
高效能伺服器架構思路(二)——緩衝清理策略
雖然使用快取思想似乎是一個很簡單的事情,但是快取機制卻有一個核心的難點,就是——快取清理。我們所說的快取,都是儲存一些資料,但是這些資料往往是會變化的,我們要針對這些變化,清理掉儲存的“髒”資料,卻可能不是那麼容易。
首先我們來看看最簡單的快取資料——靜態資料。這種資料往往在程式的執行時是不會變化的,比如Web伺服器記憶體中快取的HTML檔案資料,就是這種。事實上,所有的不是由外部使用者上傳的資料,都屬於這種“執行時靜態資料”。一般來說,我們對這種資料,可以採用兩種建立快取的方法:一是程式一啟動,就一股腦把所有的靜態資料從檔案或者資料庫讀入記憶體;二就是程式啟動的時候並不載入靜態資料,而是等有使用者訪問相關資料的時候,才去載入,這也就是所謂lazy load的做法。第一種方法程式設計比較簡單,程式的記憶體啟動後就穩定了,不太容易出現記憶體漏洞(如果載入的快取太多,程式在啟動後立刻會因記憶體不足而退出,比較容易發現問題);第二種方法程式啟動很快,但要對快取佔用的空間有所限制或者規劃,否則如果要快取的資料太多,可能會耗盡記憶體,導致線上服務中斷。
一般來說,靜態資料是不會“髒”的,因為沒有使用者會去寫快取中的資料。但是在實際工作中,我們的線上服務往往會需要“立刻”變更一些快取資料。比如在入口網站上釋出了一條新聞,我們會希望立刻讓所有訪問的使用者都看到。按最簡單的做法,我們一般只要重啟一下伺服器程序,記憶體中的快取就會消失了。對於靜態快取的變化頻率非常低的業務,這樣是可以的,但是如果是新聞網站,就不能每隔幾分鐘就重啟一下WEB伺服器程序,這樣會影響大量線上使用者的訪問。常見的解決這類問題有兩種處理策略:
第一種是使用控制命令。簡單來說,就是在伺服器程序上,開通一個實時的命令埠,我們可以通過網路資料包(如UDP包),或者Linux系統訊號(如kill SIGUSR2程序號)之類的手段,傳送一個命令訊息給伺服器程序,讓程序開始清理快取。這種清理可能執行的是最簡單的“全部清理”,也有的可以細緻一點的,讓命令訊息中帶有“想清理的資料ID”這樣的資訊,比如我們傳送給WEB伺服器的清理訊息網路包中會帶一個字串URL,表示要清理哪一個HTML檔案的快取。這種做法的好處是清理的操作很精準,可以明確的控制清理的時間和資料。但是缺點就是比較繁瑣,手工去編寫傳送這種命令很煩人,所以一般我們會把清理快取命令的工作,編寫到上傳靜態資料的工具當中,比如結合到網站的內容釋出系統中,一旦編輯提交了一篇新的新聞,釋出系統的程式就自動的傳送一個清理訊息給WEB伺服器。
第二種是使用欄位判斷邏輯。也就是伺服器程序,會在每次讀取快取前,根據一些特徵資料,快速的判斷記憶體中的快取和源資料內容,是否有不一致(是否髒)的地方,如果有不一致的地方,就自動清理這條資料的快取。這種做法會消耗一部分CPU,但是就不需要人工去處理清理快取的事情,自動化程度很高。現在我們的瀏覽器和WEB伺服器之間,就有用這種機制:檢查檔案MD5;或者檢查檔案最後更新時間。具體的做法,就是每次瀏覽器發起對WEB伺服器的請求時,除了傳送URL給伺服器外,還會發送一個快取了此URL對應的檔案內容的MD5校驗串、或者是此檔案在伺服器上的“最後更新時間”(這個校驗串和“最後更新時間”是第一次獲的檔案時一併從伺服器獲得的);伺服器收到之後,就會把MD5校驗串或者最後更新時間,和磁碟上的目標檔案進行對比,如果是一致的,說明這個檔案沒有被修改過(快取不是“髒”的),可以直接使用快取。否則就會讀取目標檔案返回新的內容給瀏覽器。這種做法對於伺服器效能是有一定消耗的,所以如果往往我們還會搭配其他的快取清理機制來用,比如我們會在設定一個“超時檢查”的機制:就是對於所有的快取清理檢查,我們都簡單的看看快取存在的時間是否“超時”了,如果超過了,才進行下一步的檢查,這樣就不用每次請求都去算MD5或者看最後更新時間了。但是這樣就存在“超時”時間內快取變髒的可能性。
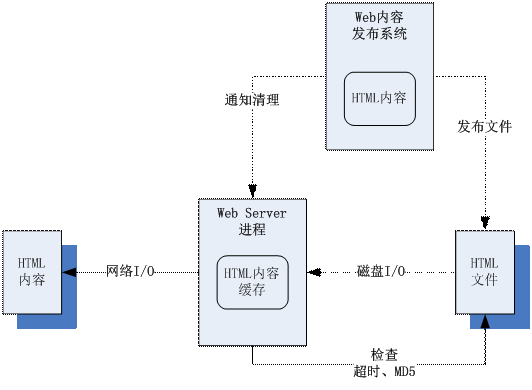
WEB伺服器靜態快取例子
