce演算法過程。
解:
假設有640M的檔案,預設block大小為64M,10臺Hadoop機器,使用5個reduce任務:
1. 每個map任務按行讀取檔案,讀取的行資料交給map函式執行,通過指定的TextInputFormat一次處理一行。然後,它通過StringTokenizer以空格為分隔符將一行切分為若干tokens,之後,輸出< <word>, 1>形式的鍵值對。
2. 如果有combiner,就對第一步的輸出進行combiner操作。即每次map過程介紹之後,會對輸出按照key進行排序,然後把輸出傳遞給本地的combiner(按照作業的配置是與Reducer一樣的,都使用的是Reduce.class),進行本地聚合,將相同word的計數累加。這樣可以將中間結果大大減少,減少後續partitioner, sort, copy的開銷,提高效能。
3. 每個map任務對自己的輸出進行分割槽,預設的分割槽操作是對key進行hash,並對reduce任務數求餘,這樣相同的單詞都被分在同一分割槽內。之後將對同一分割槽內的資料按key進行排序,使之成為各分割槽內有序。
4. Reduce任務各自從map機器上copy屬於自己的檔案,並且進行合併。合併好後進行Sort操作,再次把不同小檔案中的同一單詞聚合在一起,作為提供給reduce操作的資料。
5. 進行reduce操作,對同一個單詞的value列表再次進行累加,最終得到每個單詞的詞頻數。一般是呼叫Reducer介面中的 reduce方法,輸入引數中的 key, values是由 Map任務輸出的中間結果,values是一個 Iterator,遍歷這個 Iterator,就可以得到屬於同一個Key的所有 value。此處,key是一個單詞,value是詞頻。只需要將所有的 value相加,就可以得到這個單詞的總的出現次數。
6. 最後Reduce把結果寫到磁碟。
三、使用Map-Reduce的演算法
首先要明確的是Map-Reduce框架不是萬能通用的,整個分散式檔案系統只在檔案巨大、更新很少的情況下才有意義。例如像矩陣-向量和矩陣-矩陣計算非常適合Map-Reduce計算框架。
3.1 Map-Reduce的矩陣-向量乘法實現
先要明確的是Map-Reduce框架不是萬能通用的,整個分散式檔案系統只在檔案巨大、更新很少的情況下才有意義。例如像矩陣-向量和矩陣-矩陣計算非常適合Map-Reduce計算框架。
一個n*n的矩陣M和n維向量v的乘積是一個n維向量x。
Map函式每個Map任務講整個向量v和矩陣M的一個檔案塊作為輸入。對每個矩陣元素,Map任務都有一個鍵-值對()。
Reduce函式 Reduce任務將所有與給定鍵i相關的值相加即可。
3.2 向量v無法放入記憶體時的處理
解決方案:將矩陣分割成為多個寬度相等的垂直條,同時將向量分割成同樣數目的水平條,每個水平條的高度等於矩陣垂直條的寬度。矩陣第i個垂直條只和向量的第i個水平條相乘。
3.3 關係代數運算
由於大規模資料處理勢必要用到許多的資料庫查詢操作,這節簡單回顧了查詢中常用的幾個關係運算:選擇,投影,並,交,差,自然連線,分組和聚合.
選擇:對關係R的每一個元素應用條件C,得到僅滿足條件C的元組。
投影:對關係R的某一個屬性子集S,從每個元組中得到僅包含S中屬性的元素。
並、交、差用於兩個具有相同模式的關係的元組集合上。
自然連線:如果兩個元組的所有公共屬性的屬性值一致,就生成了一個新的元組,這個元組有原來兩個元組的公共部分加上非公共部分組成。
分組和聚合:給定關係R,分組是指按照屬性集合G中的值對元組進行分割。然後對每個組的值按照某些其他的屬性進行聚合。典型的聚合運算:SUM、COUNT、AVG、MIN、MAX。
3.4 基於Map-Reduce的選擇運算
Map: 對於每個R中的元組t,檢測它是否滿足C,如果滿足則產生一個鍵-值對(t,t),鍵值都是t。
Reduce: 僅將每一個鍵-值對傳遞到輸出部分。
3.5 基於Map-Reduce的投影運算
Map: 對於每個R中的元組t,剔除t中屬性不在S中的欄位得到元組 ,輸出鍵-值對 。
Reduce: 對任意Map任務產生的每個鍵 ,將存在一個或者多個鍵-值對,Reduce函式將轉化成 ,以保證該鍵值只產生一個鍵-值對。
3.6 基於Map-Reduce的並、交、差運算
Map只將相同模式關係R和S的輸入元組作為鍵-值對輸給Reduce任務,Reduce只需要向投影一樣剔除冗餘。
並
Map: 將每個輸入的元組t轉變為鍵-值對 。
Reduce: 和每個鍵t關聯的可能有一個或者兩個值,兩種情況下都輸出
交
Map: 將每個輸入的元組t轉變為鍵-值對 。
Reduce: 如果鍵t的值表為 ,則輸出 ,否則輸出 。
差
Map: 對於R中的元組t,產生鍵-值對 。對於S中的元組t,產生鍵-值對.R,S為關係的名稱,並非關係本身。
Reduce: 如果相關聯的值表為[R],則輸出鍵-值對 ,否則輸出 。
3.7 基於Map-Reduce的自然連線運算
例項:將關係R(A,B)和S(B,C)進行自然連線運算。
Map: 對於R中的元組t,產生鍵-值對 。對於S中的元組t,產生鍵-值對.
