
Python3 +Scrapy 爬取騰訊控股股票資訊存入資料庫中
阿新 • • 發佈:2019-01-10
目標網站:http://quotes.money.163.com/hkstock/cwsj_00700.html
每支股票都有四個資料表
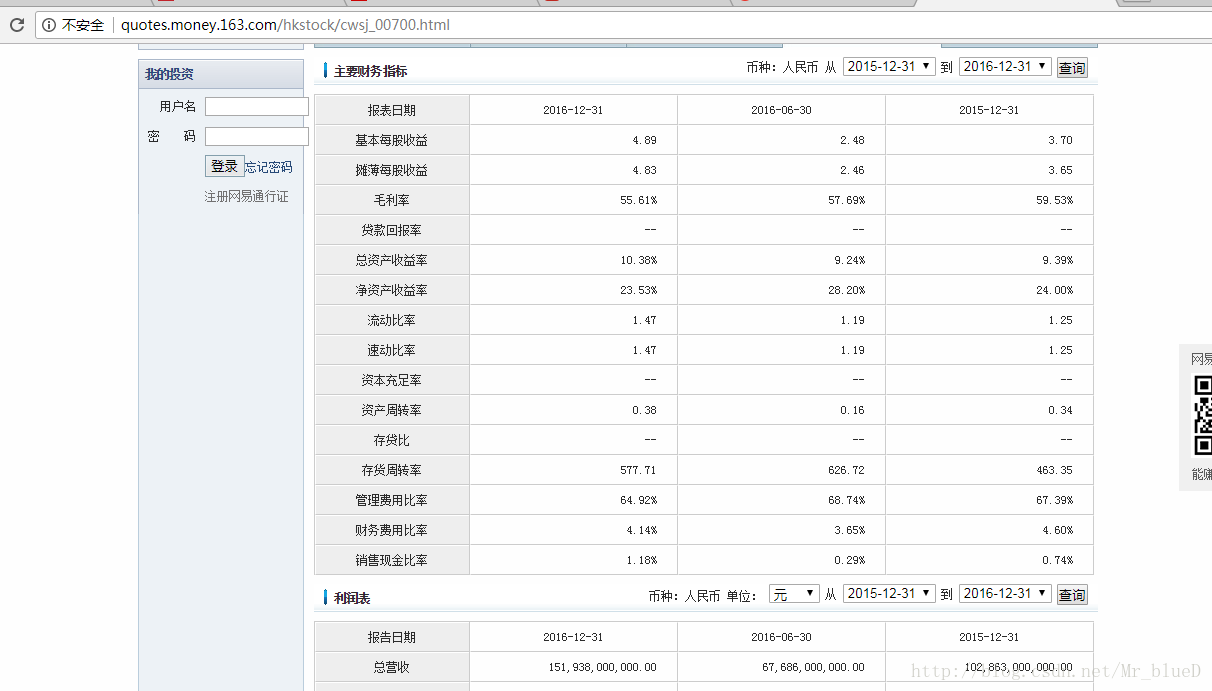
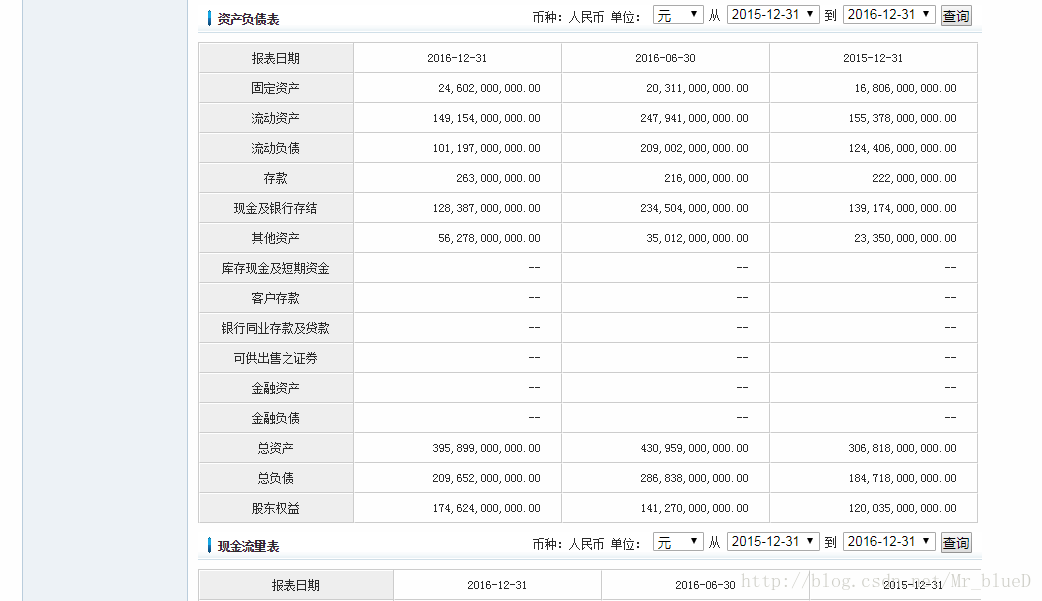
找到這四個資料表的資訊所在
資料名
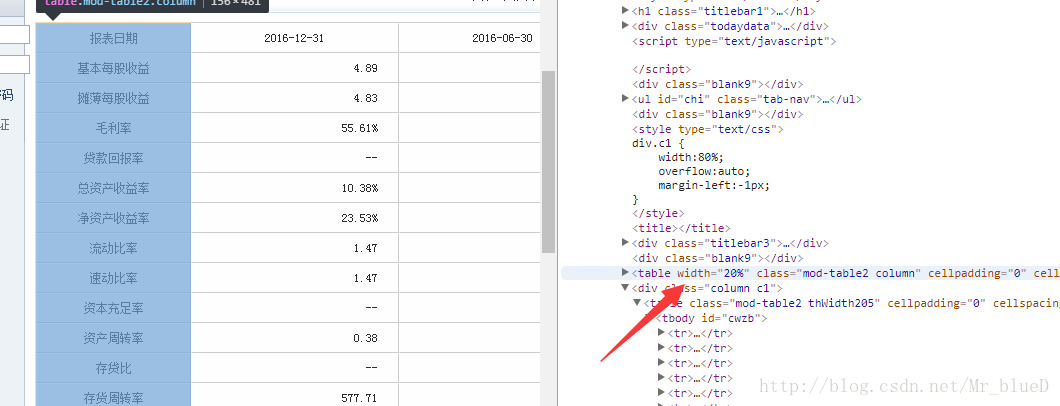
第一條到第三條資料所在
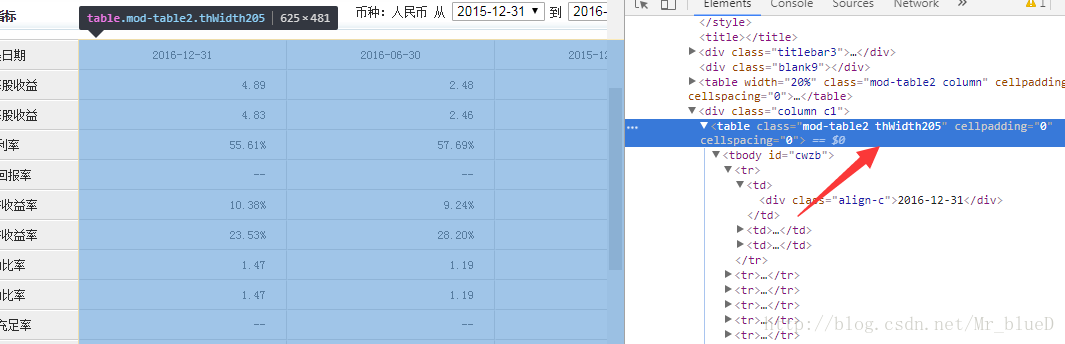
其他三個表也是這樣子尋找,找到資料後,就可以動手爬取了。
於2018\3\17 重寫。
一.Item
# 騰訊控股股票資訊 class GupiaoItem(scrapy.Item): # 資料標題 title = scrapy.Field() # 資料名 dataname = scrapy.Field() # 第一條資料 fristdata = scrapy.Field() # 第二條資料 secondata = scrapy.Field() # 第三條資料 thridata = scrapy.Field()
二.Piplines
資料庫建立
import pymysql db = pymysql.connect(host='127.0.0.1', port=3306, user='root', passwd='你的密碼', db='資料庫名', charset='utf8') cursor = db.cursor() cursor.execute('DROP TABLE IF EXISTS gupiao') sql = """CREATE TABLE gupiao( title VARCHAR(1024) NOT NULL COMMENT '資料標題', dataname VARCHAR(1024) NOT NULL COMMENT '資料名', fristdata VARCHAR(1024) DEFAULT NULL COMMENT '第一條資料', secondata VARCHAR(1024) DEFAULT NULL COMMENT '第二條資料', thridata VARCHAR(1024) DEFAULT NULL COMMENT '第三條資料', createtime DATETIME DEFAULT CURRENT_TIMESTAMP COMMENT '建立時間' )""" cursor.execute(sql) db.close()
pipline編寫
import pymysql class MycrawlPipeline(object): def __init__(self): # 連線資料庫 self.conn = pymysql.connect(host='127.0.0.1', port=3306, user='root', passwd='你的密碼', db='資料庫名', charset='utf8') # 建立遊標物件 self.cursor = self.conn.cursor() self.conn.commit() def process_item(self, item, spider): # 將item中的資料插入到資料庫中 try: self.cursor.execute("insert into GUPIAO (title, dataname,fristdata,secondata,thridata) \ VALUES (%s,%s,%s,%s,%s)", (item['title'], item['dataname'], item['fristdata'], item['secondata'], item['thridata'])) self.conn.commit() except pymysql.Error: print("Error%s,%s,%s,%s,%s" % ( item['title'], item['dataname'], item['fristdata'], item['secondata'], item['thridata'])) return item
三.Spiders
# -*-coding:utf-8-*-
from scrapy.spiders import Spider
from scrapy.http import Request
