
Android 從零學資料結構與演算法(3)——HashMap和LinkedHashMap
本部落格的原創文章,都是本人平時學習所做的筆記,不做商業用途,如有侵犯您的智慧財產權和版權問題,請通知本人,本人會即時做出處理刪除文章。
- HashMap
基於雜湊表(散列表)的Map介面的實現,允許使用null鍵和null值,HashMap是非執行緒安全的,資料元素存取迭代是無序,順便提一下HashTable,HashTable是執行緒安全的,除了執行緒安全和null鍵值的區別,HashMap和HashTable大致相同。

上圖是雜湊表的結構圖,這種表結構查詢效率高,如果我們把0-15的順序線表的每個地址看成一個"桶",而下標是"桶"的編號,我們通過計算key的hash值“與”上線性表的長度得到得到0-15的值,然後將value放入對應的"桶"內,這樣我們查詢的時候不用遍歷所有的元素,直接去對應的桶裡面查詢就可以了。
下面我們一起看HashMap的原始碼,我是用Android studio檢視的api25的原始碼,不同api版本原始碼會有不同,首先來看看成員變數。
//最少容量 static final int DEFAULT_INITIAL_CAPACITY = 4; //最大容量 static final int MAXIMUM_CAPACITY = 1 << 30; //擴容因子(當容量到75%的時候就要開始擴容了) static final float DEFAULT_LOAD_FACTOR = 0.75f; //空表 static final HashMapEntry<?,?>[] EMPTY_TABLE = {}; //鍵值對的陣列 transient HashMapEntry<K,V>[] table = (HashMapEntry<K,V>[]) EMPTY_TABLE; //非空元素的長度 transient int size; //容量 int threshold; //擴容因子相關 final float loadFactor = DEFAULT_LOAD_FACTOR //操作計數器 transient int modCount;
我們再來看看put方法:
public V put(K key, V value) { //儲存key為null的值,如果之前有值就覆蓋 if (key == null) return putForNullKey(value); //獲取key的hash值 int hash = sun.misc.Hashing.singleWordWangJenkinsHash(key); //通過hash&(length-1)得到元素長度內的值,也就是"桶"的下標,(&運算不熟悉的自行百度) int i = indexFor(hash, table.length); //通過桶的下標,遍歷"桶"裡面的元素(需要看一下HashMapEntry的實現),如果hash值相同,key相等,那就覆蓋value,返回舊的value for (HashMapEntry<K,V> e = table[i]; e != null; e = e.next) { Object k; if (e.hash == hash && ((k = e.key) == key || key.equals(k))) { V oldValue = e.value; e.value = value; e.recordAccess(this); return oldValue; } } //操作計數 modCount++; //如果沒有相同的key,就新增新元素 addEntry(hash, key, value, i); return null; } void addEntry(int hash, K key, V value, int bucketIndex) { //如果元素個數大於等於擴容因子容量(目前容量的75%),那就擴容原來的一倍 if ((size >= threshold) && (null != table[bucketIndex])) { resize(2 * table.length); hash = (null != key) ? sun.misc.Hashing.singleWordWangJenkinsHash(key) : 0; bucketIndex = indexFor(hash, table.length); } //新增資料元素(內容簡單,程式碼就不貼了) createEntry(hash, key, value, bucketIndex); } void resize(int newCapacity) { HashMapEntry[] oldTable = table; int oldCapacity = oldTable.length; //如果達到最大了就不擴容了 if (oldCapacity == MAXIMUM_CAPACITY) { threshold = Integer.MAX_VALUE; return; } HashMapEntry[] newTable = new HashMapEntry[newCapacity]; //通過遍歷,把舊陣列中的元素新增到新陣列中 transfer(newTable); table = newTable; //計算擴容因子容量,loadFactor=0.75f threshold = (int)Math.min(newCapacity * loadFactor, MAXIMUM_CAPACITY + 1); }
void transfer(HashMapEntry[] newTable) {
int newCapacity = newTable.length;
//雙層迴圈遍歷把元素新增到新數組裡面,因為indexFor()方法中的leng變了,
//"桶"的下標就有可能變,所以需要遍歷全部元素,通過key的hash值重新計算桶的下標
for (HashMapEntry<K,V> e : table) {
while(null != e) {
HashMapEntry<K,V> next = e.next;
int i = indexFor(e.hash, newCapacity);
e.next = newTable[i];
newTable[i] = e;
e = next;
}
}
}上面是put流程的部分原始碼,還需要自己對照原始碼看一看。如果能把put看明白,get就很簡單了。下面我們看一下remove方法原始碼:
public V remove(Object key) {
Entry<K,V> e = removeEntryForKey(key);
return (e == null ? null : e.getValue());
}
final Entry<K,V> removeEntryForKey(Object key) {
