
企業大資料平臺下數倉建設思路
介然(李金波),阿里雲高階技術專家,現任阿里雲大資料數倉解決方案總架構師。8年以上網際網路資料倉庫經歷,對系統架構、資料架構擁有豐富的實戰經驗,曾經資料魔方、淘寶指數的資料架構設計專家。
與阿里雲大資料數倉結緣
介然之前在一家軟體公司給企業客戶做軟體開發和數倉開發實施,數倉開發和實施都是基於傳統的基礎架構。2008年加入阿里進入淘寶資料平臺部後,他開始接觸分散式計算平臺Hadoop。
初始時在Hadoop平臺上構建數倉主要解決企業內部資料分析的需求,在2010年公司決定對外開放資料後,開始於2011年利用自建的數倉體系支援對外資料產品資料魔方、淘寶指數。後續在平臺和產品上不停的豐富資料內容,同時離線和流式兩套資料體系支援資料產品。
從2012年開始,之前在Hadoop上的資料體系搬遷到阿里雲數加MaxCompute(原ODPS),並完成了資料體系的重構,此時介然負責平臺基礎資料的建設支援全集團的上層資料應用。在2014年之後,公司開始對外服務,開始研究資料服務化和幫助外部使用者如何利用阿里的平臺實現大資料應用。
