
大資料平臺運維-----Kerberos環境下Hive及Impala監控指令碼的開發
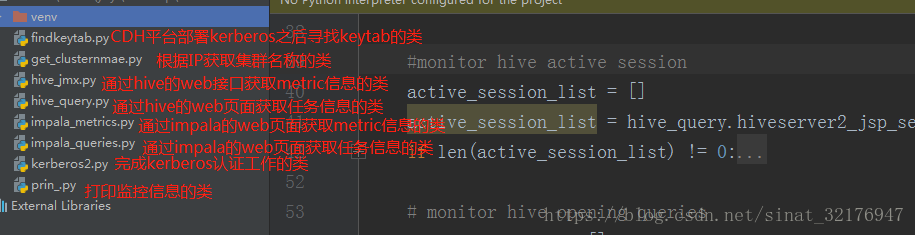
一、工程目錄
二、原理解析
Hive和Impala是兩個最常用的大資料查詢工具,他們的主要區別是Hive適合對實時性要求不太高的業務,對資源的要求較低;而Impala的由於採用了全新的架構,處理速度非常的快,但同樣的也對資源消耗比較大,適合實時性要求高的業務。
在我測試過程中發現,有些時候,即使通過shell命令來檢測,發現Hive或者Impala的程序正在執行,但是無法訪問他們的web頁面,其實這也不能算是正常執行的,因為內部還是無法完成任務。利用這一點,我們可以通過爬蟲工具beautifulsoup,獲取Hive和Impala的web頁面的資訊。繼而轉化成字串,丟到grafana裡,即可實現監控功能了。
小弟也是新手一個,程式碼也只是僅僅實現了功能而已,大神看了希望不要見笑哈~~
三、程式碼解析
1、findkeytab.py
import os import re def findkeytab(): pre='/var/run/cloudera-scm-agent/process'#CDH的程序路徑 p = os.listdir(pre) max=l=0 for i in range(len(p)): pattern = re.compile(r'(.*?)hive-HIVESERVER2$')#CDH每次重啟程序會生成新的程序號,這裡匹配最新(大)的程序目錄 ifpattern.match(p[i]): if int(p[i ].split('-')[0])>max: max=int(p[i].split('-')[0]) l=i suf=p[l] return pre+'/'+suf+'/hive.keytab'#拼接出keytab路徑
2、kerberos2.py
import requests import commands import kerberos class KerberosTicket: def __init__(self,service, keytab, pricipal): kt_cmd = 'kinit -kt ' + keytab + ' ' + pricipal#通過命令認證kerberos使用者 (status, output) = commands.getstatusoutput(kt_cmd) if status != 0: print ("kinit ERROR:") print (output) exit() __, krb_context = kerberos.authGSSClientInit(service) kerberos.authGSSClientStep(krb_context, "") self._krb_context = krb_context self.auth_header = ("Negotiate " + kerberos.authGSSClientResponse(krb_context)) def verify_response(self, auth_header): # Handle comma-separated lists of authentication fields for field in auth_header.split(","): kind, __, details = field.strip().partition(" ") if kind.lower() == "negotiate": auth_details = details.strip() break else: raise ValueError("Negotiate not found in %s" % auth_header) # Finish the Kerberos handshake krb_context = self._krb_context if krb_context is None: raise RuntimeError("Ticket already used for verification") self._krb_context = None kerberos.authGSSClientStep(krb_context, auth_details)
3、get_clustername.py
#!/usr/bin/env python def enabled(): return False cluster_dict = { 'cluster1': ["192.168.159.11-13"] #預先定義IP和clustername的對映 } def get_cluster_name(ip):#通過字串的匹配來確定clustername cluster_name = '' for i in range(len(cluster_dict)): cluster_key = cluster_dict.keys()[i] locals()[str(cluster_key)+'_ip_list'] = [] ip_part1_list = [i.split('.')[:3] for i in cluster_dict.get(cluster_key)] ip_part2_list = [i.split('.')[3] for i in cluster_dict.get(cluster_key)] try: ip_part2_list_detail_list=[] for k in range(len(ip_part2_list)): loop_start = int(ip_part2_list[k].split("-")[0]) loop_end = int(ip_part2_list[k].split("-")[1]) ip_part2_list_detail = [x for x in range(loop_start , loop_end + 1)] ip_part2_list_detail_list.append(ip_part2_list_detail) ip_list= zip(ip_part1_list,ip_part2_list_detail_list) for o in range(len(ip_list)): for p in range(len(ip_list[o][1])): locals()[str(cluster_key) + '_ip_list'].append(str(ip_list[o][0][0])+"."+str(ip_list[o][0][1])+"."+str(ip_list[o][0][2])+"."+str(ip_list[o][1][p])) except IndexError: locals()[str(cluster_key) + '_ip_list'].append(str(ip_list[o][0][0]) + "." + str(ip_list[o][0][1]) + "." + str(ip_list[o][0][2]) + "." + str(ip_list[o][1][p])) if ip in locals()[str(cluster_key)+'_ip_list']: cluster_name = str(cluster_key) if cluster_name in cluster_dict.keys(): return cluster_name else: return "null"