if (size == 0) {
return null;
}
//通過key的hash值獲取"桶"的下標
int hash = (key == null) ? 0 : sun.misc.Hashing.singleWordWangJenkinsHash(key);
int i = indexFor(hash, table.length);
HashMapEntry<K,V> prev = table[i];
HashMapEntry<K,V> e = prev;
//遍歷這個"桶"內的元素
while (e != null) {
HashMapEntry<K,V> next = e.next;
Object k;
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k)))) {
modCount++;
size--;
//只有第一個元素就是要刪除元素的時候prev才會等於e
if (prev == e)
table[i] = next;
else
prev.next = next;
e.recordRemoval(this);
return e;
}
prev = e;
e = next;
}
return e;
}- LinkedHashMap
LinkedHashMap是HashMap的子類,具有HashMap所有特性,只是額外維護一個雙向迴圈連結串列來保持迭代順序,當然,是犧牲了一定的效能。LinkedHashMap支援LRU演算法,LruCache就是基於LinkedHashMap來實現的。
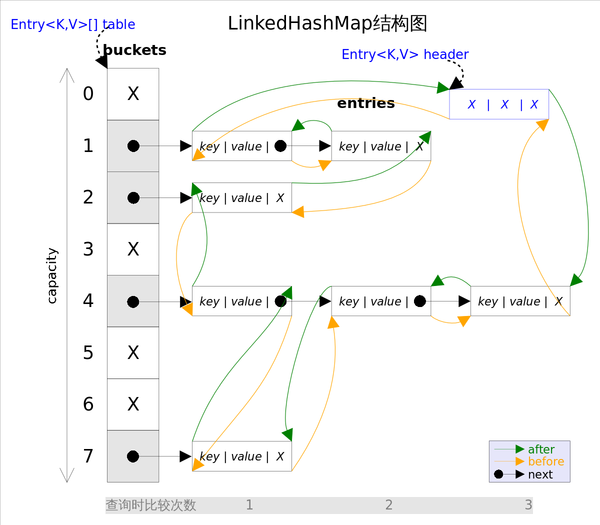
下面一起看看原始碼,看一下僅有的兩個成員變數。
//頭結點
private transient LinkedHashMapEntry<K,V> header;
//如果是true通過訪問排序,如果是false通過插入排序,預設為false
private final boolean accessOrder;如果你去看一下Lrucache的構造方法,你會發現它傳入的就是true。LinkedHashMap裡面並沒有put的方法,只是重寫了addEntry()和createEntry()方法,HashMap的put方法最後會呼叫addEntry()和createEntry()方法。
void addEntry(int hash, K key, V value, int bucketIndex) {
//雙向迴圈連結串列頭節點(header後的節點)如果是按插入排序就是最先插入的元素,
//如果是按訪問排序就是訪問最少的元素,把訪問最少或最老的元素賦值給eldest,
LinkedHashMapEntry<K,V> eldest = header.after;
if (eldest != header) {
boolean removeEldest;
size++;
try {
//removeEldestEntry()方法交給子類實現,通過判斷返回值來刪除eldest元素
//預設返回false,所以不刪除
removeEldest = removeEldestEntry(eldest);
} finally {
size--;
}
//刪除最少或最老的元素
if (removeEldest) {
removeEntryForKey(eldest.key);
}
}
super.addEntry(hash, key, value, bucketIndex);
}
void createEntry(int hash, K key, V value, int bucketIndex) {
//取出陣列中存的節點
HashMapEntry<K,V> old = table[bucketIndex];
//建立新節點
LinkedHashMapEntry<K,V> e = new LinkedHashMapEntry<>(hash, key, value, old);
//將新節點放在陣列中
table[bucketIndex] = e;
//將新元素節點新增到雙向迴圈連結串列,為什麼傳header呢,因為要把元素插入在header前面
//header前面是尾節點,header後面是頭節點,新新增的元素需要新增到尾節點
e.addBefore(header);
size++;
}
private void addBefore(LinkedHashMapEntry<K,V> existingEntry) {
//將新元素新增到header前面的尾節點,也就是header和之前的尾節點之間插入新元素節點
after = existingEntry;
before = existingEntry.before;
before.after = this;
after.before = this;
}上面就是LinkedHashMap新增新元素的核心程式碼。配合結構圖能更好的理解。每次新新增的元素都新增到header的前面,也就是尾節點,而header的後面的節點就是頭結點,所以在Lru演算法中,無論是訪問排序還是插入排序,需要刪除元素時,都是刪除頭結點。
public V get(Object key) {
//呼叫父類的獲取元素方法
LinkedHashMapEntry<K,V> e = (LinkedHashMapEntry<K,V>)getEntry(key);
if (e == null)
return null;
//記錄訪問
e.recordAccess(this);
return e.value;
}
void recordAccess(HashMap<K,V> m) {
LinkedHashMap<K,V> lm = (LinkedHashMap<K,V>)m;
//如果是訪問排序,就把訪問的資料元素放在尾節點
if (lm.accessOrder) {
//記錄操作
lm.modCount++;
//刪除自己
remove();
//把自己新增到header前面的尾節點
addBefore(lm.header);
}
}上面試get()的核心程式碼,如果是插入排序,只需要遍歷查詢就可以了,如果是訪問排序,就需要把訪問的元素放在尾節點。
public Map.Entry<K, V> eldest() {
Entry<K, V> eldest = header.after;
return eldest != header ? eldest : null;
}eldest()方法是返回頭節點。以上就是LinkedHashMap比較核心的原始碼了。
- 下篇預告
下節我們一起學習樹。
------------------------------------------------
想要繼續跟我一起學習一起成長,請關注我的公眾號:程式設計師持續發展方案