from scrapy.selector import Selector
from Mycrawl.items import GupiaoItem
class MovieSpider(Spider):
# 爬蟲名字,重要
name = 'gupiao'
allow_domains = ['quotes.money.163.com']
start_urls = ['http://quotes.money.163.com/hkstock/cwsj_00700.html']
def parse(self, response):
item = GupiaoItem()
selector = Selector(response)
datas = selector.xpath('//table[@class="mod-table2 column"]')
contents = selector.xpath('//table[@class="mod-table2 thWidth205"]')
titles = selector.xpath('//div[@class="titlebar3"]/span/text()').extract()
# 共四張表,i 從 0 開始
for i, each1 in enumerate(contents):
# 第 i+1 張表的第二列所有資料
content1 = each1.xpath('tbody/tr/td[1]/div')
# 第 i+1 張表的第三列所有資料
content2 = each1.xpath('tbody/tr/td[2]/div')
# 第 i+1 張表的第四列所有資料
content3 = each1.xpath('tbody/tr/td[3]/div')
# 第 i+1 張表的第一列所有資料
data = datas[i].xpath('tr/td')
for j, each2 in enumerate(data):
name = each2.xpath('text()').extract()
frist = content1[j].xpath('text()').extract()
second = content2[j].xpath('text()').extract()
thrid = content3[j].xpath('text()').extract()
item['title'] = titles[i]
item['dataname'] = name[0]
item['fristdata'] = frist[0]
item['secondata'] = second[0]
item['thridata'] = thrid[0]
yield item
四.結果顯示
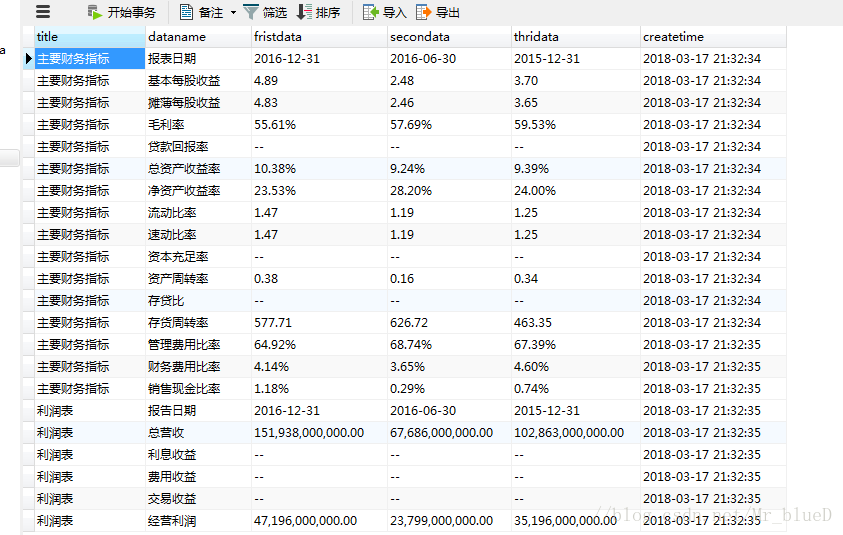
到此我們的爬蟲就搭建成功了。
五.重寫前的程式碼。
一.Item
class GupiaoItem(scrapy.Item):
# 資料名
dataname = scrapy.Field()
# 第一條資料
fristdata = scrapy.Field()
# 第二條資料
secondata = scrapy.Field()
# 第三條資料
thridata = scrapy.Field()二.Piplines
這裡對應了四個爬蟲,Gupiao0,Gupiao1,Gupiao2,與Gupiao3,所以對應的Spiders也需要四個,
分別爬取股票資訊的四個表。
import pymysql
class MycrawlPipeline(object):
def __init__(self):
# 連線資料庫
self.conn = pymysql.connect(host='127.0.0.1', port=3306, user='root', passwd='1likePython',
db='TESTDB', charset='utf8')
# 建立遊標物件
self.cursor = self.conn.cursor()
self.conn.commit()
def process_item(self, item, spider):
if spider.name == 'Gupiao0':
try:
self.cursor.execute("insert into Gupiao (dataname,fristdata,secondata,thridata) \
