
Python3 + Scrapy 爬取豆瓣評分資料存入Mysql與MongoDB資料庫。
阿新 • • 發佈:2019-02-08
首先我們先抓包分析一下,可以看到我們想要的每一頁的全部資料都在"article"下。
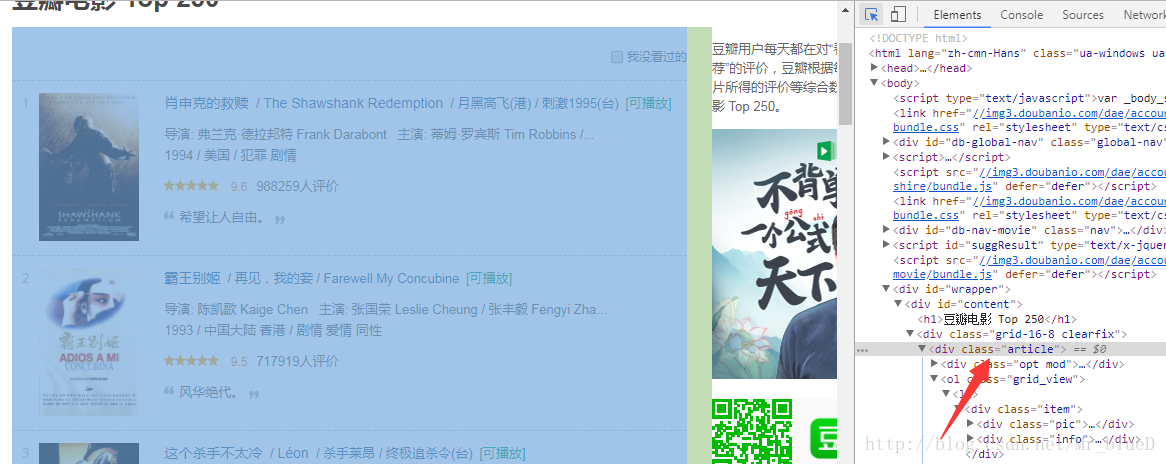
而其中每一部的電影的資料可以看到在"info"下。
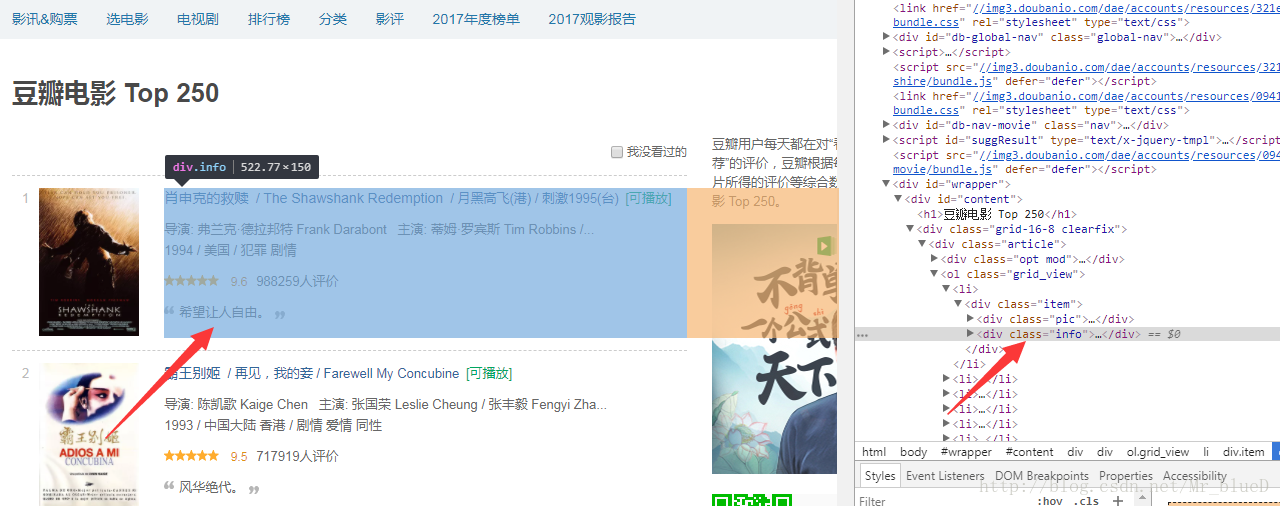
所以我們只要在info下找到自己的目標資料並想好匹配方法即可,本文使用的是xpath,其實也可以在spiders中匯入pyquery或者BeautifulSoup來進行匹配,當然正則也是可以的。現在我們去找到目標資料。
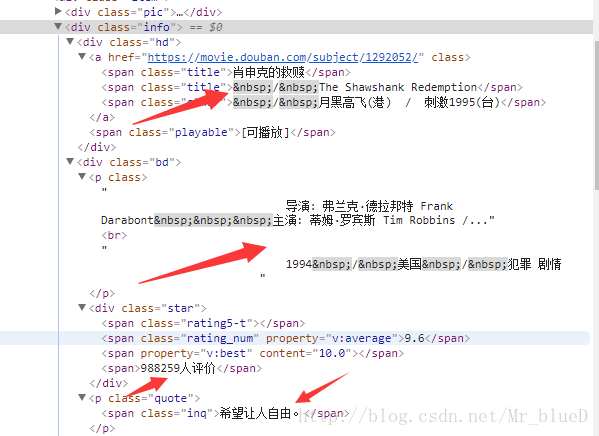
這些便是我們的目標資料,接下來便可以動手爬取了。
注意:有些目標資料有時候會為空,還有記得去掉資料中多餘的空格和換行。
1.編寫item
import scrapy
class MovieItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
# 電影名
title = scrapy.Field()
# 電影資訊
movieInfo = scrapy.Field()
# 評分
star = scrapy.Field()
# 影評
quote = scrapy.Field()
# 評分人數
number = scrapy.Field()
pass 2.編寫Spider
from scrapy.spiders import Spider
from scrapy.http import Request
from scrapy.selector import Selector
from Mycrawl.items import MovieItem
import requests
import time
class MovieSpider(Spider):
# 爬蟲名字,重要
name = 'movie'
# 反爬措施
headers = {'User-Agent':'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/64.0.3282.119 Safari/537.36'}
url = 'https://movie.douban.com/top250'
#start_urls = ['movie.douban.com']
def start_requests(self):
# url = 'https://movie.douban.com/top250'
yield Request(self.url, headers=self.headers, callback=self.parse)
def parse(self, response):
item = MovieItem()
selector = Selector(response)
movies = selector.xpath('//div[@class="info"]')
for movie in movies:
name = movie.xpath('div[@class="hd"]/a/span/text()').extract()
message = movie.xpath('div[@class="bd"]/p/text()').extract()
star = movie.xpath('div[@class="bd"]/div[@class="star"]/span[@class="rating_num"]/text()').extract()