4、hive_jmx.py
import requests import kerberos import socket #output all metric value輸出所有資訊,測試用 '''for i in range(len(js['beans'])): prename=js['beans'][i]['name'].split('=')[1] for key in (js['beans'][i]): if key == "modelerType": continue lastname=key name=prename+'.'+lastname timestamp = str(int(time.time())) value = str(js['beans'][i][key]) tag='hive' print name+' '+timestamp+' '+value+' '+tag''' #out put pointed metric value def hiveserver2_jmx(url): #在Hive的metric頁面找到需要的屬性 def jmxana(i, metric_name, value_name): list = [] dict = {} if js['beans'][i]['name'] == "metrics:name=" + metric_name: name = js['beans'][i]['name'].split('=')[1] + '.' + value_name list.append(metric_name) value = str(js['beans'][i][value_name]) list.append(value) list.append(dict) return list #kerbero認證部分 __, krb_context = kerberos.authGSSClientInit("HTTP/[email protected]") kerberos.authGSSClientStep(krb_context, "") negotiate_details = kerberos.authGSSClientResponse(krb_context) headers = {"Authorization": "Negotiate " + negotiate_details} r = requests.get(url, headers=headers, verify=False) hostname = socket.gethostname() js = r.json() jmx_list = [] file = open("/root/test.txt")#這裡將要監控的屬性名稱存在一個檔案裡,通過讀取檔案內容獲取具體要監控的資訊 lines = file.readlines() for i in range(len(js['beans'])): for line in lines: tmp_list = jmxana(i,line.split(' ')[0].strip(),line.split(' ')[1].strip()) if len(tmp_list)!=0: jmx_list.append(tmp_list) file.close() return jmx_list
5、hive_query.py
import requests import kerberos import time from bs4 import BeautifulSoup last_query_list = [] open_query_list = [] active_session_list = [] total_dict = {} latest_query_timestamp=0 #beautifulsoup解析hive的監控頁面,返回html文字 def getsoup(url): __, krb_context = kerberos.authGSSClientInit("HTTP/[email protected]") kerberos.authGSSClientStep(krb_context, "") negotiate_details = kerberos.authGSSClientResponse(krb_context) headers = {"Authorization": "Negotiate " + negotiate_details} r = requests.get(url, headers=headers,verify=False) return BeautifulSoup(r.content,"html5lib") #獲取頁面的session資訊 def hiveserver2_jsp_session(url): soup=getsoup(url) del active_session_list[:] for h2 in soup.findAll('h2'): if h2.string == 'Active Sessions': tab = h2.parent.find('table') for tr in tab.findAll('tr'): list = [] dict = {} count = 0 for td in tr.findAll('td'): if len(tr.findAll('td')) == 1: td_num = tr.find('td').string.split(':')[1] global total_dict total_dict['Total number of sessions'] = td_num else: if count == 0: dict['UserName'] = td.getText().strip() elif count == 1: dict['IP'] = td.getText().strip() elif count == 2: dict['OperationCount'] = td.getText().strip() else: list.append(td.getText().strip()) count+=1 if len(dict)!