
10026---Kafka詳解二、如何配置Kafka叢集
Kafka叢集配置比較簡單,為了更好的讓大家理解,在這裡要分別介紹下面三種配置
單節點:一個broker的叢集
單節點:多個broker的叢集
多節點:多broker叢集
一、單節點單broker例項的配置
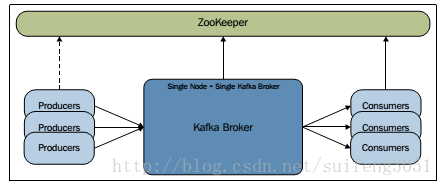
1. 首先啟動zookeeper服務
Kafka本身提供了啟動zookeeper的指令碼(在kafka/bin/目錄下)和zookeeper配置檔案(在kafka/config/目錄下),首先進入Kafka的主目錄(可通過 whereis kafka命令查詢到):
zookeeper配置檔案的一些重要屬性:[[email protected] kafka-0.8]# bin/zookeeper-server-start.sh config/zookeeper.properties
# Data directory where the zookeeper snapshot is stored.
dataDir=/tmp/zookeeper
# The port listening for client request
clientPort=21812. 啟動Kafka broker
執行kafka提供的啟動kafka服務指令碼即可:[[email protected]
broker配置檔案中的重要屬性:
# broker的id. 每個broker的id必須是唯一的.
Broker.id=0
# 存放log的目錄
log.dir=/tmp/kafka8-logs
# Zookeeper 連線串
zookeeper.connect=localhost:21813. 建立一個僅有一個Partition的topic
bin/kafka-topics.sh --create --zookeeper localhost:2181 --replication-factor 1 --partitions 1 --topic kafkatopic
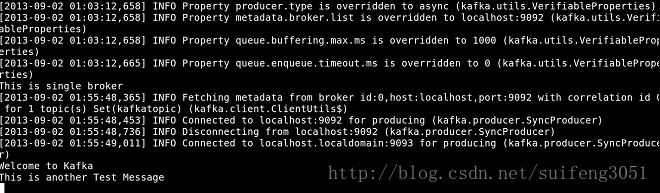
4. 用Kafka提供的生產者客戶端啟動一個生產者程序來發送訊息
[[email protected] kafka-0.8]# bin/kafka-console-producer.sh --broker-list localhost:9092 --topic kafkatopicbroker-list:定義了生產者要推送訊息的broker地址,以<IP地址:埠>形式
topic:生產者傳送給哪個topic
然後你就可以輸入一些訊息了,如下圖:
相關推薦
10026---Kafka詳解二、如何配置Kafka叢集
原文 Kafka叢集配置比較簡單,為了更好的讓大家理解,在這裡要分別介紹下面三種配置 單節點:一個broker的叢集 單節點:多個broker的叢集 多節點:多broker叢集 一、單節點單broker例項的配置 1. 首先啟動zookeeper服務 Kafka本身提供
kafka詳解三:開發Kafka應用
問題導讀1.Kafka系統由什麼組成?2.Kafka中和producer相關的API是什麼?一、整體看一下Kafka我們知道,Kafka系統有三大元件:Producer、Consumer、broker 。 file:///C:/Users/ADMINI~1/AppData/
Kafka 詳解(二)------集群搭建
需要 kafka ast enter 安裝過程 簡單 keep 三臺 sof 這裏通過 VMware ,我們安裝了三臺虛擬機,用來搭建 kafka集群,虛擬機網絡地址如下: hostname ipaddress
Kafka 詳解(二)------叢集搭建
這裡通過 VMware ,我們安裝了三臺虛擬機器,用來搭建 kafka叢集,虛擬機器網路地址如下: hostname ipaddress &nbs
Kafka概念和關於springboot配置Kafka引數詳解
1.基本概念 *Producer: 訊息生產者,往Topic釋出訊息 *Consumer: 訊息消費者,往Topic取訊
JAVAWEB開發之mybatis詳解(二)——高階對映、查詢快取、mybatis與Spring整合以及懶載入的配置和逆向工程
<?xml version="1.0" encoding="UTF-8"?> <!DOCTYPE generatorConfiguration PUBLIC "-//mybatis.org//DTD MyBatis Generator Configuration 1.0//EN" "ht
大數據入門第十七天——storm上遊數據源 之kafka詳解(一)入門
不同 這也 接受 blog 存儲 發送 records ant post 一、概述 1.kafka是什麽 根據標題可以有個概念:kafka是storm的上遊數據源之一,也是一對經典的組合,就像郭德綱和於謙 根據官網:http://kafka.apa
虛擬機網絡配置詳解(NAT、橋接、Hostonly)