VALUES (%s,%s,%s,%s)", (item['dataname'], item['fristdata'], item['secondata'], item['thridata']))
self.conn.commit()
except pymysql.Error:
print("Error%s,%s,%s,%s" % (item['dataname'], item['fristdata'], item['secondata'], item['thridata']))
return item
if spider.name == 'Gupiao1':
try:
self.cursor.execute("insert into Gupiao (dataname,fristdata,secondata,thridata) \
VALUES (%s,%s,%s,%s)", (item['dataname'], item['fristdata'], item['secondata'], item['thridata']))
self.conn.commit()
except pymysql.Error:
print("Error%s,%s,%s,%s" % (item['dataname'], item['fristdata'], item['secondata'], item['thridata']))
return item
if spider.name == 'Gupiao2':
try:
self.cursor.execute("insert into Gupiao (dataname,fristdata,secondata,thridata) \
VALUES (%s,%s,%s,%s)", (item['dataname'], item['fristdata'], item['secondata'], item['thridata']))
self.conn.commit()
except pymysql.Error:
print("Error%s,%s,%s,%s" % (item['dataname'], item['fristdata'], item['secondata'], item['thridata']))
return item
if spider.name == 'Gupiao3':
try:
self.cursor.execute("insert into Gupiao (dataname,fristdata,secondata,thridata) \
VALUES (%s,%s,%s,%s)", (item['dataname'], item['fristdata'], item['secondata'], item['thridata']))
self.conn.commit()
except pymysql.Error:
print("Error%s,%s,%s,%s" % (item['dataname'], item['fristdata'], item['secondata'], item['thridata']))
return item
三.Spiders
Gupiao0
# -*-coding:utf-8-*-
from scrapy.spiders import Spider
from scrapy.http import Request
from scrapy.selector import Selector
from Mycrawl.items import GupiaoItem
import requests
class MovieSpider(Spider):
# 爬蟲名字,重要
name = 'gupiao0'
# 反爬措施
# headers = {'User-Agent':'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/64.0.3282.119 Safari/537.36'}
# url = 'https://movie.douban.com/top250'
allow_domains = ['quotes.money.163.com']
start_urls = ['http://quotes.money.163.com/hkstock/cwsj_00700.html']
'''
def start_requests(self):
# url = 'https://movie.douban.com/top250'
yield Request(self.url, headers=self.headers, callback=self.parse)