=0: list.append(dict) if len(list) != 0: active_session_list.append(list) return active_session_list #獲取正在執行的任務資訊 def hiveserver2_jsp_open(url): soup = getsoup(url) del open_query_list[:] for h2 in soup.findAll('h2'): if h2.string == 'Open Queries': tab = h2.parent.find('table') for tr in tab.findAll('tr'): list = [] dict = {} if len(tr.findAll('td')) == 1: open_query_num = tr.find('td').string.split(':')[1] global total_dict total_dict['Total number of open queries'] = open_query_num if tr.find('a') != None: count = 0 for td in tr.findAll('td'): if count ==0: dict['UserName']=td.getText().strip() elif count == 1: list.append(td.getText().strip()) elif count == 2: dict['ExecutionEngine'] = td.getText().strip() elif count == 3: dict['State'] = td.getText().strip() elif count == 4: dt = td.getText().strip() timestamp = str(int(time.mktime(time.strptime(dt, '%a %b %d %H:%M:%S %Z %Y')))) dict['OpenedTimestamp'] = timestamp elif count == 5: dict['Opened'] = td.getText().strip() elif count == 6: dict['Latency'] = td.getText().strip() else: list.append(tr.find('a').get('href').split('=')[1]) count += 1 list.append(dict) open_query_list.append(list) return open_query_list #獲取已經完成的任務資訊 def hiveserver2_jsp_last(url): soup = getsoup(url) if len(last_query_list)!=0: global latest_query_timestamp latest_query_timestamp = int(last_query_list[len(last_query_list) - 1][2]['ClosedTimestamp']) del last_query_list[:] for h2 in soup.findAll('h2'): if h2.string == 'Last Max 25 Closed Queries': tab = h2.parent.find('table') for tr in tab.findAll('tr'): list = [] dict = {} if len(tr.findAll('td')) == 1: last_query_num = tr.find('td').string.split(':')[1] global total_dict total_dict['Total number of last queries'] = last_query_num if tr.find('a') != None: count = 0 for td in tr.findAll('td'): if count ==0: dict['UserName']=td.getText().strip() elif count == 1: list.append(td.getText().strip()) elif count == 2: dict['ExecutionEngine'] = td.getText().strip() elif count == 3: dict['State'] = td.getText().strip() elif count == 4: dict['Opened'] = td.getText().strip() elif count == 5: dt = td.getText().strip() timestamp = str(int(time.mktime(time.strptime(dt, '%a %b %d %H:%M:%S %Z %Y')))) dict['ClosedTimestamp'] = timestamp elif count == 6: dict['Latency'] = td.getText().strip() else: list.append(tr.find('a').get('href').split('=')[1]) count += 1 list.append(dict) if int(timestamp) <= latest_query_timestamp:
#為了避免重複輸出,如果已經輸出過就不要再輸出 continue else: last_query_list.append(list) return last_query_list#統計總的任務資訊def hiveserver2_jsp_total(): dict={} global total_dict return total_dict6、impala_metrics.py
import requests import re from bs4 import BeautifulSoup # get metric from impalad # 同Hive一樣,用beautifulsoup解析impala三類節點上的metric資訊 def impala_metrics(url): r = requests.get(url) pattern=re.compile(r'\-?\d*\.\d*\s(MB|KB|GB|B)')# 將G、M、K統一都轉換為B soup = BeautifulSoup(r.content,"html5lib") metric_dict = {} return_dict = {} for tr in soup.findAll('tr'): list = [] count = 0 if len(tr.findAll('td'))!=0: for td in tr.findAll('td'): if count==0: list.append(td.getText().strip()) elif count==1: if pattern.match(td.getText().strip()): unit=td.getText().strip().split(' ')[1] if unit=='KB': list.append(str(float(td.getText().strip().split(' ')[0])*1024)[:-3]) elif unit=='MB': list.append(str(float(td.getText().strip().split(' ')[0])*1024*1024)[:-3]) elif unit=='GB': list.append(str(float(td.getText().strip().split(' ')[0])*1024*1024*1024)[:-3]) else: list.append(td.getText().strip().split(' ')[0]) else: list.append(td.getText().strip()) else: continue count+=1 metric_dict[list[0]]=list[1] serviceport = url.split(':')[2][0:5]#開啟對應的檔案,找到對應要監控的屬性名 if serviceport=='25000': file = open('/root/impalad.txt') elif serviceport=='25010': file = open('/root/statestored.txt') elif serviceport=='25020': file = open('/root/catalogd.txt') else: print ("can't find impala service") lines = file.readlines() for key in metric_dict: for line in lines: if line.strip()==key: return_dict[key]=metric_dict[key] return return_dict
7、impala_queries.py
import requests from bs4 import BeautifulSoup import time latest_query_timestamp=0 closed_query_list = [] #獲取正在執行的session資訊,但往往impala執行的非常快,除非在生產環境,否則一般沒有資料 def impala_session(url): r = requests.get(url) soup = BeautifulSoup(r.content, "html5lib") session_list = [] th_list=['SessionType','OpenQueries','TotalQueries','User','DelegatedUser','SessionID','NetworkAddress','Default Database', 'StartTime','LastAccessed','IdleTimeout','Expired','Closed','RefCount','Action'] for tr in soup.findAll('tr'): list = [] dict = {} count = 0 if len(tr.findAll('td'))!=0: for td in tr.findAll('td'): if count==5: list.append(td.getText().strip()) elif count==8: dt = td.getText().strip() timestamp = str(int(time.mktime(time.strptime(dt, '%Y-%m-%d %H:%M:%S')))) dict[th_list[count]]=timestamp elif count==9: dt = td.getText().strip() timestamp = str(int(time.mktime(time.strptime(dt, '%Y-%m-%d %H:%M:%S')))) dict[th_list[count]]=timestamp else: dict[th_list[count]]=td.getText().strip() count+=1 if len(dict)!=0: list.append(dict) if len(list) != 0: session_list.append(list) return session_list #獲取已經完成的任務資訊 def impala_query_closed(url): r = requests.get(url) soup = BeautifulSoup(r.content,"html5lib") th_list = ['User','DefaultDb','Statement','QueryType','StartTime','EndTime','Duration','ScanProgress','State','RowsFetched','ResourcePool'] if len(closed_query_list)!=0: global latest_query_timestamp latest_query_timestamp = int(closed_query_list[0][2]['EndTime']) del closed_query_list[:] for h3 in soup.findAll('h3'): if 'Completed' in h3.getText(): table= h3.find_next('table') for tr in table.findAll('tr'): list = [] dict = {} count = 0 for td in tr.findAll('td'): if count==2: list.append(td.getText()) elif count==4: sdt = td.getText().strip() second = sdt.split(':')[2][0:2] sdt = sdt.split(':')[0] + ':' + sdt.split(':')[1] + ':' + second stimestamp = str(int(time.mktime(time.strptime(sdt, '%Y-%m-%d %H:%M:%S')))) dict['StartTime'] = stimestamp elif count==5: edt = td.getText().strip() second = edt.split(':')[2][0:2] edt = edt.split(':')[0]+':'+edt.split(':')[1]+':'+second etimestamp = str(int(time.mktime(time.strptime(edt, '%Y-%m-%d %H:%M:%S')))) dict['EndTime'] = etimestamp elif count==11: list.append(td.find('a').get('href').split('=')[1]) else: dict[th_list[count]] = td.getText().strip() count+=1 if len(dict)!=0: list.append(dict) if len(list) != 0: if int(dict['EndTime']) <= latest_query_timestamp:#為了避免重複輸出,如果已經輸出過就不要再輸出了 break else: closed_query_list.append(list) return closed_query_list
8、prin_.py(千萬不要叫print.py,會跟python自帶包衝突,坑了我好久)