數倉上遇到的挑戰:資料質量保障、穩定和重複性
在資料魔方、淘寶指數和阿里大資料數倉解決方案設計中,介然遇到了不少有挑戰性的技術問題,主要集中在以下三點:
1.資料質量保障:隨著業務的複雜度增加,資料來源頭的型別和資料量也會越來越多,經常會碰到某些資料來源因為一些偶發的原因同步過來的資料質量出現問題。比如日誌出現亂碼、資料庫因為切庫造成資料同步量變少等等。這就要求在整個數倉體系的搭建過程中不只要完成資料業務邏輯的處理,還需要增加資料質量的監控。“我們在核心的資料處理流程中,增加資料質量監控程式碼,如果碰到資料量的突變或者核心指標的突變,會將資料處理流程暫停並預警,讓資料運維人員處理資料質量問題後再進行後續資料流程的執行,保障有質量問題的資料不流到下游應用中。”
2.資料產出穩定性保障:隨著資料量的增加、計算資源的逐漸飽和,業務資料最終產出的時間開始延遲,並有可能不能按照業務要求的時間點產出。“這個時候我們會分析資料產出的關鍵路徑,找出關鍵路徑下消耗時間最多的執行JOB,通過資料模型優化、計算任務拆解或者計算任務程式碼優化的手段減少任務產出的時間,同時保障整體產出時間滿足預期。”
3.重複的資料處理程式碼:由於業務的特殊性,會對某種型別的資料加工操作需求非常多。比如計算交易中,TOP N的商家、TOP N 的品牌、TOP N的商品,商家中TOP N的商品、品牌中TOP N的商家等等。 這類程式碼都是非常類似的,如果每個計算都獨立任務,會造成計算資源的大量浪費。“我們通過特殊的程式碼框架,讓一份基礎資料中多種TOPN的資料可以在一次計算過程中產出,大大減少資源消耗,保障資料產出穩定。”
優秀數倉的三要素:清晰、保障和擴充套件性好
介然認為,優秀的資料倉庫應該包含以下要素:
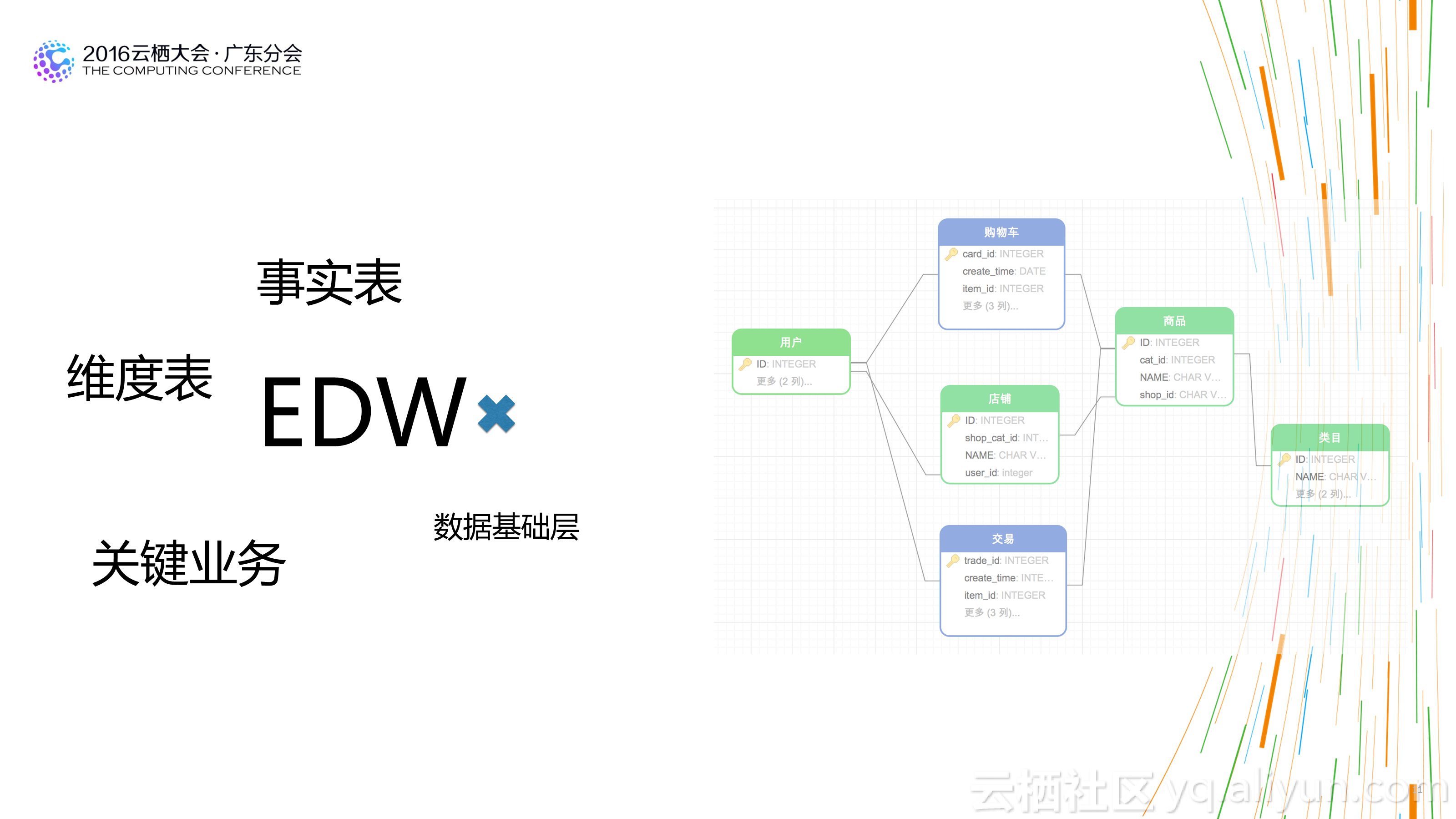