'''
def parse(self, response):
item = GupiaoItem()
selector = Selector(response)
datas1 = selector.xpath('//table[@class="mod-table2 column"]')
contents = selector.xpath('//table[@class="mod-table2 thWidth205"]')
content1 = contents[0].xpath('tbody/tr/td[1]/div')
content2 = contents[0].xpath('tbody/tr/td[2]/div')
content3 = contents[0].xpath('tbody/tr/td[3]/div')
data = datas1[0].xpath('tr/td')
for i, each in enumerate(data):
name = each.xpath('text()').extract()
frist = content1.xpath('text()').extract()
second = content2.xpath('text()').extract()
thrid = content3.xpath('text()').extract()
item['dataname'] = name[0]
item['fristdata'] = frist[0]
item['secondata'] = second[0]
item['thridata'] = thrid[0]
yield item
'''
nextpage = selector.xpath('//span[@class="next"]/link/@href').extract()
if nextpage:
nextpage = nextpage[0]
yield Request(self.url+str(nextpage), headers=self.headers, callback=self.parse)
'''Gupiao1
# -*-coding:utf-8-*-
from scrapy.spiders import Spider
from scrapy.http import Request
from scrapy.selector import Selector
from Mycrawl.items import GupiaoItem
import requests
class MovieSpider(Spider):
# 爬蟲名字,重要
name = 'gupiao1'
# 反爬措施
# headers = {'User-Agent':'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/64.0.3282.119 Safari/537.36'}
# url = 'https://movie.douban.com/top250'
allow_domains = ['quotes.money.163.com']
start_urls = ['http://quotes.money.163.com/hkstock/cwsj_00700.html']
'''
def start_requests(self):
# url = 'https://movie.douban.com/top250'
yield Request(self.url, headers=self.headers, callback=self.parse)
'''
def parse(self, response):
item = GupiaoItem()
selector = Selector(response)
datas1 = selector.xpath('//table[@class="mod-table2 column"]')
contents = selector.xpath('//table[@class="mod-table2 thWidth205"]')
content1 = contents[1].xpath('tbody/tr/td[1]/div')
content2 = contents[1].xpath('tbody/tr/td[2]/div')
content3 = contents[1].xpath('tbody/tr/td[3]/div')
