
Hive自定義函式(UDF、UDAF)
當Hive提供的內建函式無法滿足你的業務處理需要時,此時就可以考慮使用使用者自定義函式。
UDF
使用者自定義函式(user defined function)–針對單條記錄。
建立函式流程
1、自定義一個Java類
2、繼承UDF類
3、重寫evaluate方法
4、打成jar包
6、在hive執行add jar方法
7、在hive執行建立模板函式
8、hql中使用
Demo01:
自定義一個Java類
package UDFDemo;
import org.apache.hadoop.hive.ql.exec.UDF;
import org.apache.hadoop.io.Text;
public 打成jar包UDFTest.jar
在hive執行add jar方法
在hive建立一個bigthan的函式,引入的類是UDF.UDFTest
add jar /liguodong/UDFTest.jar;
create temporary function bigthan as 'UDFDemo.UDFTest';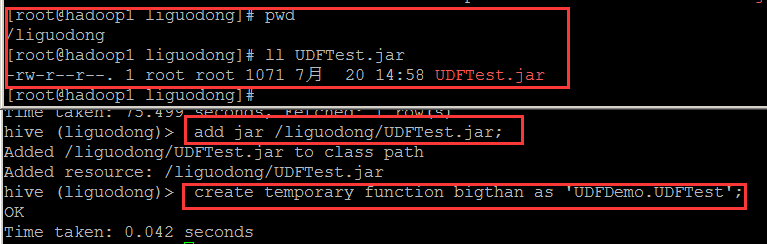
select no,num,bigthan(no,num) from testudf;
UDAF
UDAF(user defined aggregation function)使用者自定義聚合函式,針對記錄集合
開發UDAF通用有兩個步驟
第一個是編寫resolver類,resolver負責型別檢查,操作符過載。
第二個是編寫evaluator類,evaluator真正實現UDAF的邏輯
通常來說,頂層UDAF類繼承
org.apache.hadoop.hive.ql.udf.generic.GenericUDAFEvaluator裡面編寫巢狀類evaluator實現UDAF的邏輯。
一、實現resolver
resolver通常繼承
org.apache.hadoop.hive.ql.udf.GenericUDAFResolver2,但是更建議繼承AbstractGenericUDAFResolver,隔離將來hive介面的變化。
GenericUDAFResolver和GenericUDAFResolver2介面的區別是後面的允許evaluator實現可以訪問更多的資訊,例如DISTINCT限定符,萬用字元FUNCTION(*)。
二、實現evaluator
所有eva1uators必須繼承抽象類
org.apache.hadoop.hive.ql.udf.generic.GenericUDAFEvaluator。予類必須實現它的一些抽象方法,實現UDAF的邏輯。
Mode
這個類比較重要,它表示了udaf在mapreduce的各個階段,理解Mode的含義,就理解了hive的UDAF的執行流程。
public static enum Mode{
PARTIAL1,
PARTIAL2,
FINAL,
COMPLETE
};PARTIAL1:這個是mapreduce的map階段:從原始資料到部分資料聚合,將會呼叫iterate()和terminatePartial()。
PARTIAL2:這個是mapreduce的map端的Combiner階段,負責在map端合併map的資料;從部分資料聚合到部分資料聚合,將會呼叫merge()和terminatePartial()。
FINAL:mapreduce的reduce階段:從部分資料的聚合到完全聚合,將會呼叫merge()和terminate()。
COMPLETE:如果出現了這個階段,表示mapreduce只有map,沒有reduce,所以map端就直接出結果了;從原始資料直接到完全聚合,將會呼叫iterate()和terminate()
流程–無Combiner

流程–有Combiner
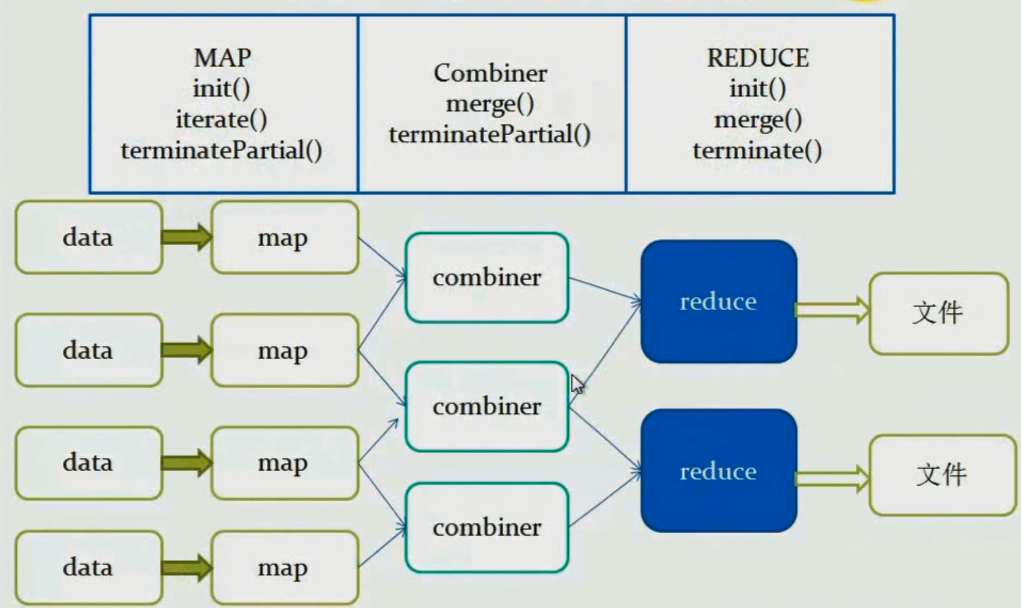
mapreduce階段呼叫函式
MAP
init()
iterate()
terminatePartial()
Combiner
merge()
terminatePartial()
REDUCE
init()
merge()
terminate()
檢視原始碼路徑
apache-hive-1.2.1-src\ql\src\java\org\apache\hadoop\hive\ql\udf\generic
例如:關於count函式的原始碼
package org.apache.hadoop.hive.ql.udf.generic;
import org.apache.commons.logging.Log;
import org.apache.commons.logging.LogFactory;
import org.apache.hadoop.hive.ql.exec.Description;