import hive_query import hive_jmx import impala_queries import impala_metrics import get_clusternmae import time import socket import kerberos2 import findkeytab def printdict(dict): for key in dict: print key + '=' + dict[key], print def writedict(dict,file): count=1 for key in dict: file.write(key + '=' + dict[key]) if count==len(dict): file.write('\n') else: file.write(',') count+=1 krb = kerberos2.KerberosTicket('HTTP/'+socket.gethostname()+'@HADOOP.COM', findkeytab.findkeytab(), 'HTTP/'+socket.gethostname()+'@HADOOP.COM') while True: timestamp = str(int(time.time())) common_tag_dict={} endpoint=socket.gethostname() ipaddr=socket.gethostbyname(endpoint) clustername = get_clusternmae.get_cluster_name(ipaddr) common_tag_dict['endpoint']=endpoint common_tag_dict['cluster'] = clustername #monitor hive active session active_session_list = [] active_session_list = hive_query.hiveserver2_jsp_session('http://'+endpoint+':10002/hiveserver2.jsp') if len(active_session_list) != 0: for l in active_session_list: print 'hive.hiveserver2.session.ActiveTime ' + l[0] + ' ', l[2].update(common_tag_dict) del l[2]['IP'] printdict(l[2]) print 'hive.hiveserver2.session.IdleTime ' + l[1] + ' ', l[2].update(common_tag_dict) printdict(l[2]) # monitor hive opening queries open_query_list = [] open_query_list = hive_query.hiveserver2_jsp_open('http://'+endpoint+':10002/hiveserver2.jsp') if len(open_query_list) != 0: for l in open_query_list: print 'hive.hiveserver2.query.opening-uuid '+l[1]+' '+timestamp, l[2].update(common_tag_dict) printdict(l[2]) #monitor hive closed queries last_query_list = [] last_query_list = hive_query.hiveserver2_jsp_last('http://'+endpoint+':10002/hiveserver2.jsp') if len(last_query_list) != 0: for l in last_query_list: file = open("/root/hive_query.txt",'a') file.write('uuid='+l[1]+','+'Sql='+l[0]+',') writedict(l[2],file) file.close() del l[2]['Latency'] print 'hive.hiveserver2.query.closed-uuid '+l[1]+' '+timestamp, l[2].update(common_tag_dict) printdict(l[2]) #monitor the total hive data total_dict = hive_query.hiveserver2_jsp_total() for key in total_dict: if key == 'Total number of sessions': print 'hive.hiveserver2.total.session'+total_dict['Total number of sessions']+' '+timestamp, printdict(common_tag_dict) if key == 'Total number of open queries': print 'hive.hiveserver2.total.openingquery'+total_dict['Total number of open queries']+' '+timestamp, printdict(common_tag_dict) if key == 'Total number of last queries': print 'hive.hiveserver2.total.closedquery'+total_dict['Total number of last queries']+' '+timestamp, printdict(common_tag_dict) #monitor the hive jmx jmx_list = hive_jmx.hiveserver2_jmx('http://'+endpoint+':10002/jmx') for i in range (len(jmx_list)): print 'hive.'+jmx_list[i][0]+' '+ jmx_list[i][1]+' '+timestamp, jmx_list[i][2].update(common_tag_dict) printdict(jmx_list[i][2]) #monitor impala metrics impalad_url='http://'+ipaddr+':25000/metrics' impala_impalad_metrics = impala_metrics.impala_metrics(impalad_url) for key in impala_impalad_metrics: print 'impala.'+key+' '+impala_impalad_metrics[key]+' '+timestamp, printdict(common_tag_dict) statestored_url = 'http://' + ipaddr + ':25010/metrics' impala_statestored_metrics = impala_metrics.impala_metrics(statestored_url) for key in impala_statestored_metrics: print 'impala.'