data = datas1[1].xpath('tr/td')
for i, each in enumerate(data):
name = each.xpath('text()').extract()
frist = content1.xpath('text()').extract()
second = content2.xpath('text()').extract()
thrid = content3.xpath('text()').extract()
item['dataname'] = name[0]
item['fristdata'] = frist[0]
item['secondata'] = second[0]
item['thridata'] = thrid[0]
yield item
'''
nextpage = selector.xpath('//span[@class="next"]/link/@href').extract()
if nextpage:
nextpage = nextpage[0]
yield Request(self.url+str(nextpage), headers=self.headers, callback=self.parse)
'''
Gupiao2
# -*-coding:utf-8-*-
from scrapy.spiders import Spider
from scrapy.http import Request
from scrapy.selector import Selector
from Mycrawl.items import GupiaoItem
import requests
class MovieSpider(Spider):
# 爬蟲名字,重要
name = 'gupiao2'
# 反爬措施
# headers = {'User-Agent':'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/64.0.3282.119 Safari/537.36'}
# url = 'https://movie.douban.com/top250'
allow_domains = ['quotes.money.163.com']
start_urls = ['http://quotes.money.163.com/hkstock/cwsj_00700.html']
'''
def start_requests(self):
# url = 'https://movie.douban.com/top250'
yield Request(self.url, headers=self.headers, callback=self.parse)
'''
def parse(self, response):
item = GupiaoItem()
selector = Selector(response)
datas1 = selector.xpath('//table[@class="mod-table2 column"]')
contents = selector.xpath('//table[@class="mod-table2 thWidth205"]')
content1 = contents[2].xpath('tbody/tr/td[1]/div')
content2 = contents[2].xpath('tbody/tr/td[2]/div')
content3 = contents[2].xpath('tbody/tr/td[3]/div')
data = datas1[2].xpath('tr/td')
for i, each in enumerate(data):
name = each.xpath('text()').extract()
frist = content1.xpath('text()').extract()
second = content2.xpath('text()').extract()
thrid = content3.xpath('text()').extract()
item['dataname'] = name[0]
item['fristdata'] = frist[0]
item['secondata'] = second[0]
item['thridata'] = thrid[0]
yield item
'''
