
資料庫的自我修煉——阿里雲MongoDB備份恢復功能說明和原理介紹
本次直播視訊精彩回顧,戳這裡!
直播涉及到的PPT,戳這裡!
演講嘉賓簡介:
鄭涔(花名:明儼) 阿里雲技術專家,2011年加入阿里,曾參與TFS、Tengine研發,目前主要參與阿里雲MongoDB雲資料庫服務研發,主要關注分散式儲存、資料庫等領域。
本篇文章來自於阿里雲技術專家鄭涔(明儼)在2018年《Redis、MongoDB、HBase大咖直播大講堂》技術直播峰會中的分享,該分享整體由四個部分構成:
1、MongoDB備份恢復
2、阿里雲MongoDB備份恢復
3、阿里雲MongoDB Sharding備份恢復
4、阿里雲MongoDB物理熱備份恢復
初來乍到——MongoDB備份恢復
MongoDB備份恢復在備份方法上總體來說分為兩部分:邏輯備份和物理備份。
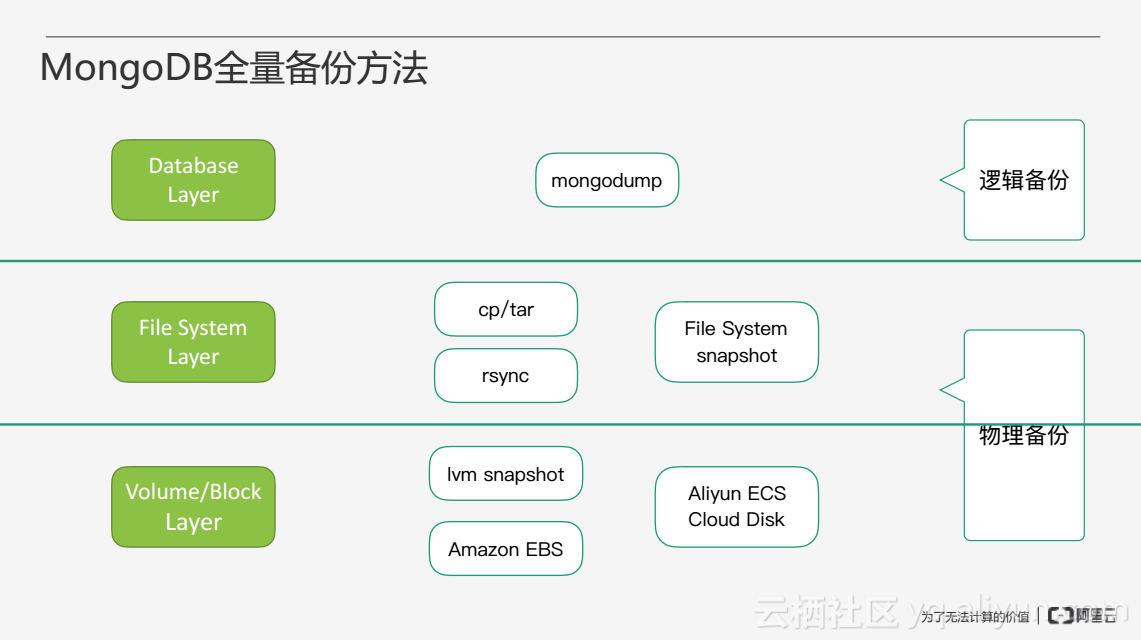
邏輯備份就是通過mongodump和mongorestore兩個工具在資料庫層將MongoDB的資料進行匯出和匯入。物理備份的作用更接近底層一些,例如作用在檔案系統上,通過cp和tar檔案系統工具,將MongoDB的物理檔案拷貝走進行備份。物理備份還有一種方式是通過邏輯卷或者塊裝置更為底層的部分進行備份,例如配置一個邏輯卷採用lvm snapshot的方法去做磁碟的快照,或者利用像阿里雲的ECS雲伺服器執行雲盤的快照功能,從而實現物理備份。
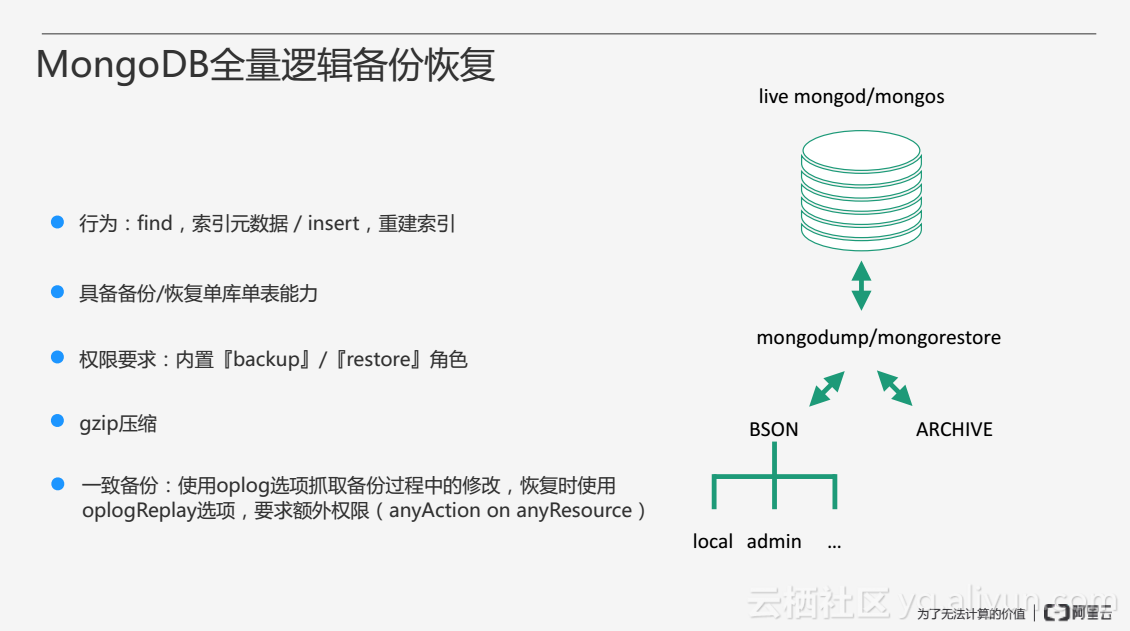
MongoDB全量邏輯備份恢復是通過mongodump和mongorestore兩個工具來實現的,這兩個工具不僅可以作用在正在執行的MongoDB上,也可以作用在Sharding的mongos上,把整個資料庫的資料進行匯入匯出。全量邏輯備份恢復可以輸出為兩種格式:第一種為BSON格式,以這種方式匯出之後可以看到本地磁碟上會有很多目錄,每一個數據庫都會有各自的BSON格式的資料;第二種為歸檔的格式,即把所有資料庫的資料輸出成一個檔案,可以方便地實現流式備份和恢復。