+key +' '+ impala_statestored_metrics[key]+' '+timestamp, printdict(common_tag_dict) catalogd_url = 'http://' + ipaddr + ':25020/metrics' impala_catalogd_metrics = impala_metrics.impala_metrics(catalogd_url) for key in impala_catalogd_metrics: print 'impala.'+key +' '+ impala_catalogd_metrics[key]+' '+timestamp, printdict(common_tag_dict) # monitor impala closed queries impala_closed_query_list = [] impala_closed_query_list = impala_queries.impala_query_closed('http://'+ipaddr+':25000/queries#') if len(impala_closed_query_list)!=0: for l in impala_closed_query_list: file = open("/root/impala_query.txt",'a') file.write(l[1]+' '+l[0]+'\n') file.write('uuid=' + l[1] + ',' + 'Sql=' + l[0]+',') writedict(l[2], file) file.close() del l[2]['ResourcePool'] del l[2]['ScanProgress'] del l[2]['DefaultDb'] del l[2]['EndTime'] del l[2]['QueryType'] print 'impala.query.closed-uuid '+l[1]+' '+timestamp, l[2].update(common_tag_dict) printdict(l[2]) # monitor impala session impala_session_list=[] impala_session_list = impala_queries.impala_session('http://'+ipaddr+':25000/sessions') if len(impala_session_list)!=0: for l in impala_session_list: print 'impala.active.session'+' '+ l[0] + ' '+timestamp, l[1].update(common_tag_dict) printdict(l[1]) time.sleep(10)
相關推薦
大資料平臺運維-----Kerberos環境下Hive及Impala監控指令碼的開發
一、工程目錄二、原理解析 Hive和Impala是兩個最常用的大資料查詢工具,他們的主要區別是Hive適合對實時性要求不太高的業務,對資源的要求較低;而Impala的由於採用了全新的架構,處理速度非常的快,但同樣的也對資源消耗比較大,適合實時性要求高的業務。 在我
大資料平臺運維------CM與CDH的升級
CM與CDH的升級過程有點類似與安裝過程,這裡我們也是採用離線安裝模式,各軟體版本資訊為:作業系統:CentOS6.8CDH版本:5.7.1:CDH-5.7.1-1.cdh5.7.1.p0.11-el5.parcel.sha CDH-5.7.1-
優雲軟體葉帥:“網際網路+”時代的雲資料中心運維思辨(下)
2017中國開源產業峰會暨中國國際軟體博覽會分論壇,優雲軟體葉帥在開源雲端計算技術創新論壇發表了《“網際網路+”時代的雲資料中心運維思辨》的主題演講,本文根據演講內容整理而成。 無論是穩態還是敏態,大家關注的內容最終的目標並不會發生變化,最終的目標都是保證當前的資料、
亞馬遜AWS創新與實踐專場:AWS的大資料、運維與架構實戰
【CSDN現場報道】5月13日-15日,由全球最大中文IT社群CSDN主辦的“2016中國雲端計算技術大會”(Cloud Computing Technology Conference 2016,簡稱CCTC 2016)在北京新雲南皇冠假日酒店隆重舉行。本次大會
大資料平臺--資料庫的遷移(HBase、Hive、Mysql)
一、HBase的遷移 步驟:獲取表-->壓縮-->遷移到目標叢集-->解壓-->把檔案上傳到HDFS的HBase目錄下-->利用hbase hbck修復 (注意:不需要事先在目標群集上建立表) //------在源群集上的操作-------
阿里雲搭建大資料平臺(3):安裝JDK和Hadoop偽分佈環境
一、安裝jdk 1.解除安裝Linux自帶的JDK rpm -qa|grep jdk #查詢原始JDK yum -y remove <舊JDK> 2.解壓縮 tar -zxvf /opt/softwares/jdk-8u151-linux-x64.t
資料中心運維工程師的十大機房管理制度,你瞭解嗎?
機房管理是傳統IDC以及資料中心的運維工程師、運維經理關注的主要工作,運維派收集整理了一些關於機房管理制度建設的條例分享給大家,如果您有更好的經驗,歡迎留言分享,也歡迎投稿到運維派。 一、機房人員日常行為準則 1、必須注意環境衛生。禁止在機房內吃食物、抽菸、隨地吐痰;對於意外或工作過程中弄汙機房地板
大資料平臺Hadoop的分散式叢集環境搭建,官網推薦
1 概述 本文章介紹大資料平臺Hadoop的分散式環境搭建、以下為Hadoop節點的部署圖,將NameNode部署在master1,SecondaryNameNode部署在master2,slave1、slave2、slave3中分別部署一個DataNode節點 NN
從零開始搭建大資料平臺系列之(1)——環境準備
1、機器準備 (1)物理機配置 處理器:Intel® Core™ i7 處理器 記憶體:8.00GB 系統型別:64 位作業系統,基於 x64 的處理器 作業系統:Windows 10 專業版 (2)磁碟陣列 常用磁碟陣列型別:RAID 0,RAID 1,RAI
從零開始搭建大資料平臺系列之(2.1)—— Apache Hadoop 2.x 偽分散式環境搭建
JDK 版本:jdk 1.7.0_67 Apache Hadoop 版本:Hadoop 2.5.0 1、安裝目錄準備 ~]$ cd /opt/ opt]$ sudo mkdir /opt/modules opt]$ sudo chown beifeng:b
企業大資料平臺下數倉建設思路
介然(李金波),阿里雲高階技術專家,現任阿里雲大資料數倉解決方案總架構師。8年以上網際網路資料倉庫經歷,對系統架構、資料架構擁有豐富的實戰經驗,曾經資料魔方、淘寶指數的資料架構設計專家。 與阿里雲大資料數倉結緣 介然之前在一家軟體公司給企業客戶做軟體開發和數倉開發實
自行構建運維架構環境...