nextpage = selector.xpath('//span[@class="next"]/link/@href').extract()
if nextpage:
nextpage = nextpage[0]
yield Request(self.url+str(nextpage), headers=self.headers, callback=self.parse)
'''
Gupiao3
# -*-coding:utf-8-*-
from scrapy.spiders import Spider
from scrapy.http import Request
from scrapy.selector import Selector
from Mycrawl.items import GupiaoItem
import requests
class MovieSpider(Spider):
# 爬蟲名字,重要
name = 'gupiao3'
# 反爬措施
# headers = {'User-Agent':'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/64.0.3282.119 Safari/537.36'}
# url = 'https://movie.douban.com/top250'
allow_domains = ['quotes.money.163.com']
start_urls = ['http://quotes.money.163.com/hkstock/cwsj_00700.html']
'''
def start_requests(self):
# url = 'https://movie.douban.com/top250'
yield Request(self.url, headers=self.headers, callback=self.parse)
'''
def parse(self, response):
item = GupiaoItem()
selector = Selector(response)
datas1 = selector.xpath('//table[@class="mod-table2 column"]')
contents = selector.xpath('//table[@class="mod-table2 thWidth205"]')
content1 = contents[3].xpath('tbody/tr/td[1]/div')
content2 = contents[3].xpath('tbody/tr/td[2]/div')
content3 = contents[3].xpath('tbody/tr/td[3]/div')
data = datas1[3].xpath('tr/td')
for i, each in enumerate(data):
name = each.xpath('text()').extract()
frist = content1.xpath('text()').extract()
second = content2.xpath('text()').extract()
thrid = content3.xpath('text()').extract()
item['dataname'] = name[0]
item['fristdata'] = frist[0]
item['secondata'] = second[0]
item['thridata'] = thrid[0]
yield item
'''
nextpage = selector.xpath('//span[@class="next"]/link/@href').extract()
if nextpage:
nextpage = nextpage[0]
yield Request(self.url+str(nextpage), headers=self.headers, callback=self.parse)
'''分成四個爬蟲只是為了存入資料庫後的資料簡介明瞭,而且後面三個和第一個相比只是修改了一點點,直接複製貼上修改一下即可,並不特別費力。
四.結果顯示
主要財務指標
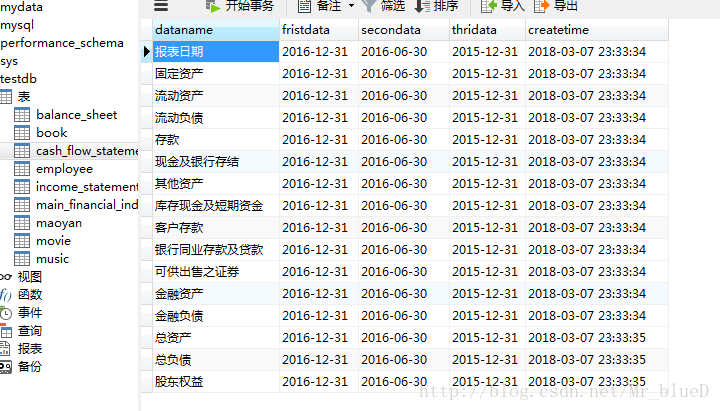
利潤表

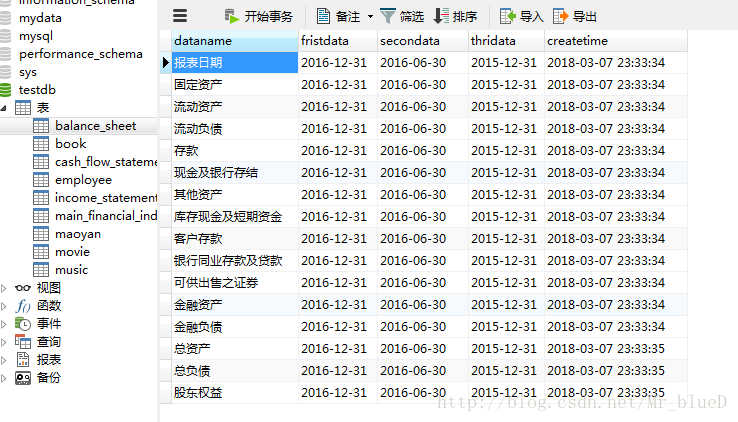
資產負債表
現金流量表
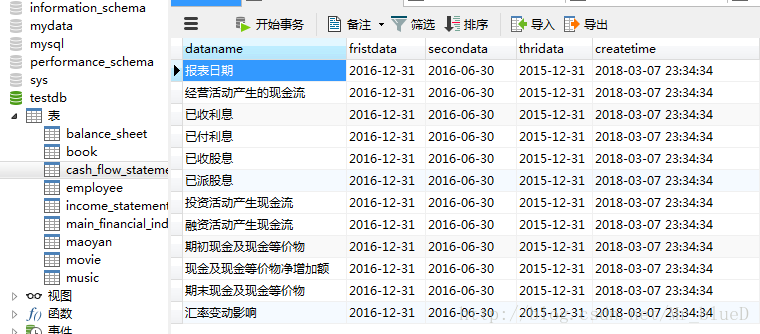
到此我們的爬蟲就搭建成功了。