RGB-D object recognition and pose estimation based on pre-trained convolutional neural network 閱讀記錄
阿新 • • 發佈:2019-02-08
最近發現將閱讀論文的心得體會記錄下來是很有必要的,一方面將自己的想法用文字表達出來,可以鍛鍊論文寫作表達能力,便於後續論文寫作。另一方面,便於回顧自己的工作。
本文僅代表我自己的觀點,對論文理解有誤的地方,歡迎大家指正。
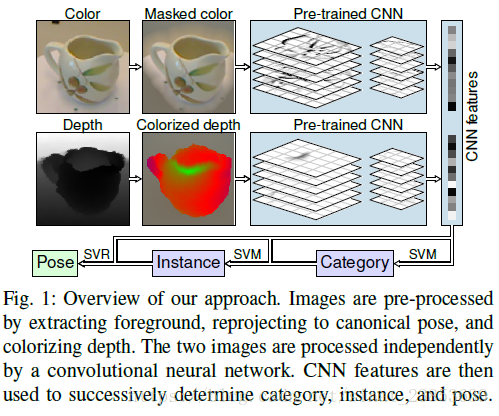
正如標題說是,本文是利用遷移學習技術將訓練好的CNN模型應用於室內物體(household object)的識別及姿態評估任務。為了獲得物體的姿態,並提高物體識別的精度,本文利用RGB-D資訊訓練神經網路。由於卷積神經網路(本文用的是A. Krizhevsky在ImageNet ILSVRC 2011上用的模型,A. Krizhevsky, I. Sutskever, and G. E. Hinton,“Imagenet classification with deep convolutional neural networks,” in Advancesin Neural Information Processing Systems (NIPS), 2012, pp. 1097–1105.)大部分是使用RGB影象進行訓練,而深度圖是用灰度圖表示的,為了能將深度圖作為輸入,訓練神經網路,作者用了一個技巧,首先從深度圖中提取出需要識別的目標物體,然後對其上色,得到Colorized image,如下圖所示。

然後作者根據卷積神經網路輸出的結果,利用SVM(支援向量機)得到物體類別和姿態(這部分論文為詳細闡述,故不太瞭解具體是怎麼做的)。