全量邏輯備份的基本機制是通過資料庫層的一些結構來實現的,在當本的過程中通過資料庫find的方法,將資料庫中的資料全部查詢出來,如果資料為索引時,匯出的只是一些元資料,例如索引建在哪個欄位上、什麼型別的索引、索引有哪些選項這些元資料,並沒有把索引的資料本身匯出來,在恢復時通過insert方法重新將資料插回到資料庫當中。在恢復的過程中需要重建索引,如果索引的資料量非常大,重建索引的過程將花費很長的時間,成為了全量邏輯備份比較大的問題。
全量邏輯備份恢復的一大優點,即備份和恢復單庫單表的能力,方便於某些場景的應用,例如緊急狀態下需要恢復某一資料庫的某一個表,此時不需要下載整個全量的資料備份,只需單獨把想要恢復的表進行恢復即可。
全量邏輯備份通過資料庫介面訪問資料庫,如果資料庫配置一個認證需要賬號和密碼進行訪問時會有一些許可權的要求,可以通過MongoDB內建的backup和restore兩個角色進行備份和恢復。
此外,全量邏輯備份可以指定進行gzip壓縮,從而減少資料備份的大小,節省儲存成本。
在MongoDB全量邏輯備份過程中資料庫可以接受外部正常的讀寫,使用oplog選項抓取備份過程中的修改,恢復時使用oplogReplay選項,此時需要較高的額外許可權,從而獲取一致的備份,確保資料備份的過程中,對資料的修改也會進行備份。
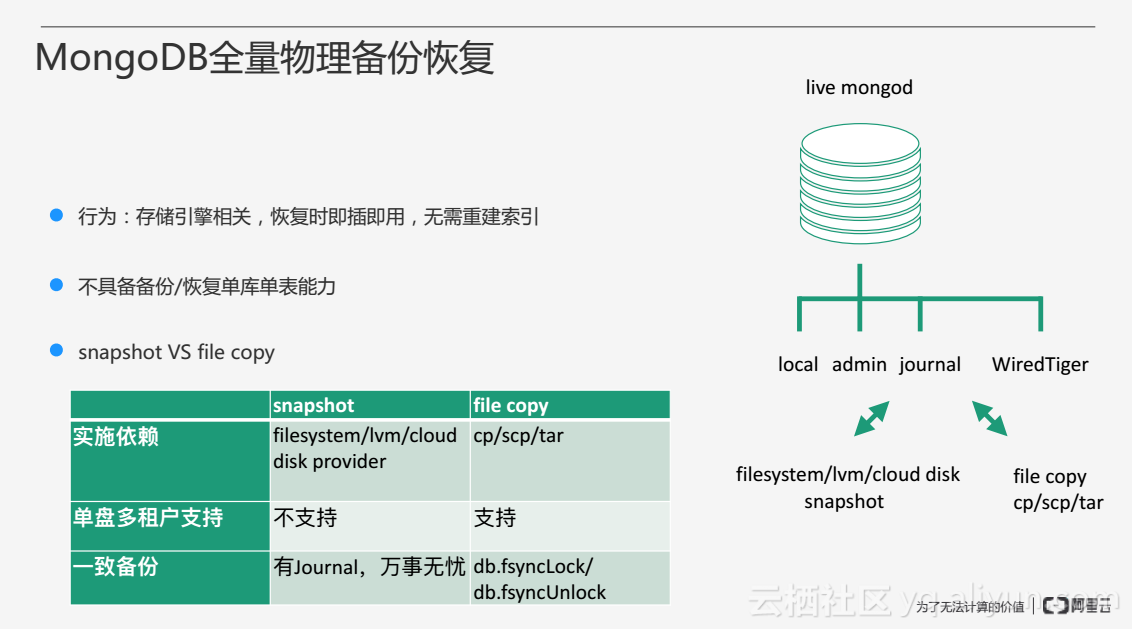
MongoDB全量物理備份恢復通過某些手段將物理檔案拷貝走進行備份,其中MongoDB可以支援多個儲存引擎,物理檔案與儲存引擎的儲存佈局相關,所以物理備份恢復無法做到跨儲存引擎的備份恢復,例如使用WiredTiger的儲存引擎備份的資料只能恢復成WiredTiger,不能恢復成其他的儲存引擎。另外物理備份有一個很大的好處是,由於備份時將所有的域塊進行備份,在恢復的過程中不需要重建索引,只需要將備份資料下載下來,提起程序即可使用,相對全量邏輯備份更為高效。