import org.apache.hadoop.hive.ql.exec.UDFArgumentException;
import org.apache.hadoop.hive.ql.metadata.HiveException;
import org.apache.hadoop.hive.ql.parse.SemanticException;
import org.apache.hadoop.hive.ql.util.JavaDataModel;
import org.apache.hadoop.hive.serde2.objectinspector.ObjectInspector;
import org.apache.hadoop.hive.serde2.objectinspector.primitive.LongObjectInspector;
import org.apache.hadoop.hive.serde2.objectinspector.primitive.PrimitiveObjectInspectorFactory;
import org.apache.hadoop.hive.serde2.typeinfo.TypeInfo;
import org.apache.hadoop.io.LongWritable;
/**
* This class implements the COUNT aggregation function as in SQL.
*/
@Description(name = "count",
value = "_FUNC_(*) - Returns the total number of retrieved rows, including "
+ "rows containing NULL values.\n"
+ "_FUNC_(expr) - Returns the number of rows for which the supplied "
+ "expression is non-NULL.\n"
+ "_FUNC_(DISTINCT expr[, expr...]) - Returns the number of rows for "
+ "which the supplied expression(s) are unique and non-NULL.")
public class GenericUDAFCount implements GenericUDAFResolver2 {
private static final Log LOG = LogFactory.getLog(GenericUDAFCount.class.getName());
@Override
public GenericUDAFEvaluator getEvaluator(TypeInfo[] parameters)
throws SemanticException {
// This method implementation is preserved for backward compatibility.
return new GenericUDAFCountEvaluator();
}
@Override
public GenericUDAFEvaluator getEvaluator(GenericUDAFParameterInfo paramInfo)
throws SemanticException {
TypeInfo[] parameters = paramInfo.getParameters();
if (parameters.length == 0) {
if (!paramInfo.isAllColumns()) {
throw new UDFArgumentException("Argument expected");
}
assert !paramInfo.isDistinct() : "DISTINCT not supported with *";
} else {
if (parameters.length > 1 && !paramInfo.isDistinct()) {
throw new UDFArgumentException("DISTINCT keyword must be specified");
}
assert !paramInfo.isAllColumns() : "* not supported in expression list";
}
return new GenericUDAFCountEvaluator().setCountAllColumns(
paramInfo.isAllColumns());
}
/**
* GenericUDAFCountEvaluator.
