
機器學習課程-第8周-聚類(Clustering)
1. 聚類(Clustering)
1.1 無監督學習: 簡介
在一個典型的監督學習中,我們有一個有標簽的訓練集,我們的目標是找到能夠區分正樣本和負樣本的決策邊界,在這裏的監督學習中,我們有一系列標簽,我們需要據此擬合一個假設函數。與此不同的是,在非監督學習中,我們的數據沒有附帶任何標簽,我們拿到的數據就是這樣的:
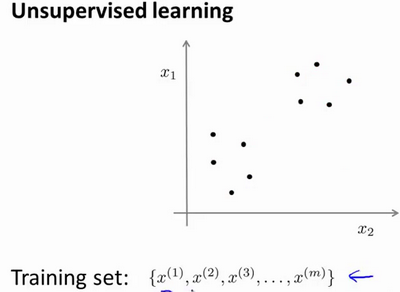
在非監督學習中,我們需要將一系列無標簽的訓練數據,輸入到一個算法中,然後我們告訴這個算法,快去為我們找找這個數據的內在結構給定數據。我們可能需要某種算法幫助我們尋找一種結構。圖上的數據看起來可以分成 兩個分開的點集(稱為簇),一個能夠找到我圈出的這些點集的算法,就被稱為聚類算法
這將是我們介紹的第一個非監督學習算法。當然,此後我們還將提到其他類型的非監督學習算法,它們可以為我們找到其他類型的結構或者其他的一些模式,而不只是簇。
1.11 聚類算法用途

1.2 K-均值算法
機器學習課程-第8周-聚類(Clustering)
相關推薦
機器學習課程-第8周-聚類(Clustering)
標簽 一個 無監督學習 學習課程 裏的 font 系列 函數 inf 1. 聚類(Clustering) 1.1 無監督學習: 簡介 在一個典型的監督學習中,我們有一個有標簽的訓練集,我們的目標是找到能夠區分正樣本和負樣本的決策邊界,在這裏的監督學習中,我們有一系列標簽
機器學習課程-第 8 周-降維(Dimensionality Reduction)—主成分分析(PCA)
art 不同 計算機 dimens 是什麽 課程 繪制 start pca 1. 動機一:數據壓縮 第二種類型的 無監督學習問題,稱為 降維。有幾個不同的的原因使你可能想要做降維。一是數據壓縮,數據壓縮不僅允許我們壓縮數據,因而使用較少的計算機內存或磁盤空間,但它也讓我們
Coursera-AndrewNg(吳恩達)機器學習筆記——第三周
訓練 ros 方便 font 就是 梯度下降 全局最優 用法 郵件 一.邏輯回歸問題(分類問題) 生活中存在著許多分類問題,如判斷郵件是否為垃圾郵件;判斷腫瘤是惡性還是良性等。機器學習中邏輯回歸便是解決分類問題的一種方法。二分類:通常表示為y?{0,1},0:“Negat
機器學習實戰第8章預測數值型數據:回歸
矩陣 向量 from his sca ima 用戶 targe 不可 1.簡單的線性回歸 假定輸入數據存放在矩陣X中,而回歸系數存放在向量W中,則對於給定的數據X1,預測結果將會是 這裏的向量都默認為列向量 現在的問題是手裏有一些x
機器學習——K-means演算法(聚類演算法)
聚類 在說K-means聚類演算法之前必須要先理解聚類和分類的區別。 分類其實是從特定的資料中挖掘模式,作出判斷的過程。比如Gmail郵箱裡有垃圾郵件分類器,一開始的時候可能什麼都不過濾,在日常使用過程中,我人工對於每一封郵件點選“垃圾”或“不是垃圾”,過一段時間,Gmail就體現出
機器學習筆記(參考吳恩達機器學習視訊筆記)12_聚類
12 聚類 監督學習中,訓練集帶有標籤,目標是找到能夠區分正負樣本的決策邊界,需要根據標籤擬合一個假設函式。非監督學習中,需要將無標籤的訓練資料輸入到一個演算法,此演算法可以找到這些資料的內在結構。一個能夠根據資料的內在結構,將它們分成幾個不同的點集(或簇)的演算法,就被稱為聚類演算法。聚類
吳恩達機器學習 筆記八 K-means聚類演算法
1. 代價函式 K-means演算法是比較容易理解的,它屬於無監督學習方法,所以訓練樣本資料不再含有標籤。我們假設有樣本資料x(1),x(2),⋯,x(m)x(1),x(2),⋯,x(m),我們選擇設定KK個聚類中心u1,u2,⋯,uKu1,u2,⋯,uK
機器學習基石第7周
The VC Dimension 一.Definition of VC Dimension 上次課我們知道我們的成長函式B(N,k)有上限,如圖中的表所示,左邊的表示B(N,k)右邊的表示N^(k-1),我們發現當N>=2,K>=3時,B(N
《機器學習實戰》KMeans均值聚類演算法