然而全量物理備份的不足之處在於,它不具備備份和恢復單庫單表的能力,檔案之間相互關聯,無法將某一個數據庫的單獨檔案提取恢復出來。
全量物理備份方法通常可以分為兩大類:第一類是通過一些系統元件的snapshot快照功能來實現備份,對系統元件有些依賴,在單盤多租戶的情況下,無法做到對塊盤上每一個MongoDB例項單獨進行備份,依賴於配置MongoDB的Journal實現宕機恢復,從而達到一致備份;第二類是使用檔案拷貝簡單的方式通過檔案系統進行物理備份,可以做到目錄級的拷貝,支援單盤多租戶的資料拷貝,在檔案拷貝開始之前需要執行db.fsyncLock的命令,即對MongoDB的全域性加一個寫鎖,在整個備份的過程中資料庫無法提供服務,物理檔案拷貝完畢執行db.fsynUnclock解鎖命令,間接達到一致備份的效果。
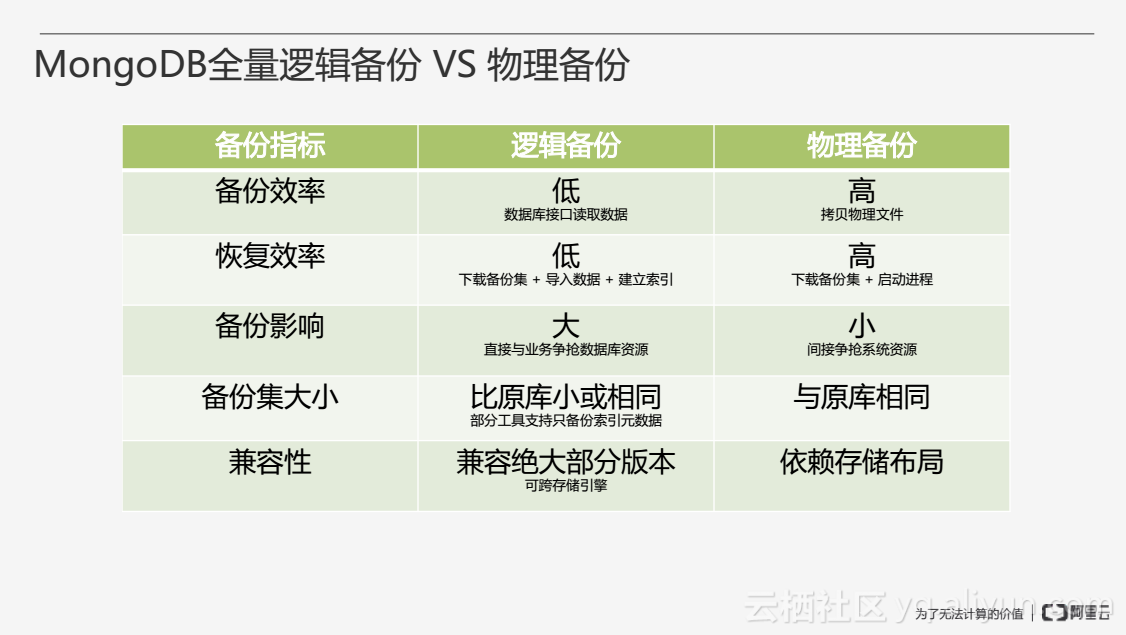
總體上來看,在備份效率上,邏輯備份不如物理備份。邏輯備份通過資料庫介面讀取資料,當邏輯備份資料量很小、條目很多時,效率會很低,物理備份時物理檔案一般會經過檔案壓縮,拷貝的資料相對來說比較少,同時物理備份較充分地使用系統資源,效率會較高。在恢復效率上,邏輯備份也低於物理備份。邏輯備份需要匯入資料和重建索引,而物理備份直接啟動程序即可。在備份影響上,備份影響主要指在備份的過程中是否對一些正常的業務訪問產生影響,由於邏輯備份通過資料庫介面讀取資料,它將直接與業務爭搶資料庫資源,而物理備份間接爭搶系統的資源,相對來說備份影響比較小。在備份集的大小上,由於邏輯備份沒有備份索引資料,一般比原資料庫小或相同,而物理備份與原資料庫是一模一樣的。在相容性上,邏輯備份優於物理備份,物理備份與儲存引擎相關,無法做到跨儲存引擎的備份恢復,而邏輯備份相容絕大部分版本。同時,物理備份的成功率比邏輯備份高很多,在某些場景邏輯備份無法進行恢復。
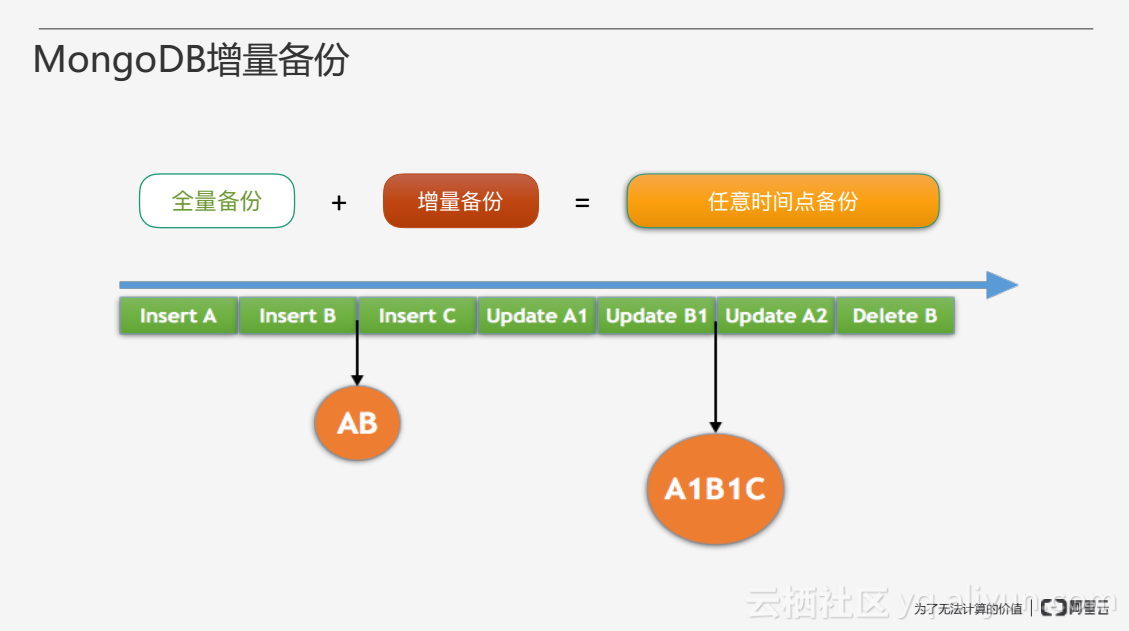
在MongoDB副本集有oplog進行主備同步,增量備份就是採集oplog並進行儲存,全量備份加增量備份就可以實現任意時間點的備份。