*
*/
public static class GenericUDAFCountEvaluator extends GenericUDAFEvaluator {
private boolean countAllColumns = false;
private LongObjectInspector partialCountAggOI;
private LongWritable result;
@Override
public ObjectInspector init(Mode m, ObjectInspector[] parameters)
throws HiveException {
super.init(m, parameters);
if (mode == Mode.PARTIAL2 || mode == Mode.FINAL) {
partialCountAggOI = (LongObjectInspector)parameters[0];
}
result = new LongWritable(0);
return PrimitiveObjectInspectorFactory.writableLongObjectInspector;
}
private GenericUDAFCountEvaluator setCountAllColumns(boolean countAllCols) {
countAllColumns = countAllCols;
return this;
}
/** class for storing count value. */
@AggregationType(estimable = true)
static class CountAgg extends AbstractAggregationBuffer {
long value;
@Override
public int estimate() { return JavaDataModel.PRIMITIVES2; }
}
@Override
public AggregationBuffer getNewAggregationBuffer() throws HiveException {
CountAgg buffer = new CountAgg();
reset(buffer);
return buffer;
}
@Override
public void reset(AggregationBuffer agg) throws HiveException {
((CountAgg) agg).value = 0;
}
@Override
public void iterate(AggregationBuffer agg, Object[] parameters)
throws HiveException {
// parameters == null means the input table/split is empty
if (parameters == null) {
return;
}
if (countAllColumns) {
assert parameters.length == 0;
((CountAgg) agg).value++;
} else {
boolean countThisRow = true;
for (Object nextParam : parameters) {
if (nextParam == null) {
countThisRow = false;
break;
}
}
if (countThisRow) {
((CountAgg) agg).value++;
}
}
}
@Override
public void merge(AggregationBuffer agg, Object partial)
throws HiveException {
if (partial != null) {
long p = partialCountAggOI.get(partial);
((CountAgg) agg).value += p;
}
}
@Override
public Object terminate(AggregationBuffer agg) throws HiveException {
result.set(((CountAgg) agg).value);
return result;
}
@Override
public Object terminatePartial(AggregationBuffer agg) throws HiveException {
return terminate(agg);
}
}
}Demo02:
執行過程與UDF類似,該Java、類的功能是第一列的值大於第二列計數加1。
package UDAFDemo;
import org.apache.hadoop.hive.ql.exec.UDFArgumentTypeException;
import org.apache.hadoop.hive.ql.metadata.HiveException;
import org.apache.hadoop.hive.ql.parse.SemanticException;
import org.apache.hadoop.hive.ql.udf.generic.AbstractGenericUDAFResolver;
import org.apache.hadoop.hive.ql.udf.generic.GenericUDAFEvaluator;
import org.apache.hadoop.hive.serde2.objectinspector.ObjectInspector;
import org.apache.hadoop.hive.serde2.objectinspector.PrimitiveObjectInspector;
import org.apache.hadoop.hive.serde2.objectinspector.primitive.PrimitiveObjectInspectorFactory;
import org.apache.hadoop.hive.serde2.objectinspector.primitive.PrimitiveObjectInspectorUtils;
import org.apache.hadoop.hive.serde2.typeinfo.TypeInfo;