上面說了執行時靜態的快取清理,現在說說執行時變化的快取資料。在伺服器程式執行期間,如果使用者和伺服器之間的互動,導致了快取的資料產生了變化,就是所謂“執行時變化快取”。比如我們玩網路遊戲,登入之後的角色資料就會從資料庫裡讀出來,進入伺服器的快取(可能是堆記憶體或者memcached、共享記憶體),在我們不斷進行遊戲操作的時候,對應的角色資料就會產生修改的操作,這種快取資料就是“執行時變化的快取”。這種執行時變化的資料,有讀和寫兩個方面的清理問題:由於快取的資料會變化,如果另外一個程序從資料庫讀你的角色資料,就會發現和當前遊戲裡的資料不一致;如果伺服器程序突然結束了,你在遊戲裡升級,或者撿道具的資料可能會從記憶體快取中消失,導致你白忙活了半天,這就是沒有回寫(快取寫操作的清理)導致的問題。這種情況在電子商務領域也很常見,最典型的就是火車票網上購買的系統,火車票資料快取在記憶體必須有合適的清理機制,否則讓兩個買了同一張票就麻煩了,但如果不快取,大量使用者同時搶票,伺服器也應對不過來。因此在執行時變化的資料快取,應該有一些特別的快取清理策略。
在實際執行業務中,執行變化的資料往往是根據使用使用者的增多而增多的,因此首先要考慮的問題,就是快取空間不夠的可能性。我們不太可能把全部資料都放到快取的空間裡,也不可能清理快取的時候就全部資料一起清理,所以我們一般要對資料進行分割,這種分割的策略常見的有兩種:一種是按重要級來分割,一種是按使用部分分割。
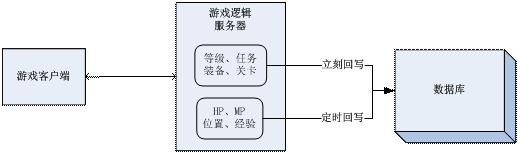
先舉例說說“按重要級分割”,在網路遊戲中,同樣是角色的資料,有些資料的變化可能會每次修改都立刻回寫到資料庫(清理寫快取),其他一些資料的變化會延遲一段時間,甚至有些資料直到角色退出遊戲才回寫,如玩家的等級變化(升級了),武器裝備的獲得和消耗,這些玩家非常看重的資料,基本上會立刻回寫,這些就是所謂最重要的快取資料。而玩家的經驗值變化、當前HP、MP的變化,就會延遲一段時間才寫,因為就算丟失了快取,玩家也不會太過關注。最後有些比如玩家在房間(地區)裡的X/Y座標,對話聊天的記錄,可能會退出時回寫,甚至不回寫。這個例子說的是“寫快取”的清理,下面說說“讀快取”的按重要級分割清理。
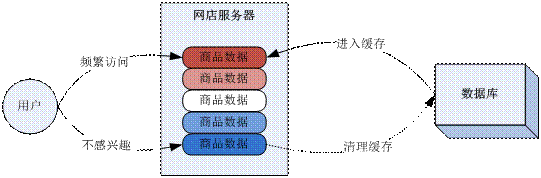
假如我們寫一個網店系統,裡面容納了很多產品,這些產品有一些會被使用者頻繁檢索到,比較熱銷,而另外一些商品則沒那麼熱銷。熱銷的商品的餘額、銷量、評價都會比較頻繁的變化,而滯銷的商品則變化很少。所以我們在設計的時候,就應該按照不同商品的訪問頻繁程度,來決定快取哪些商品的資料。我們在設計快取的結構時,就應該構建一個可以統計快取讀寫次數的指標,如果有些資料的讀寫頻率過低,或者空閒(沒有人讀、寫快取)時間超長,快取應該主動清理掉這些資料,以便其他新的資料能進入快取。這種策略也叫做“冷熱交換”策略。實現“冷熱交換”的策略時,關鍵是要定義一個合理的冷熱統計演算法。一些固定的指標和演算法,往往並不能很好的應對不同硬體、不同網路情況下的變化,所以現在人們普遍會用一些動態的演算法,如Redis就採用了5種,他們是:
-
根據過期時間,清理最長時間沒用過的
-
根據過期時間,清理即將過期的
-
根據過期時間,任意清理一個
-
無論是否過期,隨機清理
-
無論是否過期,根據LRU原則清理:所謂LRU,就是Least Recently Used,最近最久未使用過。這個原則的思想是:如果一個數據在最近一段時間沒有被訪問到,那麼在將來他被訪問的可能性也很小。LRU是在作業系統中很常見的一種原則,比如記憶體的頁面置換演算法(也包括FIFO,LFU等),對於LRU的實現,還是非常有技巧的,但是本文就不詳細去說明如何實現,留待大家上網搜尋“LRU”關鍵字學習。
資料快取的清理策略其實遠不止上面所說的這些,要用好快取這個武器,就要仔細研究需要快取的資料特徵,他們的讀寫分佈,資料之中的差別。然後最大化的利用業務領域的知識,來設計最合理的快取清理策略。這個世界上不存在萬能的優化快取清理策略,只存在針對業務領域最優化的策略,這需要我們程式設計師深入理解業務領域,去發現數據背後的規律。