number = movie.xpath('div[@class="bd"]/div[@class="star"]/span/text()').extract()
quote = movie.xpath('div[@class="bd"]/p[@class="quote"]/span/text()').extract()
if quote:
quote = quote[0]
else:
quote = ''
item['movie_name'] = ''.join(name)
item['movie_message'] = ';'.join(message).replace(' ','').replace('\n','')
item['movie_star'] = star[0]
item['number'] = number[1].split('人')[0]
item['movie_quote'] = quote
yield item
nextpage = selector.xpath('//span[@class="next"]/link/@href').extract()
time.sleep(3)
if nextpage:
nextpage = nextpage[0]
yield Request(self.url+str(nextpage), headers=self.headers, callback=self.parse) 3.編寫Piplines與資料庫進行連線
Mysql
import pymysql
import pymongo
'''
class MycrawlPipeline(object):
def process_item(self, item, spider):
return item
'''
class MoviePipeline(object):
def __init__(self):
# 連線資料庫
self.conn = pymysql.connect(host='127.0.0.1', port=3306, user='root', passwd='1likePython',
db='TESTDB', charset='utf8')
# 建立遊標物件
self.cursor = self.conn.cursor()
self.cursor.execute('truncate table Movie')
self.conn.commit()
def process_item(self, item, spider):
try:
self.cursor.execute("insert into Movie (name,movieInfo,star,number,quote) \
VALUES (%s,%s,%s,%s,%s)", (item['movie_name'],item['movie_message'],item['movie_star'],
item['number'], item['movie_quote']))
self.conn.commit()
except pymysql.Error:
print("Error%s,%s,%s,%s,%s" % (item['movie_name'],item['movie_message'],item['movie_star'],
item['number'], item['movie_quote']))
return item MongoDB
class MoviePipeline(object):
def __init__(self):