一、引言聚類是一種無監督學習,對一些沒有標籤的資料進行分類。二、K均值聚類演算法2.1 演算法過程:隨機確定K個初始點為質心(簇個數k由使用者給定),計算資料集中每個點到每個質心的距離本次採用的是歐式距離,然後將資料集中的每個點尋找距其最近的質心,分配到對應的簇中完成後,每個
機器學習---分類、迴歸、聚類、降維的區別
由上圖我們可以看到,機器學習分為四大塊,分別是 classification (分類), regression (迴歸), clustering (聚類), dimensio
Coursera-吳恩達-機器學習-(第5周筆記)Neural Networks——Learning
Week 5 —— Neural Networks : Learning 目錄 一代價函式和反向傳播 1-1 代價函式 首先定義一些我們需要使用的變數: L =網路中的總層數 sl =第l層中的單位數量(不
Spark2.0機器學習系列之11: 聚類(冪迭代聚類, power iteration clustering, PIC)
在Spark2.0版本中(不是基於RDD API的MLlib),共有四種聚類方法: (1)K-means (2)Latent Dirichlet allocation (LDA)
Python機器學習演算法實踐——k均值聚類(k-means)
一開始的目的是學習十大挖掘演算法(機器學習演算法),並用編碼實現一遍,但越往後學習,越往後實現編碼,越發現自己的編碼水平低下,學習能力低。這一個k-means演算法用Python實現竟用了三天時間,可見編碼水平之低,而且在編碼的過程中看了別人的編碼,才發現自己對
Spark2.0機器學習系列之10: 聚類(高斯混合模型 GMM)
在Spark2.0版本中(不是基於RDD API的MLlib),共有四種聚類方法: (1)K-means (2)Latent Dirichlet allocation (LDA) (3)Bisecting k-m
python機器學習之--用凝聚層次聚類進行資料分組
1.什麼是層次聚類def perfrom_clustering(X,connectivity,title,num_clusters=3,linkage='ward'): plt.figure() model = AgglomerativeClustering(
機器學習--K-means演算法(聚類,無監督學習)
一、基本思想 聚類屬於無監督學習,以往的迴歸、樸素貝葉斯、SVM等都是有類別標籤y的,也就是說樣例中已經給出了樣例的分類。而聚類的樣本中卻沒有給定y,只有特徵x,比如假設宇宙中的星星可以表示成三維空間中的點集。聚類的目的是找到每個樣本x潛在的類別y,並將同類別y的樣本x
機器學習筆記(九)聚類演算法及實踐(K-Means,DBSCAN,DPEAK,Spectral_Clustering)
這一週學校的事情比較多所以拖了幾天,這回我們來講一講聚類演算法哈。 首先,我們知道,主要的機器學習方法分為監督學習和無監督學習。監督學習主要是指我們已經給出了資料和分類,基於這些我們訓練我們的分類器以
coursera機器學習課程第六週——課程筆記
本週的內容主要分為兩部分,第一部分:主要內容是偏差、方差以及學習曲線相關的診斷方法,為改善機器學習演算法的決策提供依據;第二部分:主要內容是機器學習演算法的錯誤分析以及數值評估標準:準
機器學習筆記之K-means聚類
K-means聚類是聚類分析中比較基礎的演算法,屬於典型的非監督學習演算法。其定義為對未知標記的資料集,按照資料內部存在的資料特徵將資料集劃分為多個不同的類別,使類別內的資料儘可能接近,類別間的資料相似度比較大。用於衡量距離的方法主要有曼哈頓距離、歐氏距離、切比雪夫距離,其中
機器學習(25)之K-Means聚類演算法詳解
微信公眾號 關鍵字全網搜尋最新排名 【機器學習演算法】:排名第一 【機器學習】:排名第一 【Python】:排名第三 【演算法】:排名第四 前言 K-Means演算法是無監督的聚類演算法,它實現起來比較簡單,聚類效果也不錯,因此應用很廣泛。K-Means演算法有大量的變體,本文就從最傳統的K-Means演算