import org.apache.hadoop.io.LongWritable;
public class UDAFTest extends AbstractGenericUDAFResolver{
//判斷
@Override
public GenericUDAFEvaluator getEvaluator(TypeInfo[] info)//欄位的描述資訊引數parameters
throws SemanticException {
if(info.length !=2){
throw new UDFArgumentTypeException(info.length-1,
"Exactly two argument is expected.");
}
//返回處理邏輯的類
return new GenericEvaluate();
}
public static class GenericEvaluate extends GenericUDAFEvaluator{
private LongWritable result;
private PrimitiveObjectInspector inputIO1;
private PrimitiveObjectInspector inputIO2;
//這個方法map與reduce階段都需要執行
/**
* map階段:parameters長度與udaf輸入的引數個數有關
* reduce階段:parameters長度為1
*/
//初始化
@Override
public ObjectInspector init(Mode m, ObjectInspector[] parameters)
throws HiveException {
super.init(m, parameters);
//返回最終的結果
result = new LongWritable(0);
inputIO1 = (PrimitiveObjectInspector) parameters[0];
if (parameters.length>1) {
inputIO2 = (PrimitiveObjectInspector) parameters[1];
}
return PrimitiveObjectInspectorFactory.writableBinaryObjectInspector;
}
//map階段
@Override
public void iterate(AggregationBuffer agg, Object[] parameters)//agg快取結果值
throws HiveException {
assert(parameters.length==2);
if(parameters==null || parameters[0]==null || parameters[1]==null){
return;
}
double base = PrimitiveObjectInspectorUtils.getDouble(parameters[0], inputIO1);
double tmp = PrimitiveObjectInspectorUtils.getDouble(parameters[1], inputIO2);
if(base > tmp){
((CountAgg)agg).count++;
}
}
//獲得一個聚合的緩衝物件,每個map執行一次
@Override
public AggregationBuffer getNewAggregationBuffer() throws HiveException {
CountAgg agg = new CountAgg();
reset(agg);
return agg;
}
//自定義類用於計數
public static class CountAgg implements AggregationBuffer{
long count;//計數,儲存每次臨時的結果
}
//重置
@Override
public void reset(AggregationBuffer countagg) throws HiveException {
CountAgg agg = (CountAgg)countagg;
agg.count=0;
}
//該方法當做iterate執行後,部分結果返回。
@Override
public Object terminatePartial(AggregationBuffer agg)
throws HiveException {
result.set(((CountAgg)agg).count);
return result;
}
@Override
public void merge(AggregationBuffer agg, Object partial)
throws HiveException {
if(partial != null){
long p = PrimitiveObjectInspectorUtils.getLong(partial, inputIO1);
((CountAgg)agg).count += p;
}
}
@Override
public Object terminate(AggregationBuffer agg) throws HiveException {
result.set(((CountAgg)agg).count);
return result;
}
}
}永久函式
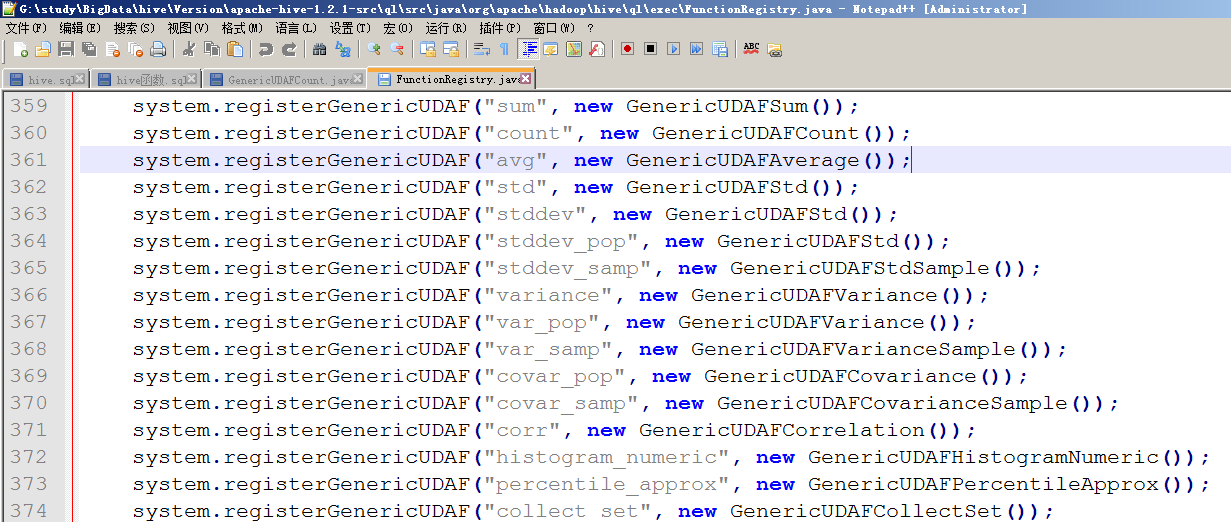
方式1、如果希望在hive中自定義一個函式,且能永久使用,
則修改原始碼新增相應的函式類,然後在修改ql/src/java/org/apache/hadoop/hive/ql/exec/FunctionRegistry.java類,新增相應的註冊函式程式碼registerUDF("parse_url",UDFParseUrl.class,false);。
方式2、hive -i ‘file’
方式3、新建hiverc檔案
1、jar包放到安裝日錄下或者指定目錄下
2、${HIVE_HOME}/bin目錄下有個.hiverc檔案,它是隱藏檔案。
3、把初始化語句載入到檔案中
vi .hiverc
add jar /liguodong/UDFTest.jar;
create temporary function bigthan as 'UDFDemo.UDFTest';然後開啟hive時,它會自動執行.hiverc檔案。