# 連線資料庫
self.client = pymongo.MongoClient(host='127.0.0.1', port=27017)
self.test = self.client['TESTDB']
self.post = self.test['movie']
def process_item(self, item, spider):
data = dict(item)
self.post.insert(data)
return item4.編寫setting
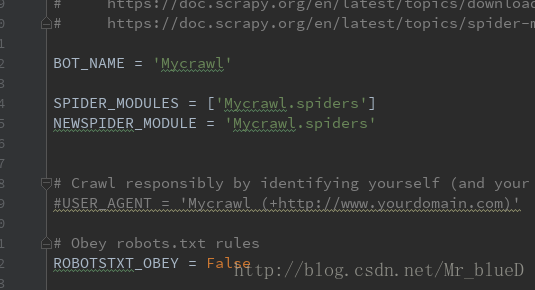
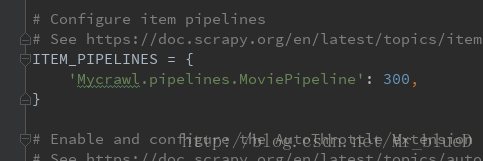
5.爬取存入Mysql資料庫
在爬蟲執行前需要建立資料庫表格,有兩種方法可以建立,一種是可以通過命令列進入資料庫輸入建立表命令建立;另一種是通過Python進行建立。
在這裡我說說第二種,建立一個.py檔案,然後在裡面編寫
import pymysql
db = pymysql.connect(host='127.0.0.1', port=3306, user='root', passwd='你的密碼', db='TESTDB', charset='utf8')
cursor = db.cursor()
cursor.execute('DROP TABLE IF EXISTS BOOK')
sql = """CREATE TABLE BOOK(
id INT NOT NULL PRIMARY KEY AUTO_INCREMENT COMMENT '自增 id',
book_name VARCHAR(1024) NOT NULL COMMENT '小說名',
author VARCHAR(1024) NOT NULL COMMENT '小說作者',
book_type VARCHAR(1024) NULL NULL COMMENT '小說型別',
book_state VARCHAR(1024) DEFAULT NULL COMMENT '小說狀態',
book_update VARCHAR(1024) DEFAULT NULL COMMENT '小說更新',
book_time VARCHAR(1024) DEFAULT NULL COMMENT '更新時間',
new_href VARCHAR(1024) DEFAULT NULL COMMENT '最新一章',
book_intro VARCHAR(1024) DEFAULT NULL COMMENT '小說簡介',
createtime DATETIME DEFAULT CURRENT_TIMESTAMP COMMENT '新增時間'
)"""
cursor.execute(sql)
db.close()
這樣,就完成了建立一個表了。
關於更多的Mysql資料庫操作命令,可以參考 http://blog.csdn.net/Mr_blueD/article/details/79344462
在建立的scrpay專案的資料夾下輸入
scrapy crawl movie(這個movie是我在Spider裡寫的爬蟲名)
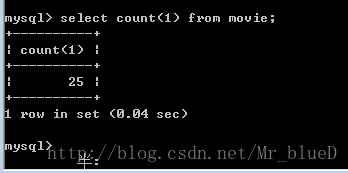
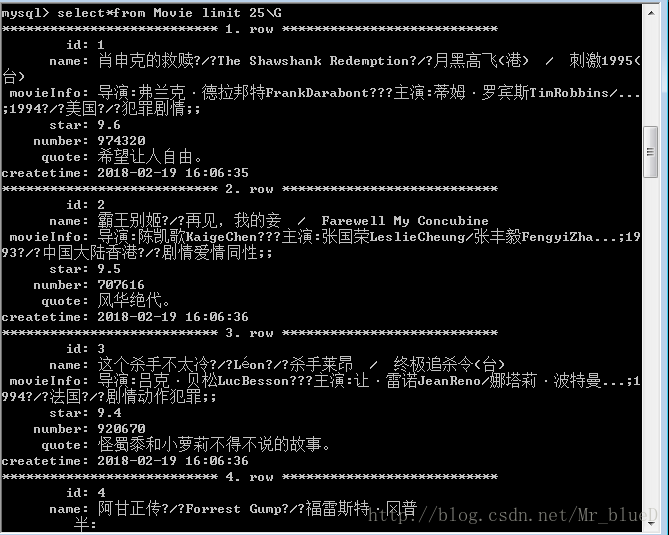
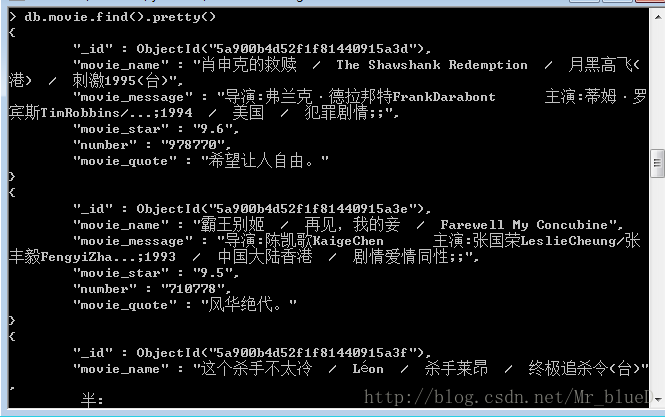
6.結果
Mysql
Mongo
另有爬取起點小說網資料的Scrapy實戰,請前往 http://blog.csdn.net/Mr_blueD/article/details/79343349