厚德載物——阿里雲MongoDB備份恢復
阿里雲MongoDB備份恢復主要分為四大塊:備份、恢復、備份儲存和備份有效性驗證。
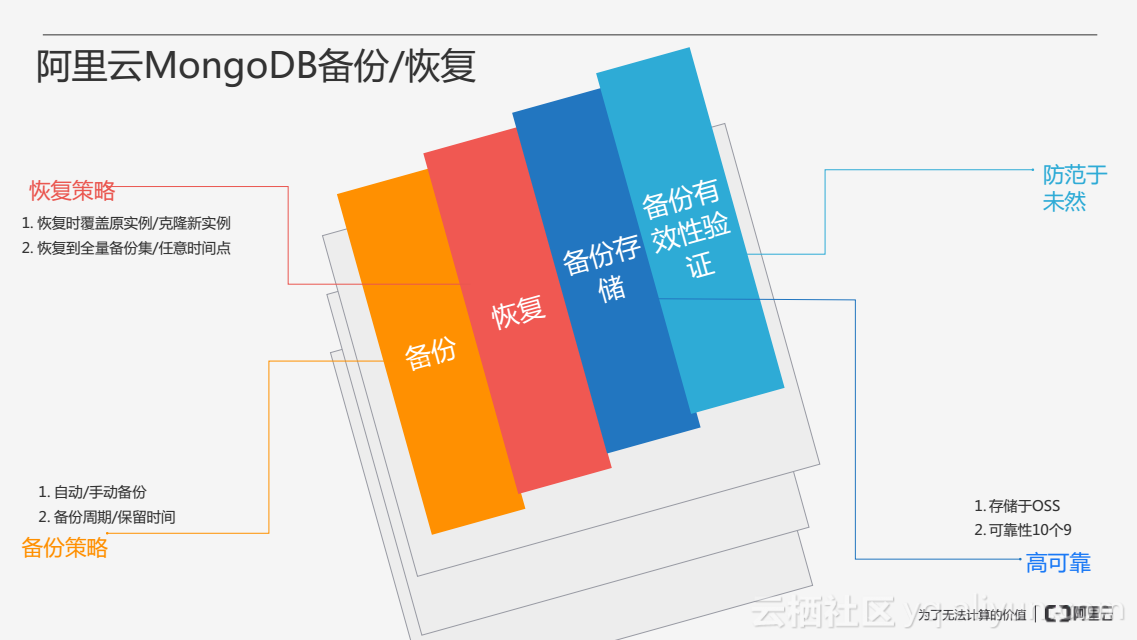
備份當中可以定製一些備份策略,為使用者的MongoDB做一些自動備份,使用者也可以在控制檯進行手動備份,同時使用者可以指定一個備份週期和保留時間對備份進行安排。恢復策略中使用者可以選擇恢復時覆蓋原來的例項或者克隆一個新的例項,也可以指定恢復的力度,選擇恢復到全量的備份集或者恢復到指定的時間點。備份儲存中,將資料儲存在阿里雲OSS上具有10個9的可靠性。備份有效性驗證中,定期對MongoDB例項的備份做一些有效性的驗證,避免恢復備份時發現備份出現問題,確保備份可以進行恢復。
以下為阿里雲MongoDB控制檯的兩個主要介面:
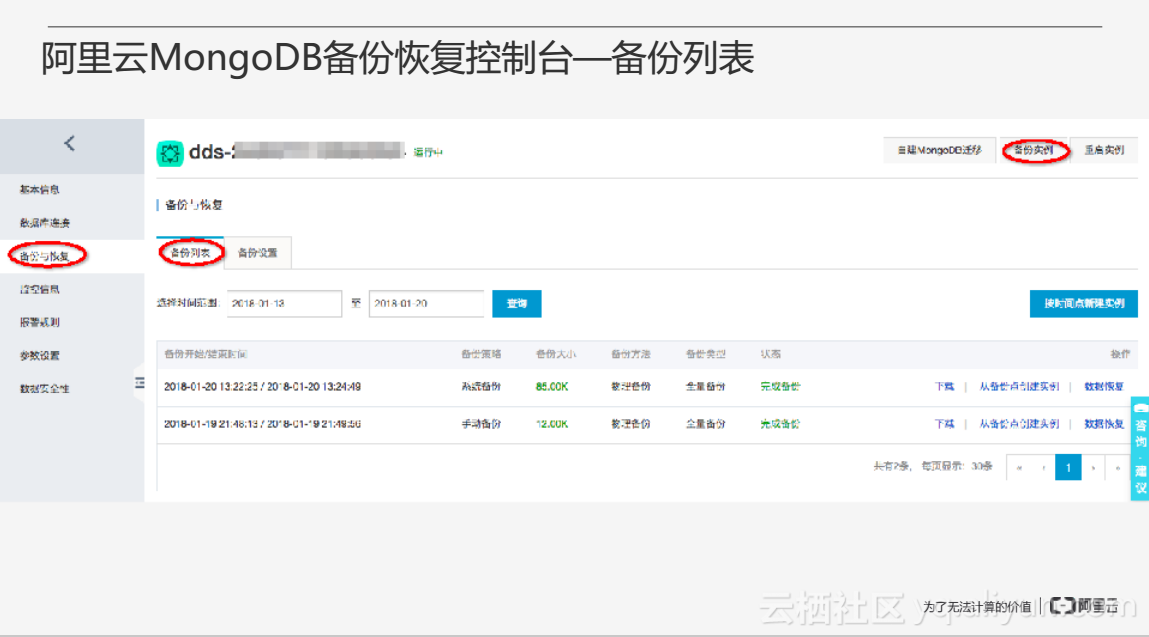
上圖為備份列表介面,可以看到備份的一些情況,包括備份的完成時間、是否為自動備份、手動備份等。使用者可以點選右上角的備份例項進行手動備份,可以下載備份、根據備份建立例項或者指定一個時間點新建例項、克隆例項。
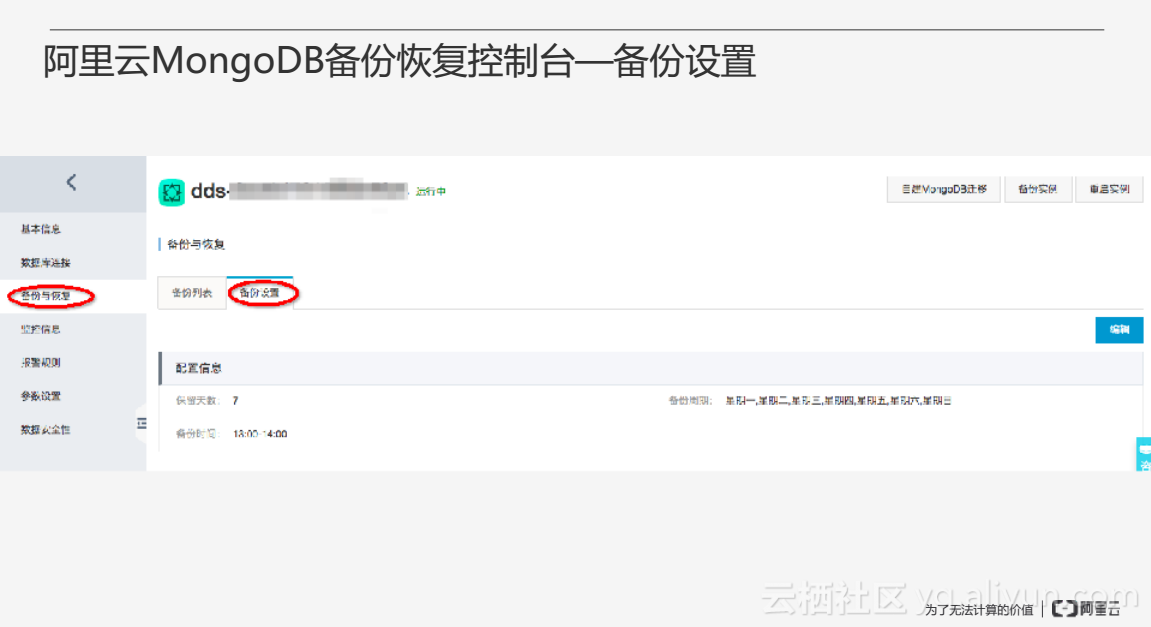
上圖為備份設定介面,使用者可以制定一些備份策略,包括備份的保留天數、備份的週期等。
精益求精——阿里雲MongoDB Sharding備份恢復
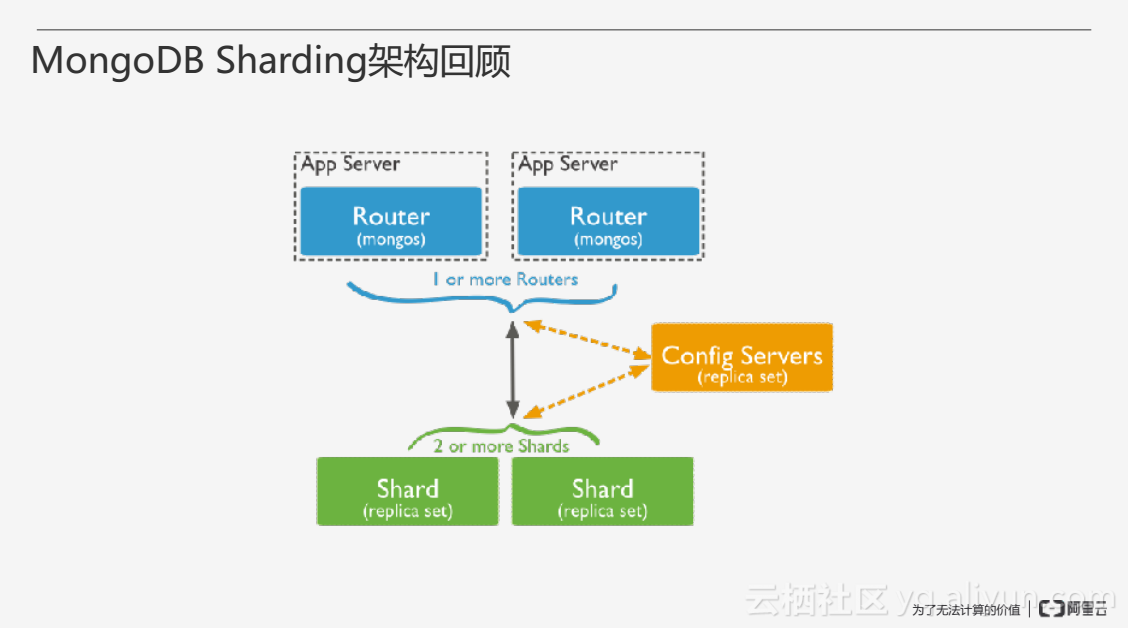
MongoDB Sharding架構主要由三大元件構成:藍色部分為路由節點mongos,它是無狀態的、沒有儲存資料的,不需要進行備份;綠色部分為Shard叢集,用於儲存使用者分片的資料,通過副本集的方式實現高可用,需要進行資料備份;黃色部分為Config Servers,主要存放叢集當中的元資料,作為副本集同樣需要進行備份。
面對MongoDB Sharding出現的問題,阿里雲是如何進行有效解決的呢?