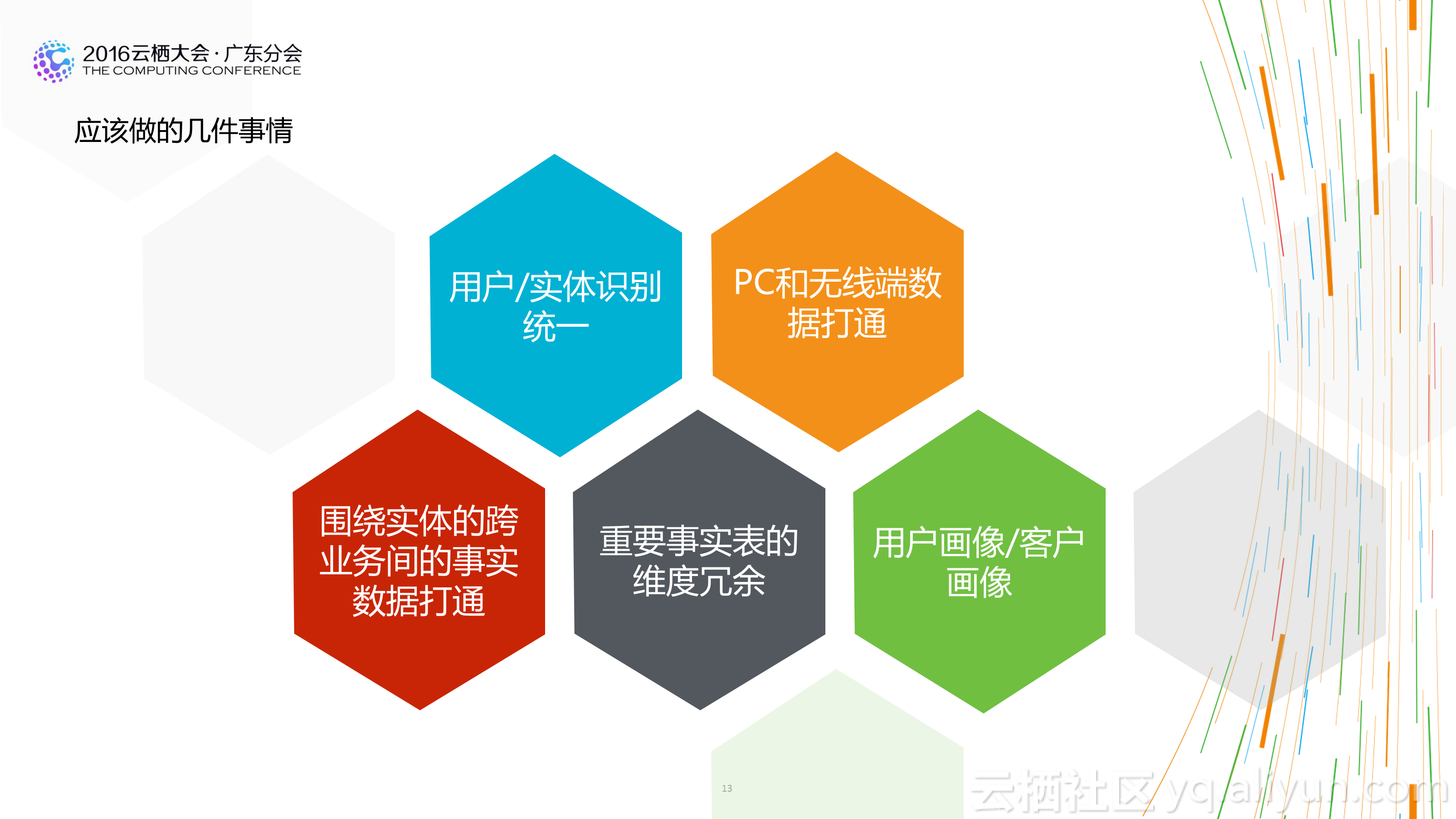
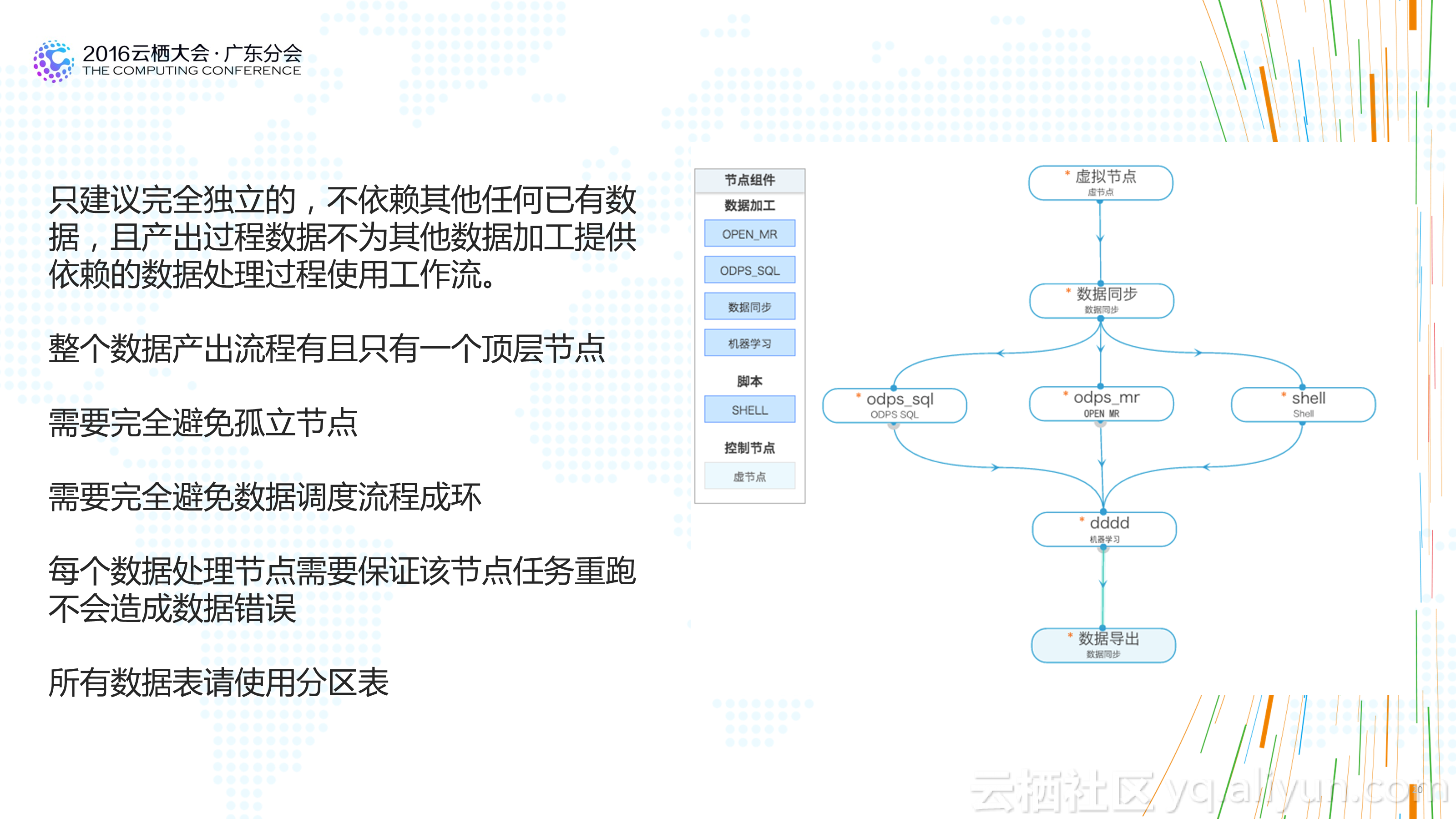
1.結構、分層清晰:不一定需要多少個分層和主題,但是一定要清晰。用資料的人能夠很快找到需要資料的位置。
2.資料質量和產出時間有保障;
3.擴充套件性好:不會因為業務的些許變化造成模型的大面積重構。
而從系統架構、資料架構兩個緯度來看,要想設計好大資料應用下的資料倉庫,還應做到以下兩點。
1.系統架構上:足夠的容錯性,減少不必要的系統間的強耦合。因為你會碰到各種問題,不要因為一個不必要的依賴造成資料無法產出。
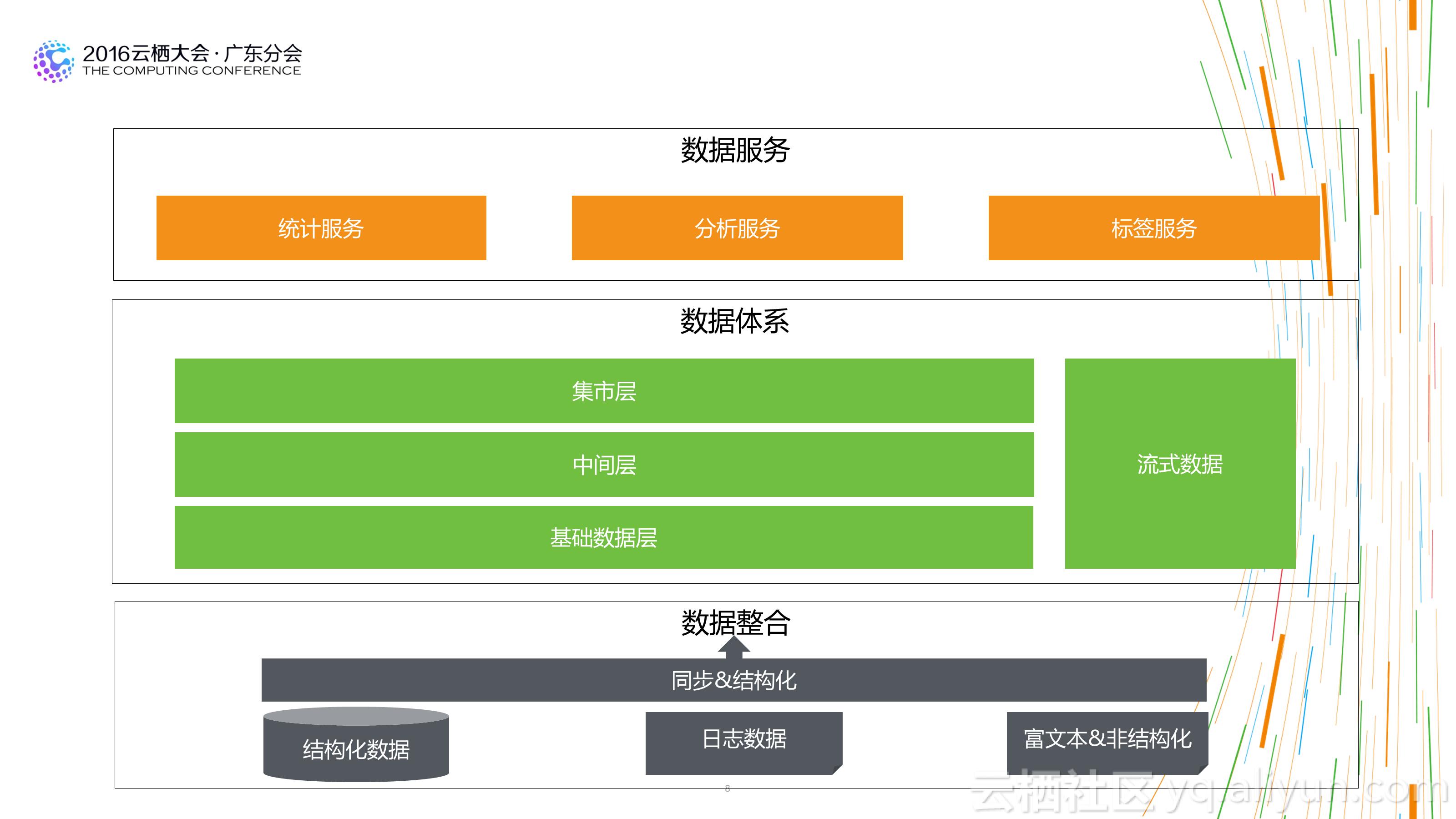
2.資料架構上:簡單、清晰、強質量控制。資料架構上扁平化的資料處理流程會對資料質量的控制和資料產出的穩定性提供非常好的基礎。
網際網路人轉型做大資料數倉需要注意哪幾個點?