linux 寫給自己:linux運維路... https://shenfly.space 以後繼續完善架構,並布暑一些開源系統,測試。。本文出自 “生命不息 奮鬥不止” 博客,請務必保留此出處http://shenfly231.blog.51cto.com/12811004/1925049自行
電商大數據平臺運維案例
blank 之一 order olt 建設 12px img 方案 互聯網 技術棧數據流向平臺規模差異化,隔離化YARN: https://baike.baidu.com/item/yarn/16075826?fr=aladdin 今天先到這兒,希望對您在系統架構設計與評
自動化運維之CentOS7下PXE+Kickstart+DHCP+TFTP+HTTP無人值守安裝系統
pwd 概述 .com 掛載 name 翻譯 epo 服務狀態 信息 一、概述 1、關於PXEPreboot Execution Environment翻譯過來就是預啟動執行環境;簡稱PXE;傳統安裝操作系統的方法是CDROM或U盤引導,而PXE技術解決的是從網絡引導安裝系
如何在SAP雲平臺的Cloud Foundry環境下添加新的Service(服務)
SAP SCP SAP雲平臺 微服務 Cloud Foundry 我想在SAP雲平臺的Cloud Foundry環境下使用MongoDB的服務,但是我在Service Marketplace上找不到這個服務。 cf marketplace返回的結果也沒有。 解決方案 退回到Global
優雲軟體葉帥:“網際網路+”時代的雲資料中心運維思辨(上)
2017中國開源產業峰會暨中國國際軟體博覽會分論壇,優雲軟體葉帥在開源雲端計算技術創新論壇發表了《“網際網路+”時代的雲資料中心運維思辨》的主題演講,本文根據演講內容整理而成。 我為大家分享一下目前運維的一些發展態勢,剛才主持人提到在雲環境下或者是“網
資料脫敏介紹(大資料平臺 )
資料脫敏(Data Masking),又稱資料漂白、資料去隱私化或資料變形。百度百科對資料脫敏的定義為:指對某些敏感資訊通過脫敏規則進行資料的變形,實現敏感隱私資料 的可靠保護。這樣,就可以在開發、測試和其它非生產環境以及外包環境中安全地使用脫敏後的真實資料集。 可以看到資料脫敏具有幾個關鍵點:
資料來源/大資料平臺
【彙總】資料來源/大資料平臺 一、網路趨勢分析 站長工具:5118 | chinaz 指數工具:艾瑞指數 | 百度指數 | 微指數 | 搜狗指數
大資料平臺架構思考
筆者早期從事資料開發時,使用spark開發一段時間,感覺大資料開發差不多學到頭了,該會的似乎都會了。在後來的實踐過程中,發現很多事情需要站在更高的視角來看問題,不然很容易陷入“不識廬山真面目”的境界。最近在思考資料資產管理平臺的建設,進行血緣分析開發,有如下感悟: 大資料平臺從資料層面來說,包括資料本身和元
【福利】送Spark大資料平臺視訊學習資料
沒有套路真的是送!! 大家都知道,大資料行業spark很重要,那話我就不多說了,貼心的大叔給你找了份spark的資料。 多囉嗦兩句,一個好的程式猿的基本素養是學習能力和自驅力。視訊給了你們,能不能堅持下來學習,就只能靠自己了,另外大叔每週會不定期更新《每日五分鐘搞定