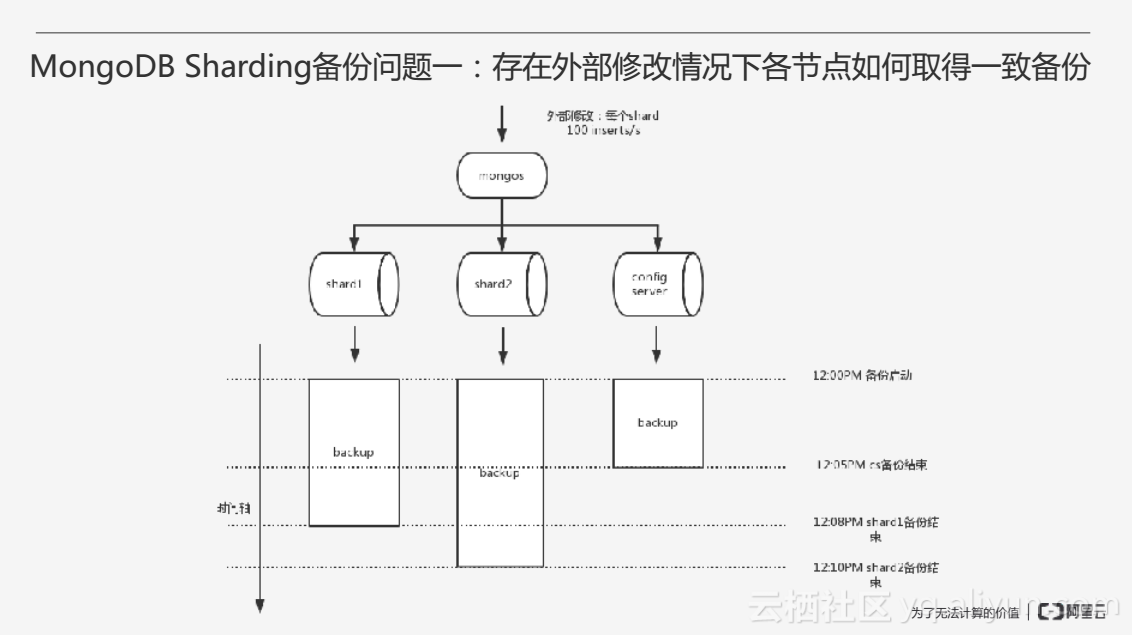
第一個普遍的問題是關於叢集多個節點在外部修改情況下如何取得一致備份。在一個叢集當中的多個節點和每一個節點的容量是不同的,導致節點備份的耗時不同,當對應用進行寫入時,由於每個節點備份結束的時間不同,有些節點的備份會多包含一些新寫入的資料,其中備份結束的時間點很難進行確定。
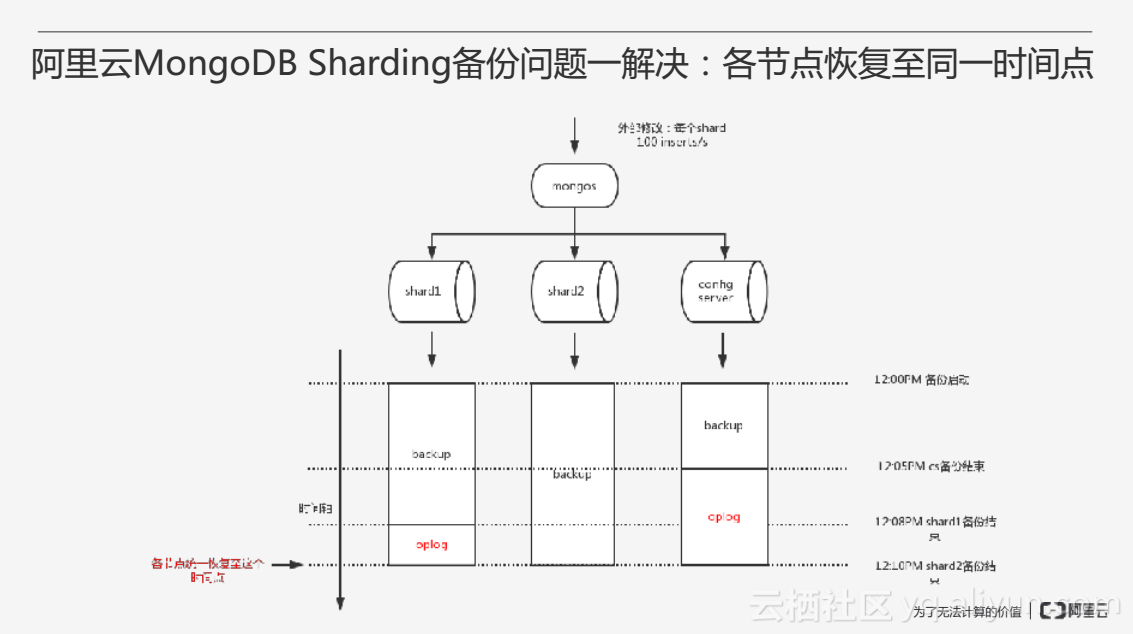
針對問題一,阿里雲採用全量備份加增量備份可以做到各節點備份恢復至同一時間點,在備份結束比較早的節點可以多抓取一些oplog,備份結束比較晚的節點可以少抓取一些oplog,從而保證各自節點的備份加oplog能夠對應到同一個時間點。
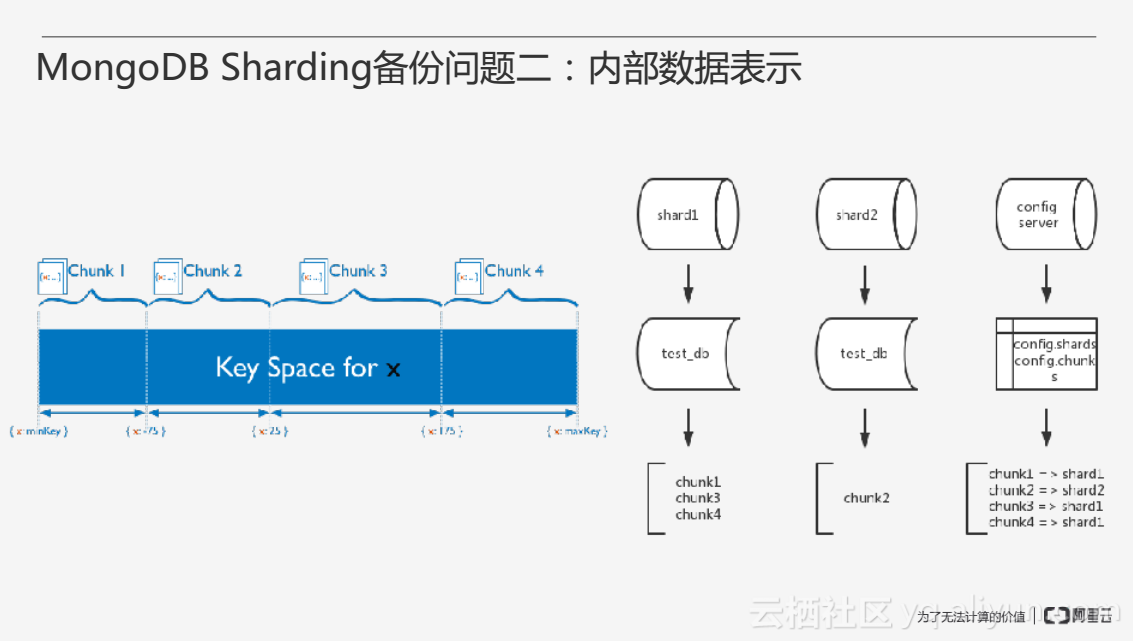
第二個備份問題是關於內部資料的修改,在叢集內部通常會有資料的遷移,上圖展示了MongoDB Sharding內部資料的一些表示,在做Sharding時通常需要指定一個Shard Key即分片的片鍵,接下來的資料將會按照Shard Key的大小範圍進行分佈,例如選擇使用雜湊分片,按照Shard Key雜湊之後的結果作為分佈。