對於之前做網際網路資料倉庫,現在想轉型做大資料倉庫的人,介然也提了一些建議,主要是四點:
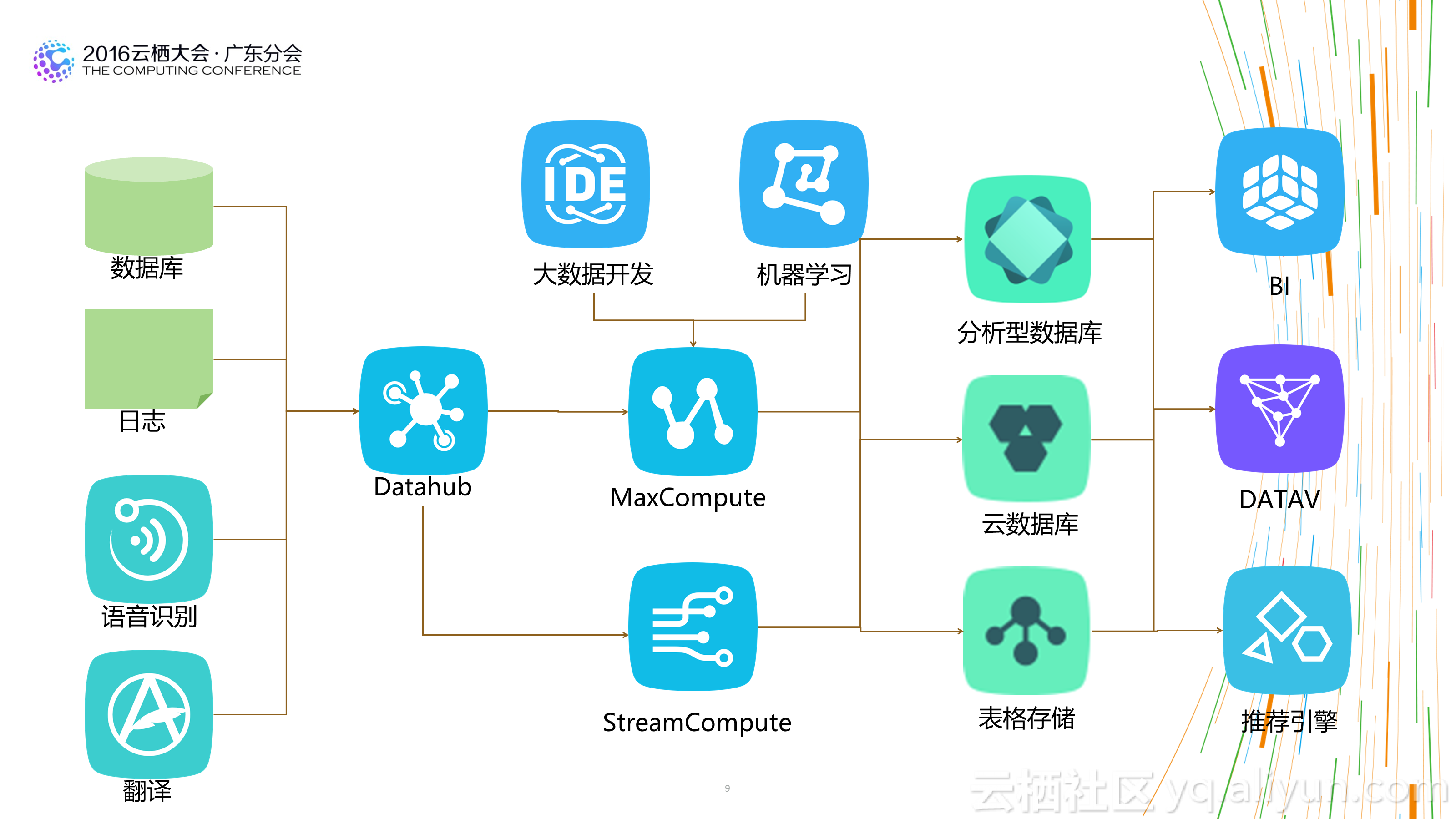
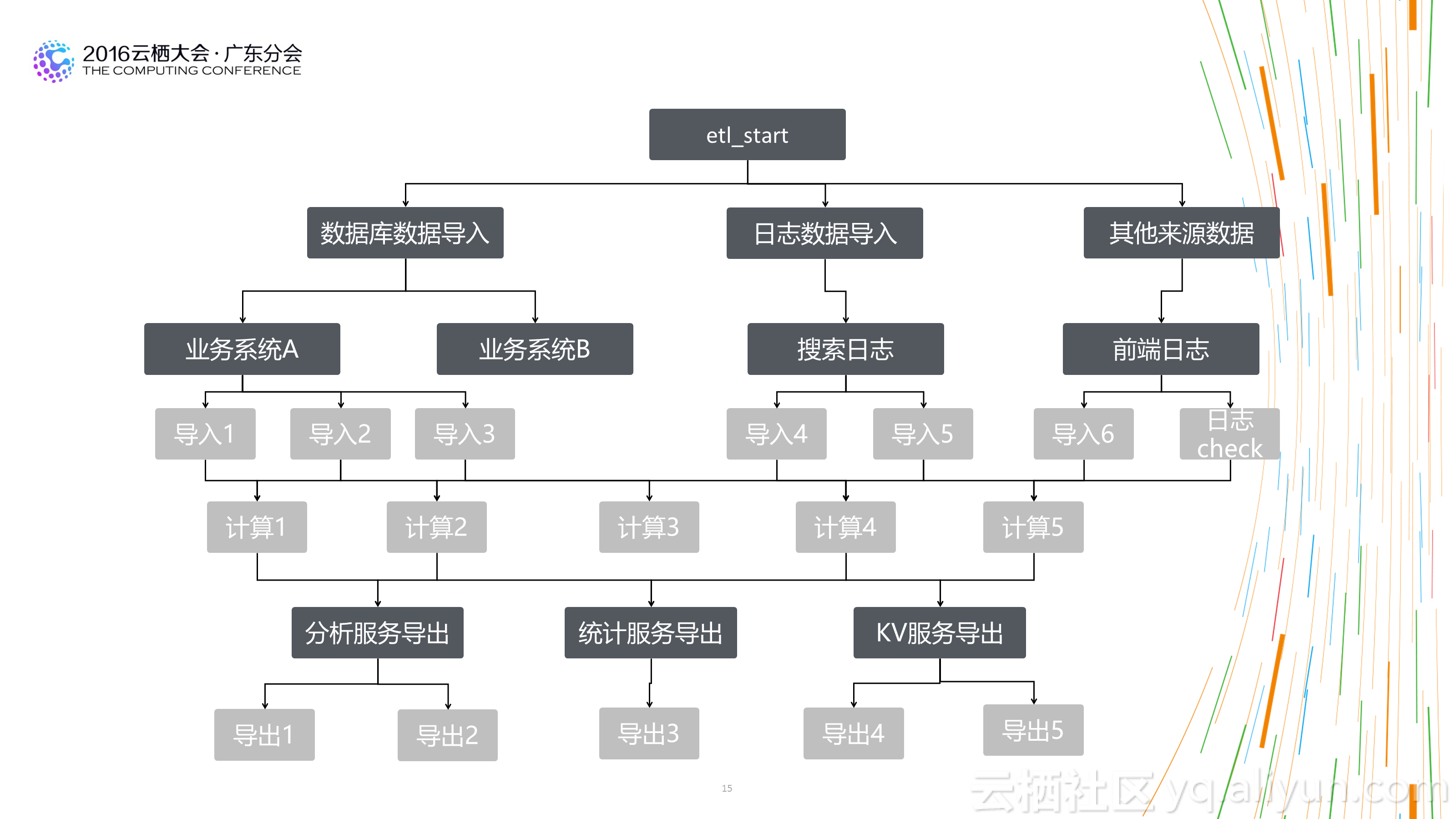
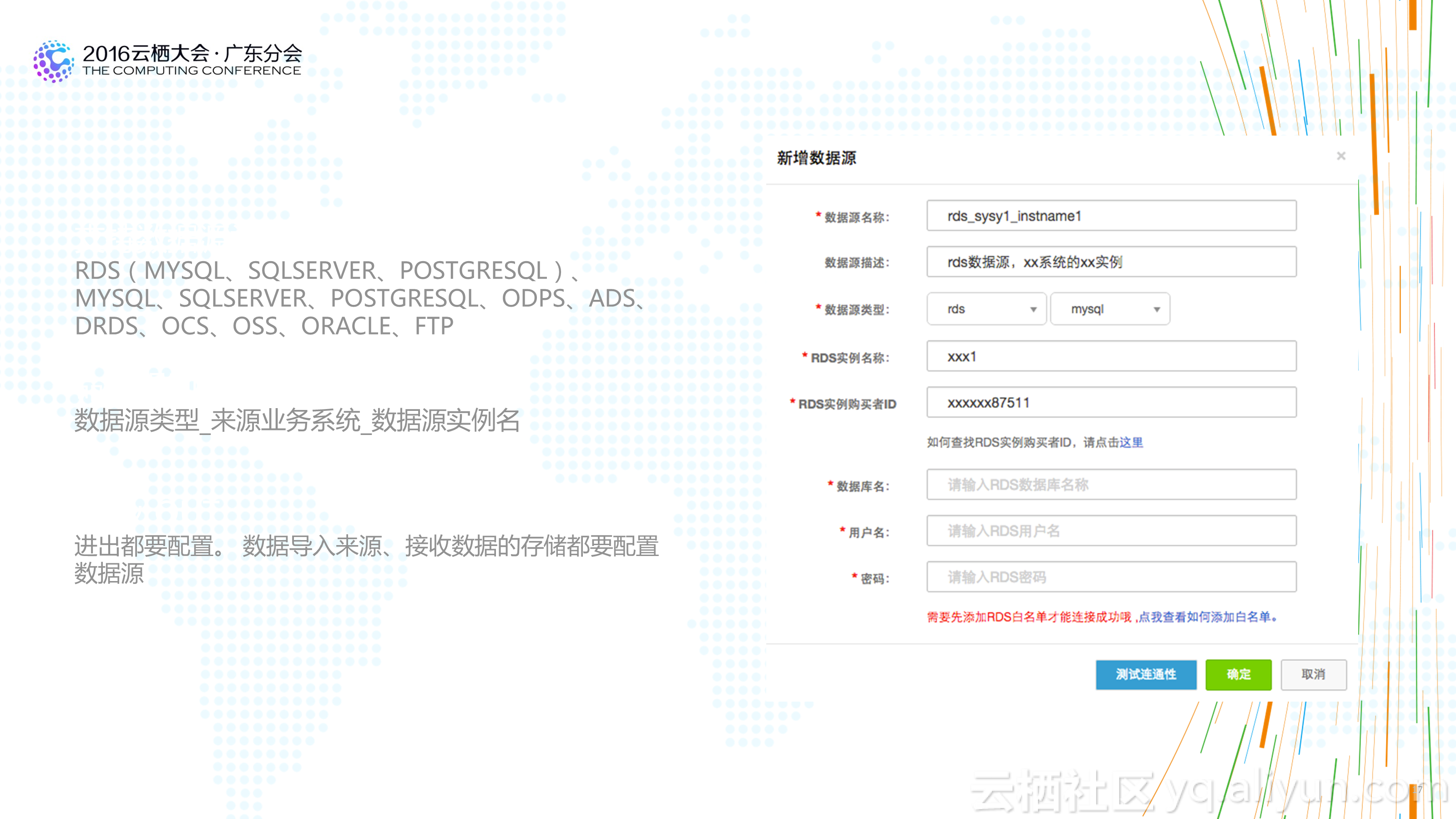
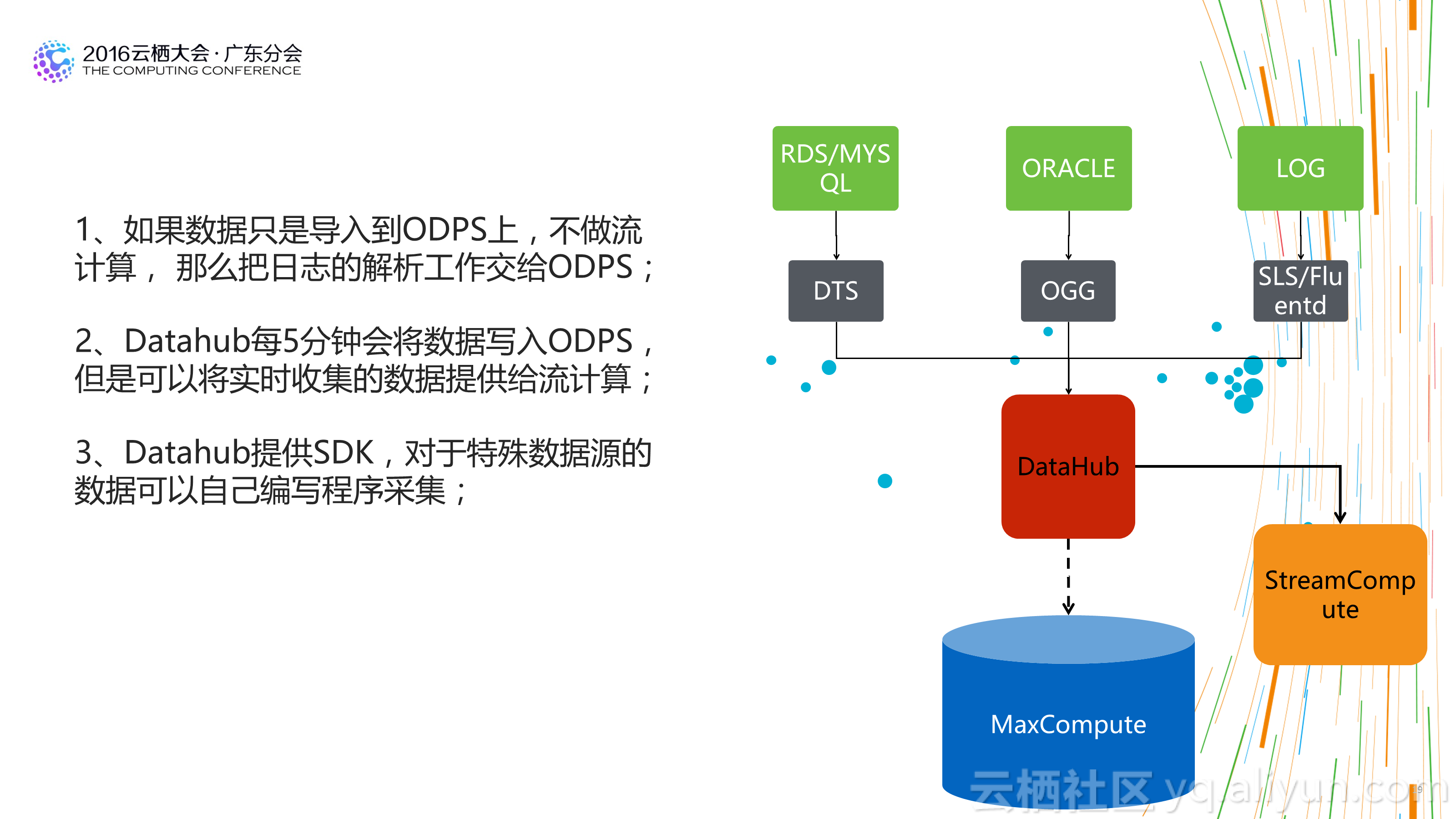
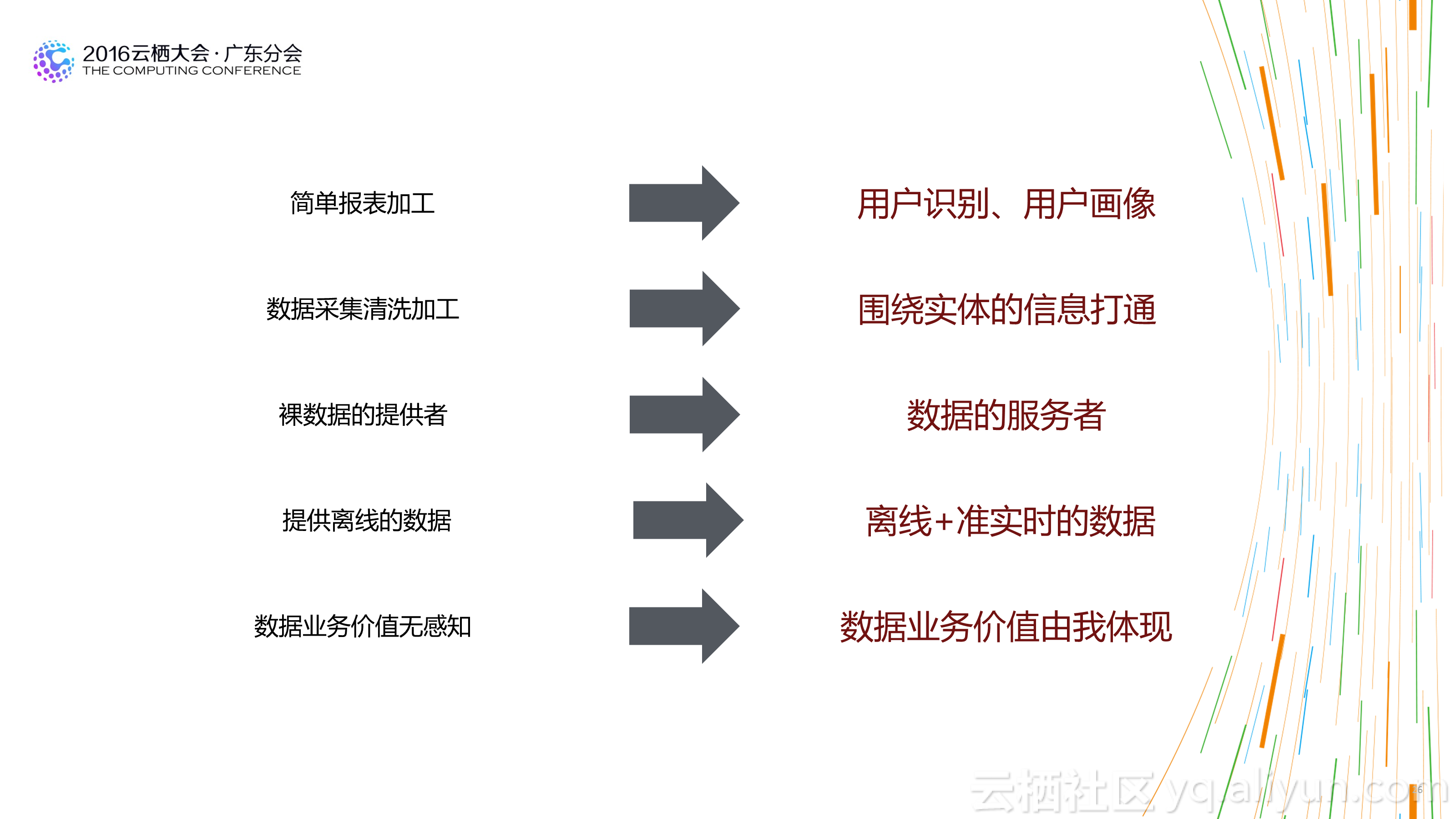
1.不必再苛刻的精打細算:基於傳統平臺構建數倉時,為了照顧平臺的處理能力,我們經常會構建多層資料結構,預先對不同粒度的資料做預先彙總,以方便使用者在使用資料時能夠已最小的計算代價獲得計算結果。