Reduce: 基於(R,a)和(S,c)構建的所有對,鍵b所對應的輸出結果為(b,[(a1,b,c2), (a2,b,c2), …])
上述演算法在關係多餘兩個屬性的情況下同樣適用。
3.8 基於Map-Reduce的分組和聚合運算
Map: 對於每個元組(a,b,c)產生鍵-值對 。
Reduce: 每一個鍵a代表一個分組,即對與鍵a相關的欄位B的值表施加Θ操作,輸出結果對(a,x),x為Θ操作的結果。
3.9 矩陣乘法
矩陣乘積相當於一個自然連線運算再加上分組和聚合運算。
Map: 將每一個矩陣元素mij傳值給鍵-值對,將每一個矩陣元素njk傳值給鍵-值對。
Reduce: 對於來自M的鍵-值對 和來自N的鍵-值對 ,產生 。
然後再通過另外一個Map-Reduce運算進行分組聚類。將上面的reduce函式結果傳遞給Map函式,形式為 ,產生鍵-值對 ,最後通過Reduce,對於每個鍵(i,k),將與此鍵關聯的的所有值的和,結果計為((i,k),v)。
3.10 基於單步Map-Reduce的矩陣乘法
Map: 將每一個矩陣元素mij傳值給鍵-值對,將每一個矩陣元素njk傳值給鍵-值對。
Reduce: 將兩個列表的第j個元組中的 和 出相乘,然後再將這些積相加,最後於鍵(i,k)組對作為Reduce函式的輸出結果。
四、Map-Reduce的擴充套件
改進和系統和Map-Reduce具有相同的共同特徵
(1)建立在分散式檔案系統之上
(2)管理大量任務,任務是使用者編寫函式的例項化結果
(3)提供大任務執行過程中發生的大部分失效的處理方法。
4.1 工作流系統
將Map-Reduce一般化為支援任意無環函式集的系統,每個函式都可以例項化為任意數目的任務。
關鍵在於任何任務只有在輸入準備好之後才能輸出。這樣就可以保證如果某個任務失敗,其結果不會傳遞給它工作流中的
後續任務,避免了通訊開銷。
4.2 Map-Reduce的遞迴擴充套件版本
遞迴主要是通過Map-Reduce過程的迭代呼叫實現,因為一個真正的遞迴任務不能獨立啟動失效任務。這就要求我們在存在遞迴工作流的系統中,引入某些機制來處理任務失效,而不是重啟。
介紹了遞迴任務集中的連線任務和去重任務,主控程序將一直等待直到每個連線任務完成對其完整輸入的一輪處理,再將輸出的檔案分部到查重任務作為輸入,再講輸出結果作為連線任務的下一輪輸入。如果每個任務都儲存曾產生過的輸出檔案,並且把連線和去重任務放在不同機架上,就可以處理單節點故障和單機架故障。
4.3 Pregel系統
Pregel系統提供了在計算叢集中實現遞迴演算法時的處理失效任務的方法。在計算過程中設立檢查點,在執行超步後記錄整個計算的現場,對每個任務的全部狀態進行記錄,在處理失效任務時就可以從最近的檢查點進行重啟。
五、叢集計算演算法的效率問題
這節介紹了度量叢集計算演算法的質量模型。
5.1 叢集計算的通訊開銷模型
什麼是通訊開銷模型?
它是指實現該演算法的所有任務的通訊開銷之和,通常開銷是指資料從建立地到使用地的傳輸開銷。
為什麼要關注通訊開銷?
演算法中每個執行任務一般非常簡單,時間複雜度一般和輸入規模成線性關係;
計算叢集中的互連速度是GB/s,在任務傳輸的同等時間內,計算機可以做大量的工作;
若任務執行時需要的檔案塊存放在磁碟上,傳輸至記憶體的時間很長。
為什麼僅計算輸入規模還不計算輸出規模?
因為任務A的輸出是另一個任務B的輸入,沒有必要計算輸出規模;
而且實際中,任務的輸出比輸入規模或任務中產生的中間資料相比更小一些。
特別地Map任務的輸出和輸入規模大體相當,Map到Reduce任務的通訊一般通過叢集來互連不需要記憶體到磁碟的傳輸。
5.2 實耗通訊開銷
實耗通訊開銷是指在無環網路圖所有路徑中最大的通訊開銷。
它相當於並行演算法的最短執行時鐘時間,可以通過將所有工作平均分配給不同的任務來使通訊開銷達到儘可能的小。
5.3 多路連線
例項:三個關係R(A,B)、S(B,C)和T(C,D)的一次性連線運算的總通訊開銷
(1)S 將每個元組S(v,w)僅僅傳遞一次到Reduce任務(h(v),g(w));
(2)cr 將每個元組R(u,v)傳遞到c個Reduce任務(h(v),y),y可能取值c個;
(3)bt 將每個元組T(v,x)傳遞到b個Reduce任務(z,g(w)),z可能取值b個;
(4)r+s+t 每個關係的每個元組輸入到Map任務的開銷
拉格朗日乘子求解,優化每個關係的複製度。