Chunk是Shard Key一部分範圍所對應值的集合,例如上圖左側分為4個Chunk,分別對應Shard Key的不同取值範圍。上圖右側Chunk作為一個基礎的單元在不同的Shard之間進行分佈,config server存放著元資料。
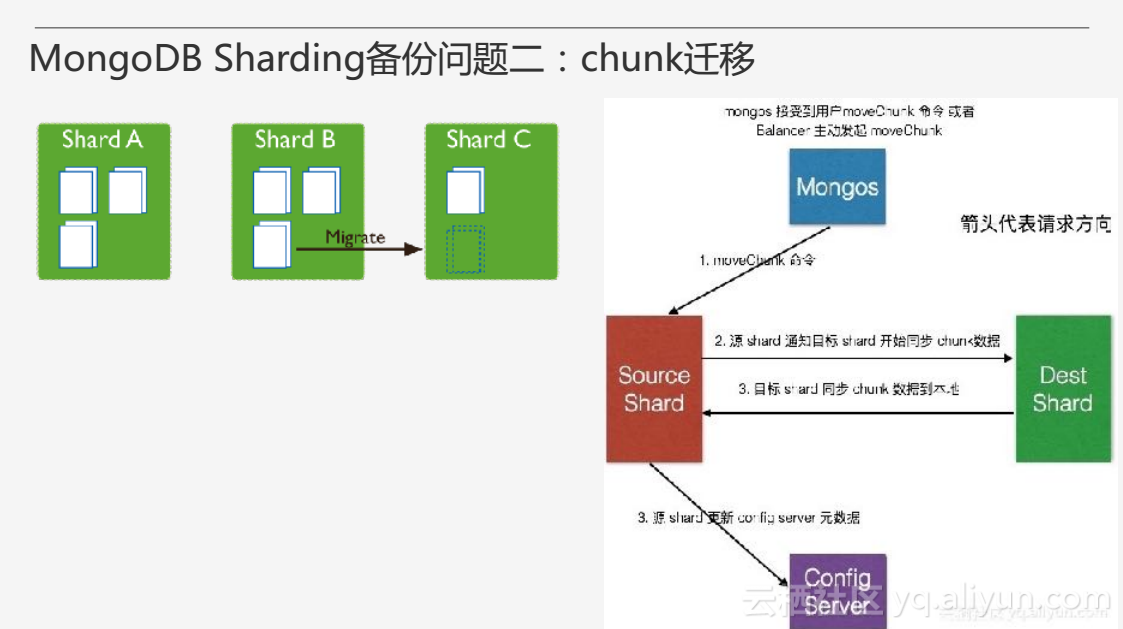
由於對叢集進行擴容的需要,增加或刪除Shard需要MongoDB Sharding進行資料遷移,同時資料分佈不均時也會自發地進行資料遷移,而MongoDB可以決定是否採用資料遷移。上圖右側即為Chunk遷移的基本過程。
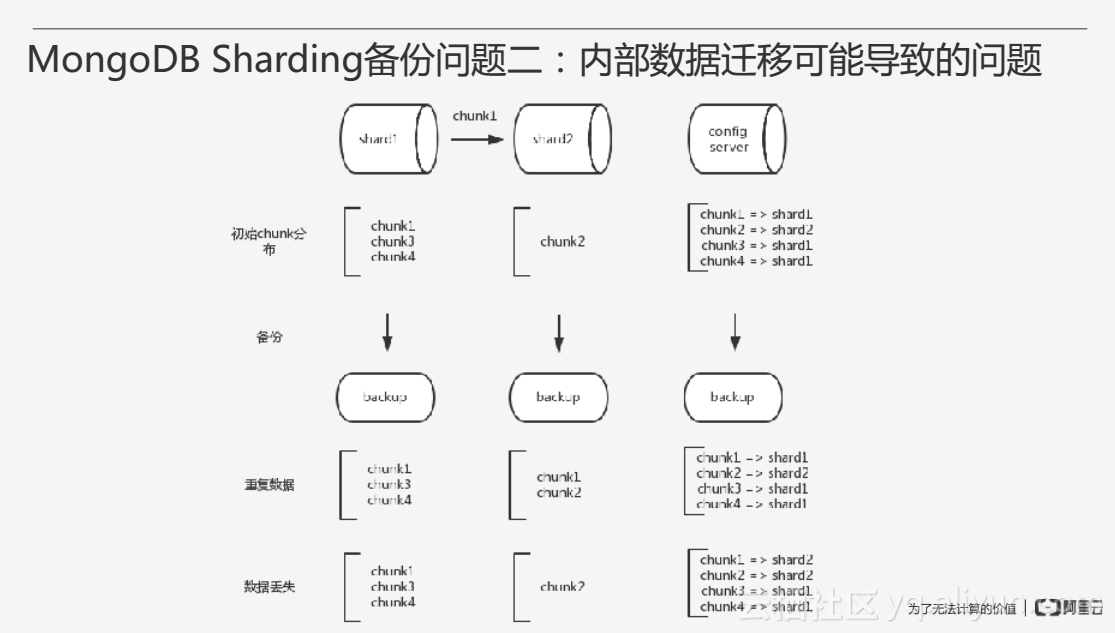
如上圖所示,兩個Shard上的Chunk不均衡,Chunk1需要從Shard1遷移到Shard2上,當所有的節點備份結束時,Chunk1的遷移可能還沒有結束,同時config server上還是原來的資料分佈,此時Shard1仍存在三個Chunk,而Shard2儲存部分Chunk1,由於資料恢復是以config server為基準,決定去哪裡訪問Chunk資料,所以會認為Shard2拷貝了多餘的Chunk1資料產生資料重複。