
Context Encoders: Feature Learning by Inpainting 閱讀筆記
目錄
1. 介紹
無監督學習,
- 影象修復
- 學習深層特徵
通過下圖可以看到效果很好

2. 架構
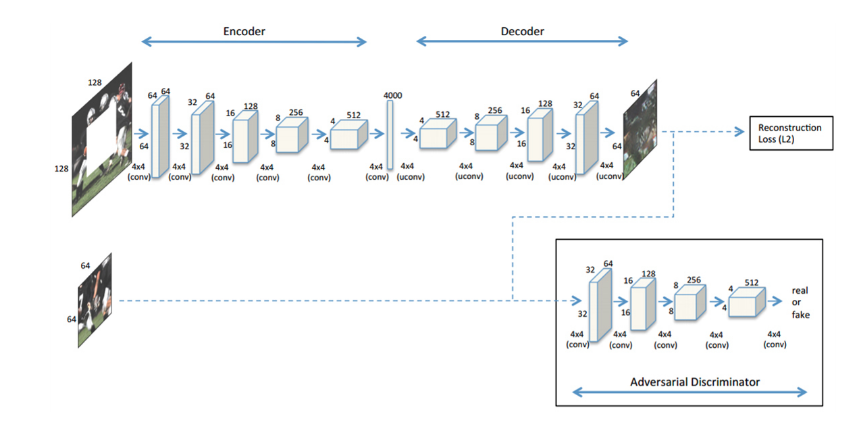
link
採用類似encoder-decoder架構, L2 loss使圖片重建相近,adversarial loss使圖片清晰
encoder和decoder之間使用channel-wise FC層相連(因為修復需要四周的context,而單純conv只有區域性語義)
3. 資料生成

三種方式, up to 1/4 image
相關推薦
Context Encoders: Feature Learning by Inpainting 閱讀筆記
目錄 1. 介紹 無監督學習, 影象修復 學習深層特徵 通過下圖可以看到效果很好 2. 架構 link 採用類似encoder-decoder架構, L2 loss使圖片重建相近,adversarial loss使圖片清晰
論文閱讀筆記二十:MULTI-SCALE CONTEXT AGGREGATION BY DILATED CONVOLUTIONS(ICRL2016)
論文源址:https://arxiv.org/abs/1511.07122 tensorflow Github:https://github.com/ndrplz/dilation-tensorflow 摘要 該文提出了空洞卷積模型,在不降低解析
閱讀筆記之——《Recovering Realistic Texture in Image Super-resolution by Deep Spatial Feature Transform》
本博文是文章《Recovering Realistic Texture in Image Super-resolution by Deep Spatial Feature Transform》也就是SFTGAN的學習筆記。附上論文的連線(https://arxiv.org/pdf/1804.02
論文閱讀筆記——《Crafting a Toolchain for Image Restoration by Deep Reinforcement Learning》
這篇論文是CVPR 2018 (Spotlight),是本人團隊小夥伴餘可的作品~ 程式碼連結:https://github.com/yuke93/RL-Restore 專案主頁:http://mmlab.ie.cuhk.edu.hk/projects/RL-Restore/ 論文連
1705.Person Re-Identification by Deep Joint Learning of Multi-Loss Classification 論文閱讀筆記
Person Re-Identification by Deep Joint Learning of Multi-Loss Classification 本文采用多loss分類聯合訓練同時學習行人條紋區域性特徵和全域性特徵,受益於區域性和全域性學習到的特徵具有
"CapProNet: Deep Feature Learning via Orthogonal Projections onto Capsule Subspaces"閱讀筆記
"CapProNet: Deep Feature Learning via Orthogonal Projections onto Capsule Subspaces" 閱讀筆記 capsule簡介 capsule subspace 正交投影 網路
[論文閱讀筆記] node2vec Scalable Feature Learning for Networks
## [論文閱讀筆記] node2vec:Scalable Feature Learning for Networks --- ## 本文結構 1. 解決問題 2. 主要貢獻 3. 演算法原理 4. 參考文獻 --- ### (1) 解決問題 由於DeepWalk的隨機遊走是完全無指導的隨機取樣,即隨機
Representation Learning: A Review and New Perspectives閱讀筆記
文章 構建 review 什麽 幫助 函數 深度 表示 工程 摘要-機器學習算法依賴於數據表示,盡管特定的領域知識可以被幫助用來學習知識表示,先驗知識也是可以用來學習的,並且應用先驗知識設計更有效的知識表示學習算法正是AI的需求。這篇文章回顧了非監督特征學習和深度學習相關領
論文閱讀筆記(一)LeNet--Gradient-Based Learning Applied to Document Recognition
輸入 共享 rbf map 內部 field dex title 手動 作者:Yann LeCun,Leon Botton, Yoshua Bengio,and Patrick Haffner這篇論文內容較多,這裏只對部分內容進行記錄:以下是對論文原文的翻譯:在傳統的模式識
《A Discriminative Feature Learning Approach for Deep Face Recognition》論文筆記
