9.機器學習sklearn-----嶺迴歸及其應用例項
阿新 • • 發佈:2019-02-08
1.基本概念
對於一般地線性迴歸問題,引數的求解採用的是最小二乘法,其目標函式如下:
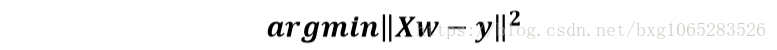
引數w的求解,也可以使用如下矩陣方法進行:
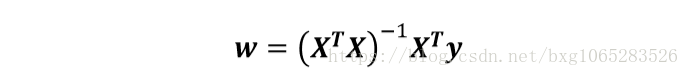
對於矩陣X,若某些列線性相關性較大(即訓練樣本中某些屬性線性相關),就會導致,就會導致XTX的值接近0,在計算(XTX)-1時就會出現不穩定性:
結論:傳統的基於最小二乘的線性迴歸法缺乏穩定性。

嶺迴歸(ridge regression)是一種專用於共線性資料分析的有偏估計迴歸方法,是一種改良的最小二乘估計法,對某些資料的擬合要強於最小二乘法。
在sklearn庫中,可以使用sklearn.linear_model.Ridge呼叫嶺迴歸模型,其 主要引數有:
• alpha:正則化因子,對應於損失函式中的α
• fit_intercept:表示是否計算截距,
• solver:設定計算引數的方法,可選引數‘auto’、‘svd’、‘sag’等
2.例項
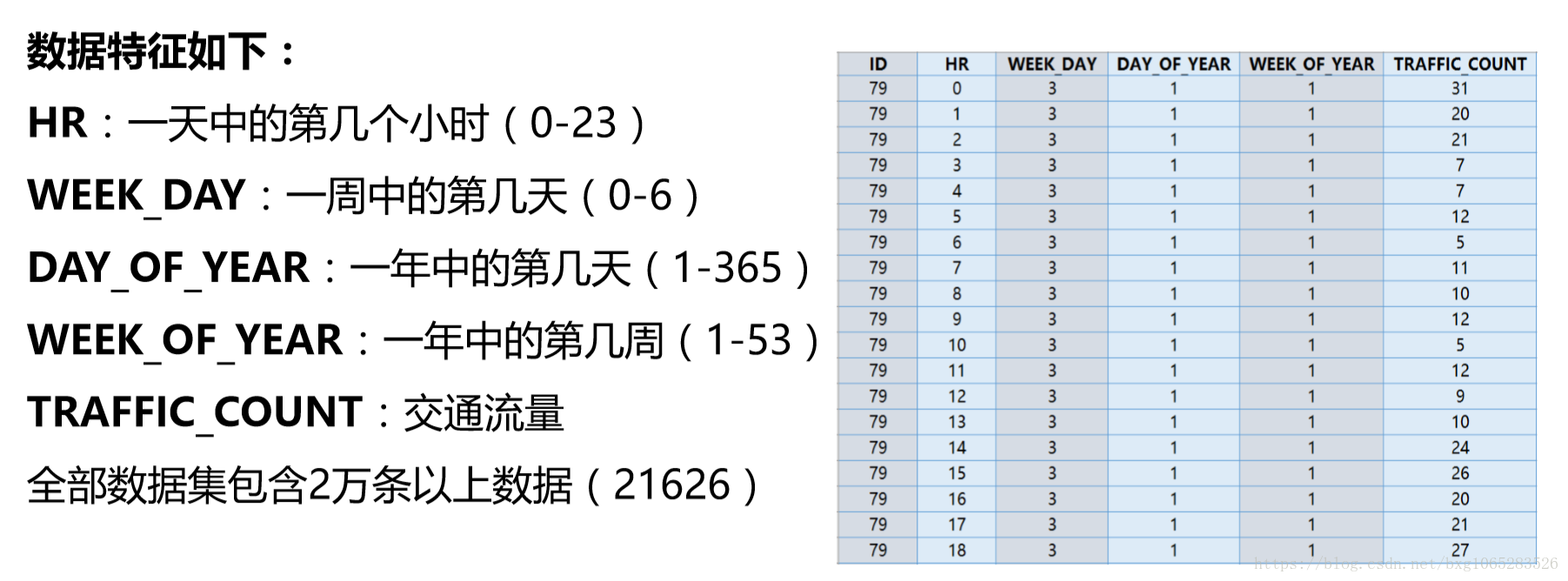
資料介紹: 資料為某路口的交通流量監測資料,記錄全年小時級別的車流量。
實驗目的: 根據已有的資料建立多項式特徵,使用嶺迴歸模型代替一般的線性模型,對車流量的資訊進行多項式迴歸。
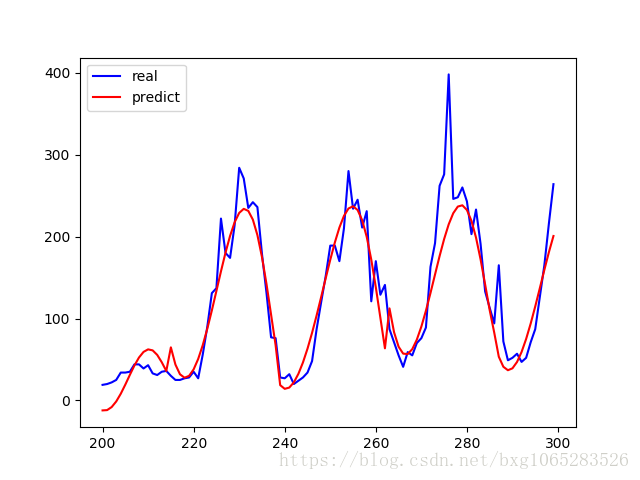
import numpy as np import pandas as pd #通過sklearn.linermodel載入嶺迴歸方法 from sklearn.linear_model importRidge from sklearn import model_selection #載入交叉驗證模組 import matplotlib.pyplot as plt from sklearn.preprocessing import PolynomialFeatures #使用numpy的方法從txt檔案中載入資料 a=pd.read_csv('data.csv') data=np.array(a) #使用plt展示車流量資訊 plt.plot(data[:,5]) plt.show() #X用於儲存0-5維資料,即屬性 X=data[:,1:5] #y用於儲存第6維資料,即車流量 y=data[:,5] #用於建立最高次數6次方的的多項式特徵,多次試驗後決定採用6次 poly =PolynomialFeatures(6) #X為建立的多項式特徵 X=poly.fit_transform(X) #將所有資料劃分為訓練集和測試集,test_size表示測試集的比例, #random_state是隨機數種子 train_set_X,test_set_X,train_set_y,test_set_y=\ model_selection.train_test_split(X,y,test_size=0.3,random_state=0) #建立迴歸器,並進行訓練 #建立嶺迴歸例項 clf =Ridge(alpha=1.0,fit_intercept=True) #呼叫fit函式使用訓練集訓練迴歸器 clf.fit(train_set_X,train_set_y) #利用測試集計算迴歸曲線的擬合優度,clf.score返回值為0.7375擬合優度, # 用於評價擬合好壞,最大為1,無最小值, #當對所有輸入都輸 出同一個值時,擬合優度為0。 clf.score(test_set_X,test_set_y) start =200 #花一段200到300範圍內的擬合曲線 end =300 y_pre =clf.predict(X) #是呼叫predict函式的擬合值 time =np.arange(start,end) plt.plot(time,y[start:end],'b',label="real") plt.plot(time,y_pre[start:end],'r',label='predict') plt.legend(loc='upper left') plt.show()
結果:
分析結論:預測值和實際值的 走勢大致相同