另外一種情況,備份結束後config server已經更新了路由資訊,確認Chunk1已經在Shard2上,但是Shard2中的Chunk2資料還沒有完全拷貝完畢,資料恢復時會發現會有一部分的Chunk2資料丟失。綜上所述,Chunk遷移可能導致資料的重複與丟失問題。
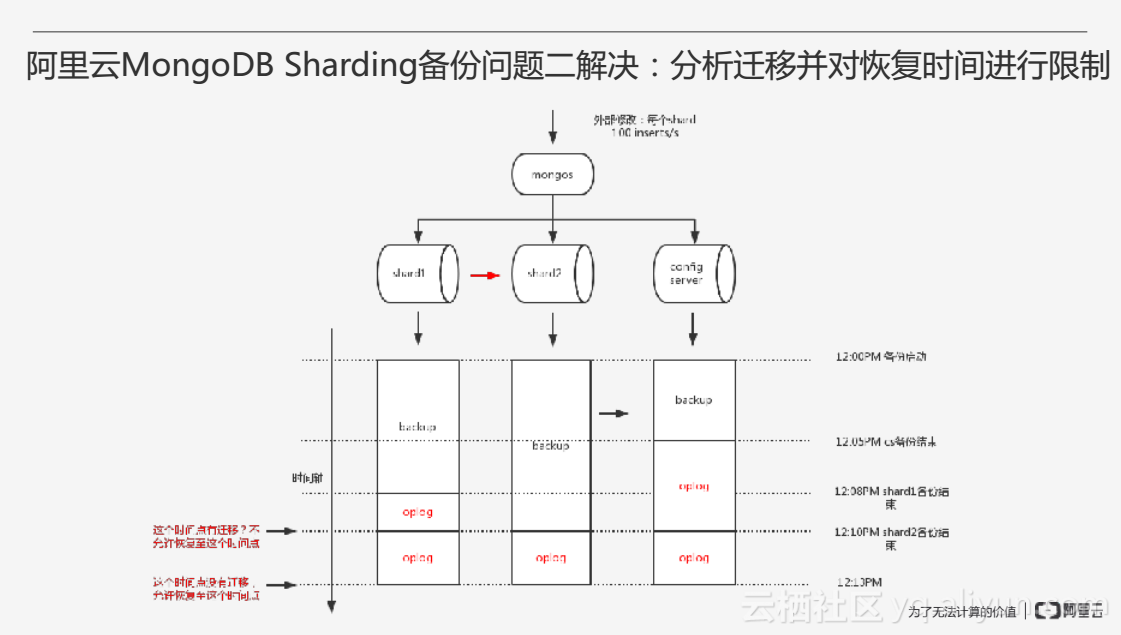
針對問題二,阿里雲會對內部的Chunk遷移進行分析,然後對恢復的時間點進行限制避開有資料遷移的時間段,只有這個時間點沒有資料遷移才允許恢復至這個時間點。
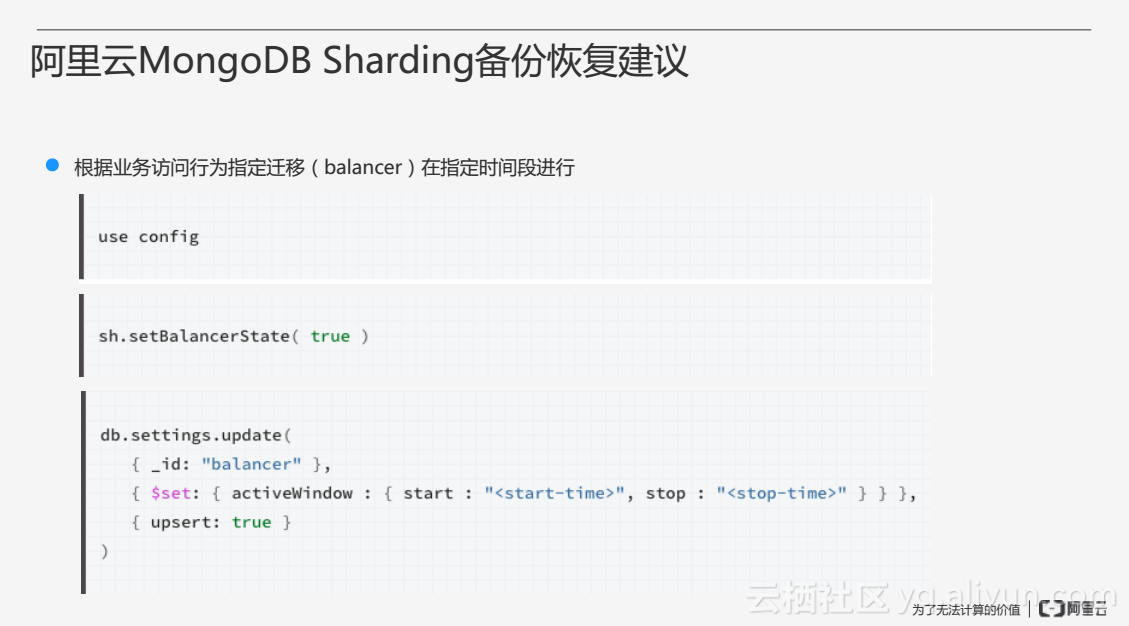
為了解決以上問題,使用者在MongDB Sharding備份時可以配置一個遷移的時間段,即使用者可以根據業務訪問行為指定遷移在哪段時間進行,從而保證遷移在預期時間段內進行,其它時間段可以進行備份恢復。可以通過上圖中的三段程式碼配置遷移的時間點。
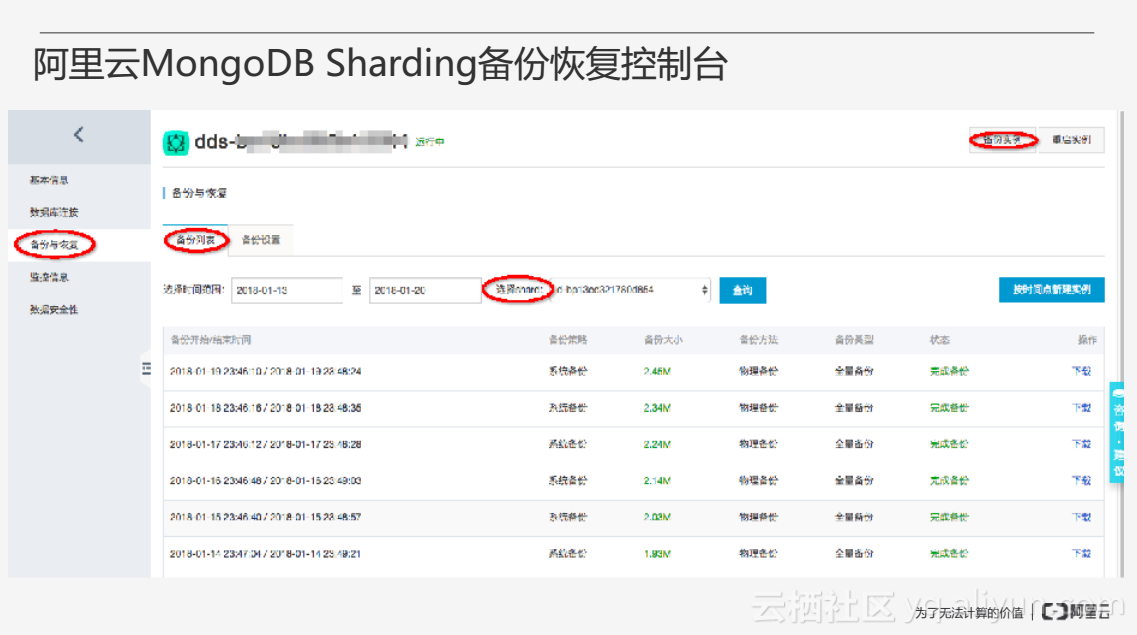
上圖為阿里雲MongoDB Sharding備份恢復的控制檯,與備份列表介面相比多了選擇Shard的功能,可以選擇某一個Shard檢視備份情況。
虛懷若谷——阿里雲MongoDB物理熱備份恢復