1. 論文思想 在這篇文章中尉人臉識別提出了一種損失函式,叫做center loss,在網路中加入該損失函式之後可以使得網路學習每類特徵的中心,懲罰每類的特徵與中心之間的距離。並且該損失函式是可訓練的,並且在CNN中容易優化。那麼,將center loss與softmax相結合會增加
【論文閱讀筆記】Deep Learning based Recommender System: A Survey and New Perspectives
【論文閱讀筆記】Deep Learning based Recommender System: A Survey and New Perspectives 2017年12月04日 17:44:15 cskywit 閱讀數:1116更多 個人分類: 機器學習
學習筆記之Machine Learning by Andrew Ng | Coursera
Machine Learning | Coursera https://www.coursera.org/learn/machine-learning Machine learning is the science of getting computers to act without being
《Context Contrasted Feature and Gated Multi-Scale Aggregation for Scene Segmentation》論文閱讀
動機 第一個工作的動機,(context contrasted local (CCL) model ) 作者認為獲得有判別力的語義特徵以及多尺度融合是提升效能的關鍵; 上下文通常具有平滑的表示,並且由顯著物件的特徵支配,這對於標記不顯眼的物件和東西是
【閱讀筆記】Applying Deep Learning To Airbnb Search
Applying Deep Learning To Airbnb Search Airbnb Inc. [email protected] 2018年10月25日 ABSTRACT 最初使用 gradient boosted decision tree model 來做
論文閱讀筆記《Gated Context Aggregation Network for Image Dehazing and Deraining》WACV19
輸出 每一個 為什麽 作用 導致 作者 ont 而不是 簡單的 目錄: 相關鏈接 方法亮點 方法細節 實驗結果 總結與收獲 相關鏈接: 論文:https://arxiv.org/abs/1811.08747 源碼:暫無 方法亮點: 提出端到端的去霧網絡,不
論文閱讀筆記二十二:Learning to Segment Instances in Videos with Spatial Propagation Network(CVPR-20017)
論文源址:https://arxiv.org/abs/1709.04609 摘要 該文提出了基於深度學習的例項分割框架,主要分為三步,(1)訓練一個基於ResNet-101的通用模型,用於分割影象中的前景和背景。(2)將通用模型進行微調成為一個例項分割模型,藉
論文閱讀筆記二十三:Rich feature hierarchies for accurate object detection and semantic segmentation Tech report(R-CNN CVPR2014)
論文源址:http://www.cs.berkeley.edu/~rbg/#girshick2014rcnn 摘要 在PASCAL VOC資料集上,最好的方法的思路是將低階資訊與較高層次的上下文資訊進行結合。該文的兩個亮點:(1)將CNN應用到re
《GraphGAN:Graph Representation Learning with Generative Adversarial Nets》論文閱讀筆記
最近在準備碩士期間的畢業論文的開題工作,也是比較愁於沒有什麼好的畢業設計的想法。在學習完這篇論文後,我發現基於生成對抗網路的網路表示學習的方法挺有意思。通過寫這篇部落格也是想要加深自己對這篇論文的idea的理解,同時也想著是否我也可以提出一種改進或是適當借鑑一下這種思想。 &nbs
Deep Learning for Generic Object Detection: A Survey 閱讀筆記
目錄 摘要 1.介紹 2.背景 2.1問題 3.框架 摘要 目標監測旨在從自然影象中定位出大量預定義類別的例項物件,是機器視覺中最基本也是最具挑戰的問題。近年來,深度學習技術作為直接從資料學習特徵表示的強
part-aligned系列論文:1707.Deep Representation Learning with Part Loss for Person ReID 論文閱讀筆記
Deep Representation Learning with Part Loss for Person ReID 本論文為了更好的提升reid模型在未見過的行人影象判別能力,正對現有大部分只有全域性特徵表達(轉化為分類,一般minimize the em