這也造成了整個資料處理流程較長,步驟很多,問題追溯困難。 新的大資料倉庫基於分散式計算平臺,平臺的計算能力通常都比傳統的平臺強大很多。 所以有時候需要時再計算資料,或者基於明細進行各粒度的資料彙總已經能夠滿足需求,並能夠大大減少整體資料處理流程步驟,用計算的代價減少人工的成本,更划算,資料體系也更健壯。
2.不是模型層次越多越好:在傳統的數倉架構中,大家都喜歡多資料模型進行分層設計,不同的模型層次擁有不同的資料域和作用域。這樣設計固然看起來更清晰,但實際情況時多層之間可能存在重複資料,或者資料使用者在上層找不到完全切合的資料時,更願意從底層的明細資料上自己去加工。一方面造成了資料使用上的混亂,一方面也會讓資料整個處理流程長度增加,對於資料的運維帶來較大的成本消耗。合理的層次設計,及在計算成本和人力成本間的平衡,是一個好的數倉架構的表現。
3.質量是生命線:不再是你拿到的資料都是正確的,新的環境下的資料什麼情況都會發生,而好的數倉架構需要有足夠的容錯性和質量保障。不要因為一條日誌的亂碼造成整個資料流程無法走通,也不要說一份日誌50%的亂碼你的程式還發現不了。在資料質量上投入再多的資源都不是浪費。
4.資料變成生產資料:傳統的資料應用絕大部分都是以報表和BI分析的形式支援業務。也許你的報表晚出來會被老闆罵一通,但是對業務的影響並不大。 但是在新的資料應用場景下,資料已經變成生產資料,資料會服務化直接應用到業務系統中,也許一份資料的質量出現問題或者產出延遲,都可能對你的業務系統產生致命的影響。所以數倉開始承擔新的使命。
如果你依然迷惑,歡迎來聽聽阿里是如何搭建一個好的資料倉庫
介然稱,本次分享會講:在大資料的應用場景下,基於新的分散式計算平臺的特徵如何設計資料倉庫。“會從應用需求、平臺的特徵、模型的設計、產品的應用幾個角度來說明如何在阿里大資料平臺下搭建一個好的資料倉庫。”對於細節,他介紹到。
這位阿里雲大資料數倉解決方案總架構師,非常希望大家來聽本次分享:“不管你在什麼平臺上做過資料開發,或者公司開始做大資料應用,只要利用平臺支援這個應用,都歡迎來一起討論。”
精彩分享













 原文連結:
原文連結:
| http://click.aliyun.com/m/13927/ |