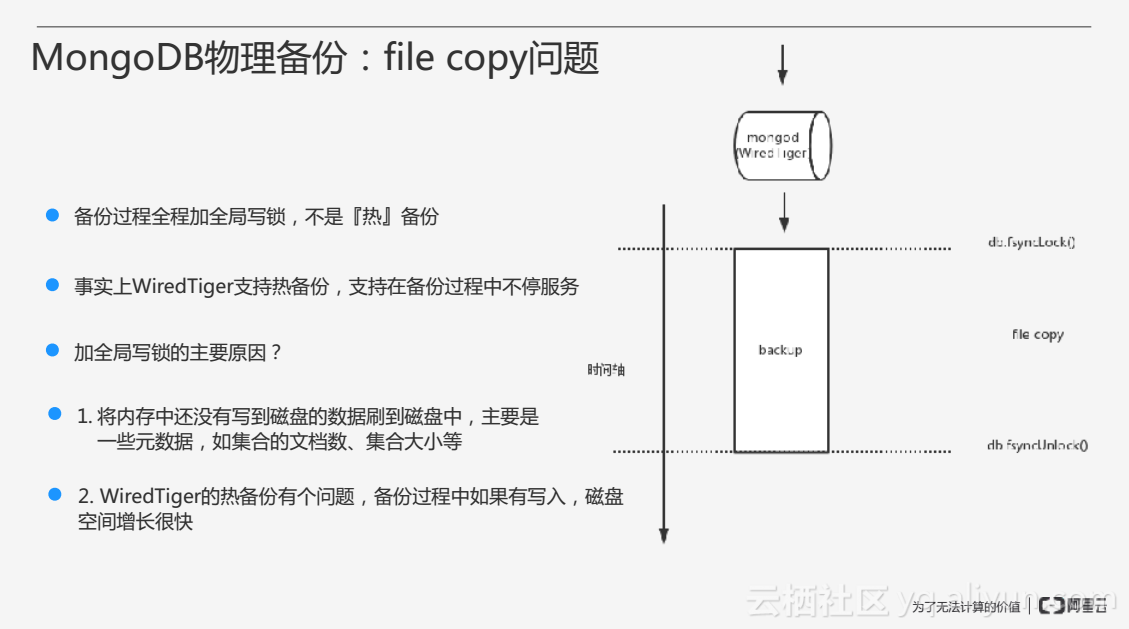
上文提到,通過檔案拷貝做物理備份時,備份過程全程加全域性寫鎖,不是熱備份,在這段期間MongoDB是無法正常訪問的。事實上WiredTiger儲存引擎支援熱備份,支援在備份過程中不停服務,為什麼還要在MongoDB上加全域性寫鎖呢?其一MongoDB會在記憶體當中維護一些資料,需要通過fsyncLock把一些元資料刷到磁碟當中;其二WiredTiger的熱備份有個問題,如果在備份的過程當中有寫入,磁碟的空間增長得比較快。
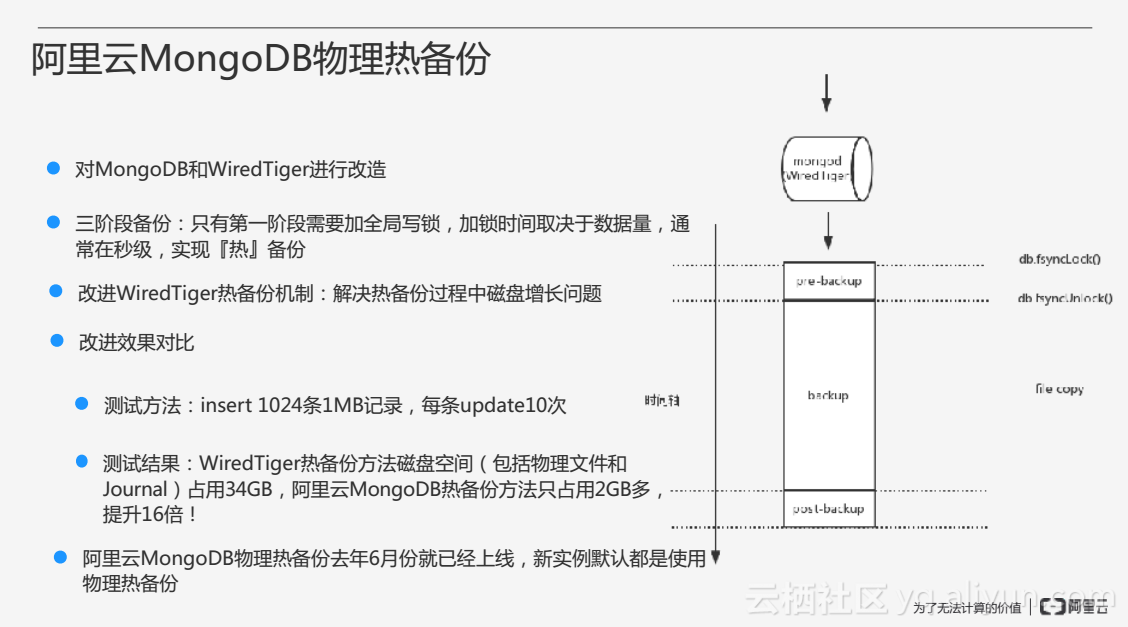
阿里雲針對以上問題對MongoDB和WiredTiger進行了改造,抽象了三個階段的備份過程,在備份之前加入了預備份步驟,在備份之後加入了post-backup動作,並且只需要在預備份階段加入全域性寫鎖即可。同時阿里雲改進了WiredTiger的熱備份機制,解決了熱備份過程中磁碟增長太快的問題。阿里雲MongoDB物理熱備份的方法在去年6月份就已經上線,目前的新例項也預設使用熱備份方式。
閱讀原文http://click.aliyun.com/m/41118/