dev 設置 包括 gem f11 key 註意 box ccf VirtualBox中有四種網絡連接方式: NAT Bridged Adapter Internal Host-only Adapter VMWare中有三種,其實它跟VMWare的網絡連接方式都是一樣的
Java併發(十八):阻塞佇列BlockingQueue BlockingQueue(阻塞佇列)詳解 二叉堆(一)之 圖文解析 和 C語言的實現 多執行緒程式設計:阻塞、併發佇列的使用總結 Java併發程式設計:阻塞佇列 java阻塞佇列 BlockingQueue(阻塞佇列)詳解
阻塞佇列(BlockingQueue)是一個支援兩個附加操作的佇列。 這兩個附加的操作是:在佇列為空時,獲取元素的執行緒會等待佇列變為非空。當佇列滿時,儲存元素的執行緒會等待佇列可用。 阻塞佇列常用於生產者和消費者的場景,生產者是往佇列裡新增元素的執行緒,消費者是從佇列裡拿元素的執行緒。阻塞佇列就是生產者
互斥量、條件變數與pthread_cond_wait()函式的使用,詳解(二)
1.Linux“執行緒” 程序與執行緒之間是有區別的,不過linux核心只提供了輕量程序的支援,未實現執行緒模型。Linux是一種“多程序單執行緒”的作業系統。Linux本身只有程序的概念,而其所謂的“執行緒”本質上在核心裡仍然是程序。 大家知道,
B族樹詳解(二叉搜尋樹、B-樹、B+樹、B*樹)
二叉搜尋樹 二叉搜尋樹: 1.所有非葉子結點至多擁有兩個兒子(Left和Right); 2.所有結點儲存一個關鍵字; 3.非葉子結點的左指標指向小於其關鍵字的子樹,右指標指向大於其關鍵字的子樹; 如: B樹的搜尋,
logback 配置詳解—logger、root
正文1、根節點<configuration>包含的屬性scan:當此屬性設定為true時,配置檔案如果發生改變,將會被重新載入,預設值為true。scanPeriod:設定監測配置檔案是否有修改的時間間隔,如果沒有給出時間單位,預設單位是毫秒。當scan為true
Elasticsearch增、刪、改、查操作深入詳解(二)
引言: 對於剛接觸ES的童鞋,經常搞不明白ES的各個概念的含義。尤其對“索引”二字更是與關係型資料庫混淆的不行。本文通過對比關係型資料庫,將ES中常見的增、刪、改、查操作進行圖文呈現。能加深你對ES的理解。同時,也列舉了kibana下的圖形化展示。 ES Restful API GET、PO
詳解二維陣列與指標、指標陣列、陣列指標
int* p=a[0];//此時P是指向一維陣列的指標。P++後,p指向 a[0][1]。 int (*p1)[n];p1=a;p1++後,p1指向a[1][0]; int *p=a[0]; 則陣列a的元素a[1][2]對應的指標為:p+1*4+2 元素a[1][2]
java實現標準化考試系統詳解(二)-----資料庫、資料表的規劃和題庫增刪改查
(一)、資料庫、資料表的規劃 首先我們需要考慮一下作為考試系統我們需要哪些資料,這些資料將以後作為欄位值出現。 我們先來看看這張圖: 圖中框起來的部分基本上就是我們需要的資料,細數數就是: 1.試題序號,它作為主鍵出現不可以重複(id) 2.適用工程,可以理解為這個題適用
FastDFS的配置、部署與API使用解讀(4)FastDFS配置詳解之Client配置
一種方式是通過呼叫ClientGlobal類的初始化方法對配置檔案進行載入,另一種是通過呼叫API逐一設定配置引數。後一種方式對於使用Zookeeper等載入屬性的方式很方便。 1. 載入配置檔案: String configFileName = "conf/dfs-c
kafka入門:簡介、使用場景、設計原理、配置及叢集搭建
問題導讀: 1.zookeeper在kafka的作用是什麼? 2.kafka中幾乎不允許對訊息進行“隨機讀寫”的原因是什麼? 3.kafka叢集consumer和producer狀態資訊是如何儲存的? 4.partitions設計的目的的根本原因是什麼? 一、入
流式計算--Kafka詳解
理解storm、spark streamming等流式計算的資料來源、理解JMS規範、理解Kafka核心元件、掌握Kakfa生產者API、掌握Kafka消費者API。對流式計算的生態環境有深入的瞭解,具備流式計算專案架構的能力。所以學習kafka要掌握以下幾點
【STM庫應用】stm32 之 TIM (詳解二 脈衝寬度、週期測量)
昨天已經把這個研究出來了,但是由於該專利申請書,一直沒有時間上傳,今天補上! 今天主要是用TIM3進行PWM的輸入模式,進行對矩形波的脈衝訊號寬度以及其週期進行測量,先來看一幅圖。 圖1 TIM內部邏輯圖 我們先來看看datasheet上是怎麼說的:
Kafka詳解安裝
一:介紹 Kafka是最初由Linkedin公司開發,是一個分散式、支援分割槽的(partition)、多副本的(replica),基於zookeeper協調的分散式訊息系統,它的最大的特性就是可以實時的處理大量資料以滿足各種需求場景:比如基於hadoop的批